对抗知识焦虑,从看懂这条开始
App 下载
给机器人换生成式大脑,解决不会举一反三的难题
物理规律建模|机器人动作系统|VLA模型|生成式原生大脑|眸深智能|AI智能体|人工智能
想象一下:仓库里的机器人昨天还能精准分拣包裹,今天货架挪了半米,它就对着空出的位置反复机械操作,彻底懵了。这不是科幻片里的玩笑,而是当下多数机器人的真实困境——它们像背熟了标准答案的考生,换个题型就彻底失灵。这种「不会举一反三」的尴尬,源于主流VLA(视觉-语言-动作)模型的天生缺陷:从语言模型改造而来的架构,面对物理世界的千变万化,就像用钢笔去拧螺丝,怎么都不对味。直到2025年,上海的眸深智能拿出了另一条路:给机器人造一个从物理规律里长出来的「生成式原生大脑」。
把动作拆成「词汇」,让机器人学会「造句」
你可以把传统机器人的动作系统理解成一本只有固定句式的小册子——它只会做训练过的动作,遇到新场景就只能翻书找答案,找不到就卡壳。而眸深智能的核心技术MotionGPT,相当于给了机器人一本「动作词典」和一套「语法规则」。
这套技术的关键是「动作基元」:把人类和机器人能做出的所有复杂动作,拆解成上千个像「抓取」「平移」「旋转」这样的基础元素,就像语言里的单词。模型不需要记住每一个完整动作,只需要学会怎么根据指令把这些「单词」重新组合成新动作。比如让它「把红色盒子放到货架第三层」,它会自动调用「识别红色物体」「抓取」「移动到货架位置」「调整角度放下」这几个动作基元,组合成从未训练过的完整动作序列。
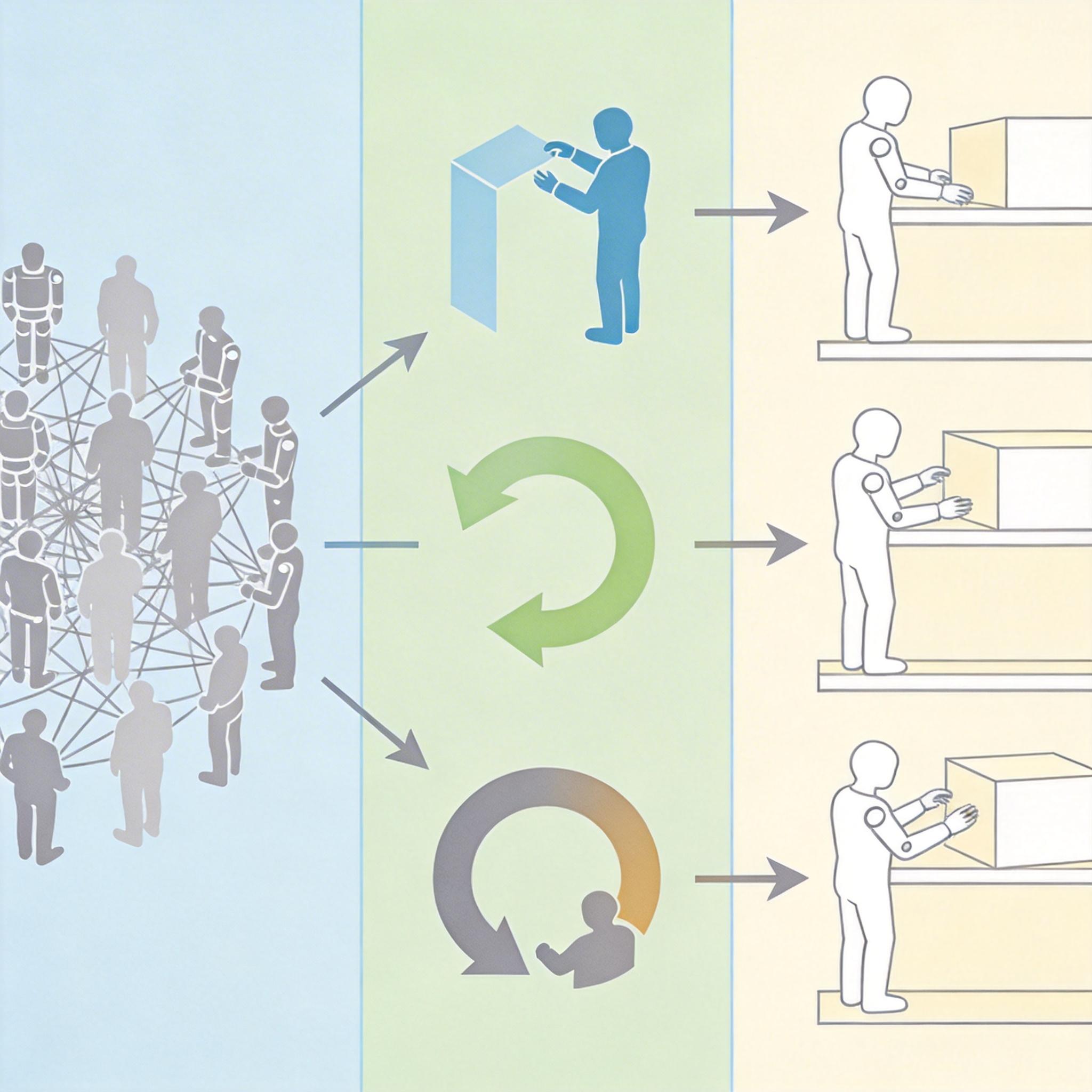
为了喂饱这个「动作大脑」,团队还设计了三段式训练法:先用90%的互联网视频让模型看懂通用运动规律,相当于看几百万个生活片段学常识;再用仿真数据微调适配机械结构,就像在模拟训练场练动作;最后只用极少量真机数据校准,好比上场前的最后彩排。这种方式把数据成本降到了传统方法的十分之一,却让机器人的动作泛化能力提升了80%——它终于能像人一样,「看会一件事,学会一类事」。

把百亿参数模型,压缩到机器人芯片里
解决了「会不会举一反三」的问题,下一个难关是「能不能实时反应」。百亿参数的大模型跑在云端或许轻松,但机器人的端侧芯片算力有限,就像让超级计算机塞进手表里,不仅慢,还随时可能断电。
