对抗知识焦虑,从看懂这条开始
App 下载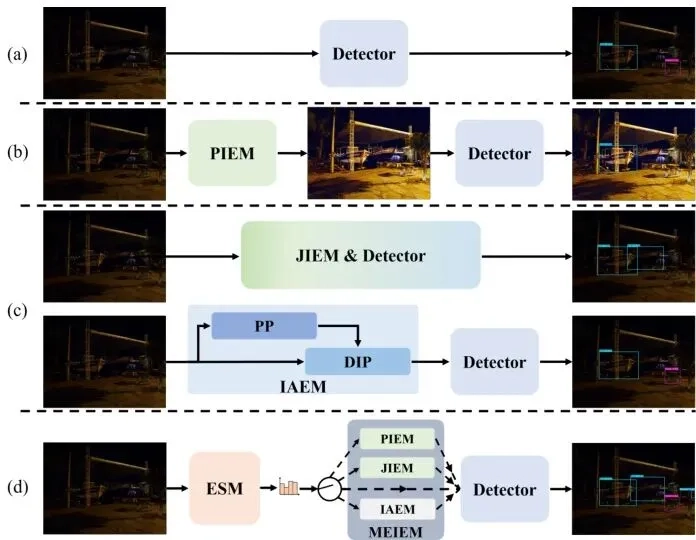
暗光检测不再瞎:多专家AI按需挑方案
图像识别算法|自动驾驶夜视|暗光环境检测|四川大学团队|AMIEOD框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像识别算法|自动驾驶夜视|暗光环境检测|四川大学团队|AMIEOD框架|多模态视觉|人工智能
深夜的街头监控画面里,一个模糊的身影闪过——系统要么把它当成垃圾袋漏检,要么错标成路人;自动驾驶的夜间摄像头,对着路边的警示牌反复犹豫,直到距离过近才紧急制动。这些场景里,AI的表现像个高度近视的人:白天视力1.5,到了光线不足的地方直接降到0.1。
为什么会这样?因为绝大多数AI检测模型都是在“晴天白日”的数据集里训练出来的,一旦遇到昏暗、逆光、阴影这些“特殊路况”,就彻底抓瞎。直到四川大学的团队拿出了AMIEOD框架:它不靠单一的“提亮滤镜”,而是让三个各有所长的AI“美容师”协同工作,还能自动给每张暗图选最合适的那个。结果是,极暗环境下的检测准确率比当前最优方法再提2.4%,而且几乎不耽误速度。
你可以把低照度图像的问题分成三类:有的是全黑一片缺亮度,有的是局部逆光对比度差,还有的是暗部细节全糊成一团。传统方法就像给所有病人开同一种感冒药,管不管用全看运气。
