对抗知识焦虑,从看懂这条开始
App 下载
AI编程得分暴跌:补丁工离工程师还差三道坎
代码重构|软件工程考题|AI编程能力|GPT-5.4|Scale AI评测|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载代码重构|软件工程考题|AI编程能力|GPT-5.4|Scale AI评测|大语言模型|人工智能
当所有人都在惊叹AI写代码的速度时,一份来自Scale AI的评测给行业浇了盆冷水:在284道由资深工程师出的真实软件工程考题里,当前最强的GPT-5.4单次通过率仅43.49%,三次全对的概率直接腰斩到29.2%。更扎心的是,AI修bug的能力一骑绝尘,但在读代码、写测试、做重构这些工程师真正的日常工作上,几乎全员翻车。这不是某款模型的失误,而是整个AI编程领域的集体照妖镜——我们一直以为AI正在替代程序员,可实际上,它们只是优秀的补丁工,离合格工程师还差着十万八千里。
过去两年,AI写代码的叙事被反复刷新:从OpenHands到SWE-Bench,每一次榜单更新都伴随着“AI替代程序员”的喧嚣。但所有这些评测,都在做同一件事——修bug和加功能。而真实世界里的软件工程,远远不止这两件事。 一位工程师的日常,是对着陌生代码库啃一下午文档,是为新功能写能覆盖边界场景的测试,是把十年前的祖传代码拆成可维护的模块,是debug一个只在生产环境出现的诡异报错。这些上游和下游的能力,被所有主流评测集体无视了。 Scale AI推出的SWE Atlas,就是要补上这块盲区。这套评测体系包含三大核心任务:124道代码库问答,考验AI理解陌生系统的能力;90道测试编写,看它能不能像专业测试工程师一样精准覆盖风险;70道代码重构,要求它在不改变功能的前提下优化代码结构。所有题目都来自真实开源项目,由资深工程师手写,每道题平均有10到18条评分细则——不再是简单的“通过/不通过”,而是像代码评审一样,从边界覆盖、代码健康到文档同步逐一打分。
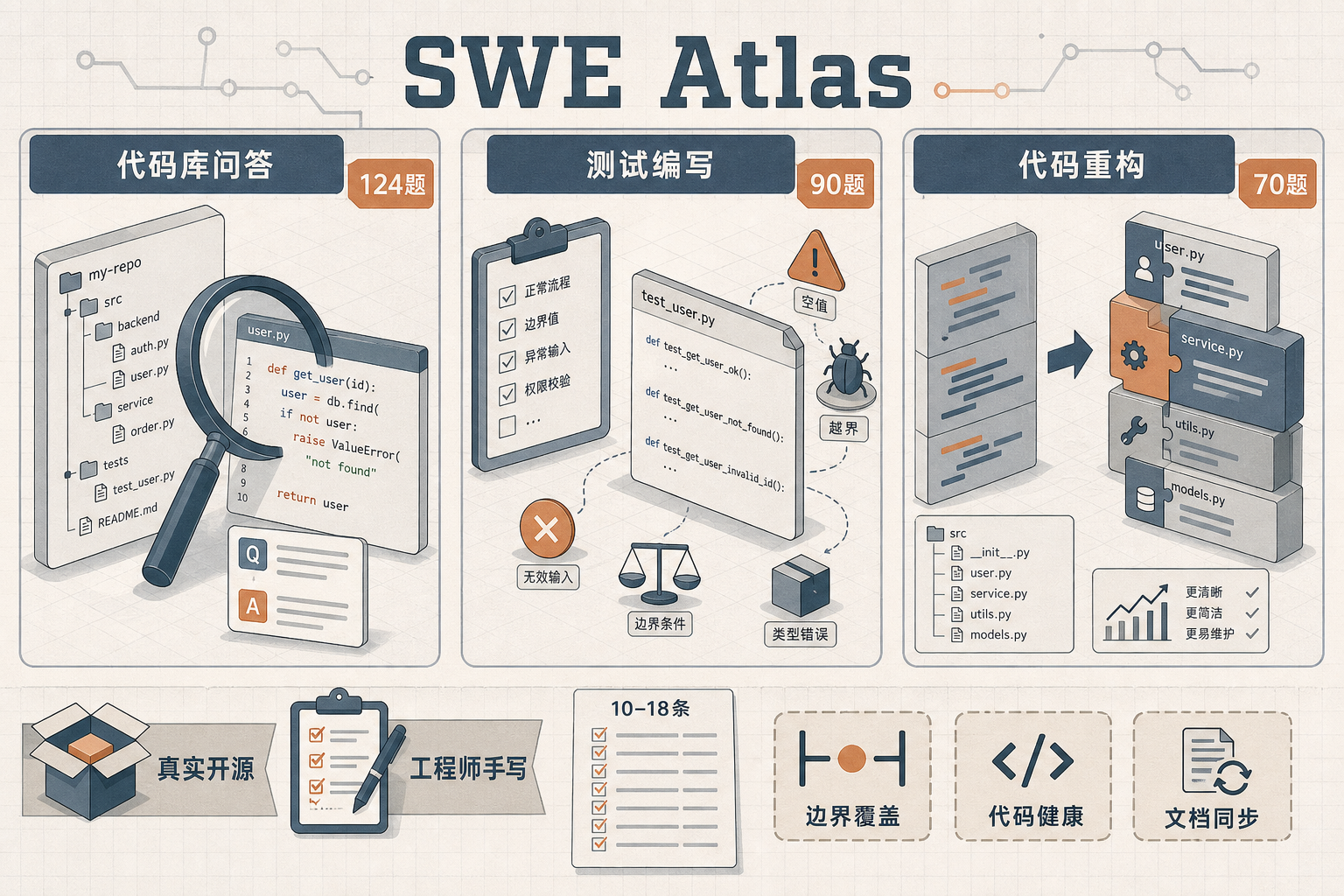