眸深智能的MADTP++动态令牌剪枝算法,就是给大模型做了一套「智能省电模式」。它能像人脑一样,只调动当前任务需要的那部分参数——比如做简单抓取时,就不用启动处理复杂环境感知的模块;遇到动态避障时,再快速唤醒对应的算力。这套算法能把模型体积压缩到原来的1/8,推理速度提升10到20倍,让百亿参数的大模型能在普通机器人的端侧芯片上流畅运行,延迟控制在人类感知不到的范围内。
更重要的是,这个「大脑」能实现端侧闭环学习——机器人在干活的时候,能边做边学,把新遇到的场景和动作自动补进自己的「词典」里。比如第一次遇到表面光滑的瓶子抓滑了,它下次就会自动调整抓取的力度和角度,不需要人类再重新训练模型。这种「边干边学」的能力,才是机器人能真正走进复杂现实场景的核心。
不做机器人,只做机器人的「操作系统」
在多数团队还在纠结做什么形态的机器人时,眸深智能已经想清楚了自己的定位:做具身智能时代的Windows。就像PC时代微软不做电脑只做系统,他们要给所有形态的机器人提供通用大脑——不管是工业机械臂、物流AGV,还是家庭陪护机器人,都能插上这个「大脑模组」就拥有智能。
这种定位让他们在商业化上格外克制:只和千亿级产业龙头合作,只接万台以上规模的订单,只碰国家重大需求的项目。成立第一年,他们就拿到了宇树科技、小米等头部客户的订单,去年确认了3000万元收入,今年预计能翻一番。
我认为,这种「克制」恰恰是他们的优势。当前具身智能行业的最大陷阱,就是为了炫技做一堆只能在实验室里跑的Demo,却忽略了真实场景里的续航、寿命、成本问题。而眸深智能从一开始就盯着「能落地的智能」,用工业物流和家庭养老这些容错率高、需求明确的场景做试验场,一步步把技术优势变成商业价值。
当我们谈论机器人的未来时,我们谈论的从来不是更精密的机械臂,而是更灵活的「大脑」。一个从物理规律里生长出来的生成式原生大脑,能让机器人从「执行指令的工具」,变成「能理解环境的合作者」。
未来的某一天,你可能会看到:工厂里的机械臂能自动适应不同批次的零件,家里的陪护机器人能记住老人的行走习惯调整辅助力度,甚至不同品牌的机器人能组队完成复杂任务——它们用的可能是不同的身体,但装的是同一个「大脑」。
智能的终极形态,是学会适应变化。