评测结果让所有人大跌眼镜:前沿模型集体掉档,Pass@1最高仅43.49%,三次全对的比例直接下降30%到50%。更关键的是,AI在“补丁工”的领域表现出色,但在“工程师”的核心能力上,几乎全员不合格。 在测试编写任务中,模型能写出看起来能跑的测试套件,通过变异测试的比例普遍超过60%,但一旦用专业评审标准打分,分数立刻被腰斩。原因很简单:它们写的测试只验证“函数应该做什么”,从不考虑“函数不该做什么”,更不会去覆盖那些细微的边界场景。比如为一个金额计算函数写测试,AI会测正常数值的相加,却不会测负数、零值或者超出精度范围的输入——而这些恰恰是生产环境中最容易出问题的地方。 重构任务的差距更夸张:如果只看功能是否正常,每个模型的得分都能高达60%到80%,但一旦用评审标准衡量,分数直接砍半。AI能做到表面上的代码整洁,却不会清理旧的函数定义,不会修正反模式,更不会同步更新文档。就像给旧房子刷了层新漆,看起来光鲜亮丽,地基里的裂缝却依然存在。

最能体现差距的是代码库问答任务。得分最高的模型,不是在静态读代码,而是会像人类工程师一样,把代码跑起来,发请求,看运行时日志,通过动态分析理解系统。而表现差的模型,只会对着静态代码瞎猜,甚至编造不存在的函数和逻辑。
SWE Atlas的出现,给整个AI编程行业重新校准了标尺。过去我们只关心AI能不能写出能跑的代码,现在我们终于开始关注,AI能不能写出“好”的代码——可维护、可扩展、符合工程规范的代码。 第三方评测机构Artificial Analysis已经把SWE Atlas纳入了Coding Agent Index,作为衡量AI编程能力的三大核心评测之一。即便是当前榜首的Cursor CLI + Claude Opus 4.7组合,综合得分也仅有61分,整个榜单的顶尖系统都聚集在40到60分区间,无一突破70分。这意味着,AI离真正接管工程师的工作,还有很长的路要走。 但这并非坏消息。SWE Atlas的出现,让行业终于从“AI替代程序员”的虚幻叙事中清醒过来,开始聚焦真正有价值的方向:如何让AI理解复杂系统,如何让AI写出高质量的测试,如何让AI参与长期的代码维护。这些能力的提升,才是AI编程真正的未来——不是替代工程师,而是成为工程师的可靠伙伴。
当我们谈论AI替代程序员时,我们其实混淆了“写代码”和“软件工程”的边界。写代码只是工具,软件工程是构建、维护和演化系统的艺术。AI可以成为优秀的工具使用者,但要掌握这门艺术,它还需要学会理解系统的上下文,学会为未来的维护负责,学会像工程师一样思考。 补丁工修当下,工程师顾长远。这不仅是AI需要跨越的三道坎,也是整个行业需要重新审视的核心命题。毕竟,好的软件不是写出来的,是维护出来的——而这,恰恰是AI目前最欠缺的能力。