AMIEOD的思路是组建一个“专家天团”:第一个专家是预训练的SCI模型,就像急诊室的全科医生,能快速把暗图的整体亮度拉起来,稳定不出错;第二个专家是和检测器联合训练的“定制师”,它不管图像好不好看,只盯着能不能让检测器更容易认出目标,比如把模糊的车牌边缘特意强化;第三个专家是“细节控”,它会逐像素分析图像的亮度、颜色,给暗部加对比度,给过曝的地方压光,连阴影里的小物件都能抠出来。

这三个专家不是各自为战,训练时会通过一种“检测导向回归损失”互相学习:先找出当前检测效果最好的那张增强图,另外两个专家的输出都向它靠拢,既保留各自的特长,又统一服务于“让检测更准”这个目标。
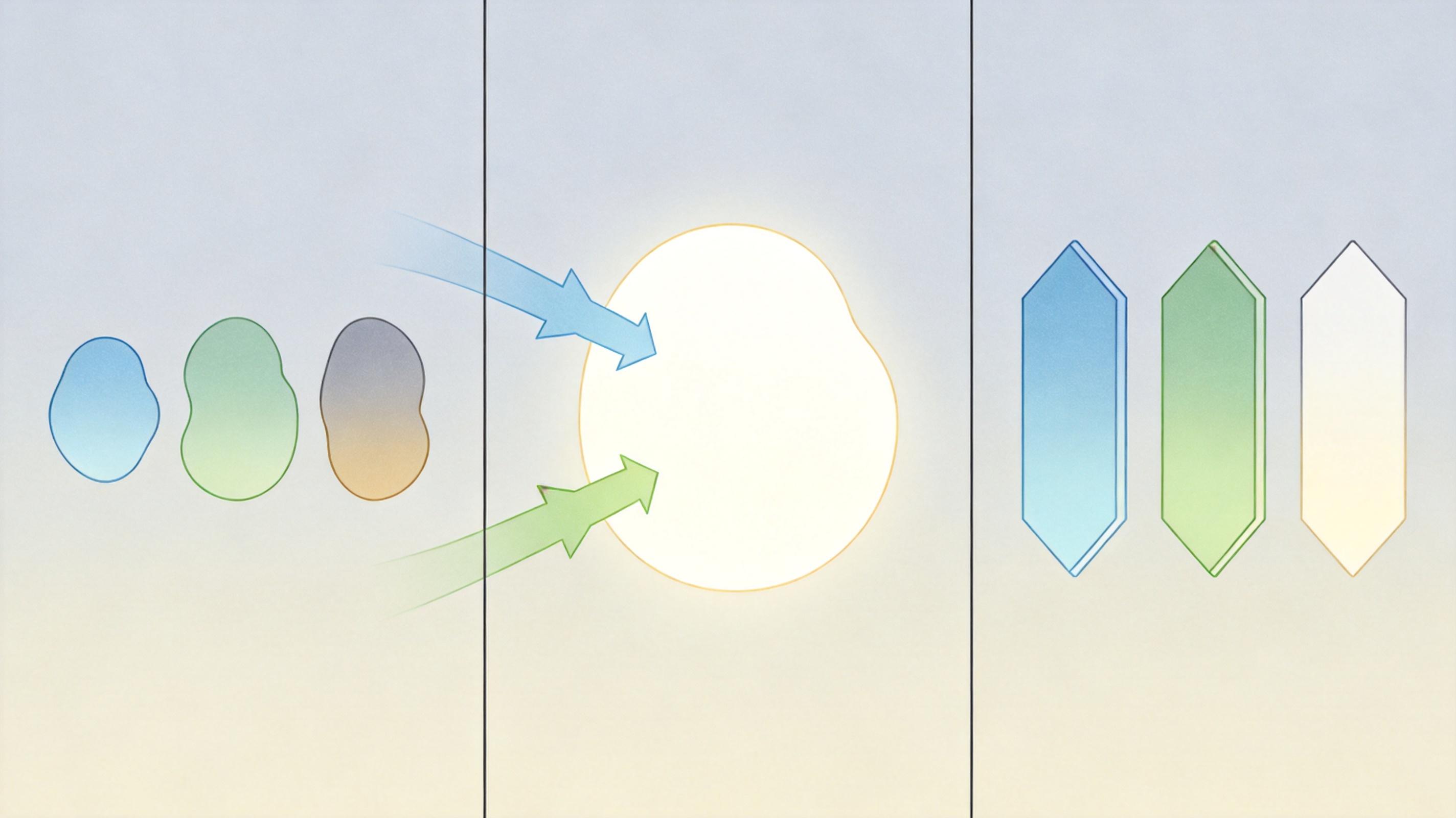
三个专家一起干活,推理时总不能每张图都跑三遍再选最优——那样速度会慢到没法用。AMIEOD的第二个核心,就是训练了一个轻量级的“调度员”ESM。
这个调度员只有一个ResNet50加全连接层,它会先把输入图像缩小到256×256,快速提取全局特征:是全黑的夜景?还是逆光的路口?还是室内的低对比度画面?然后直接输出四个分数——三个专家各一个,加上原图不用增强的选项。分数最高的那个,就是当前图像的“最优解”。
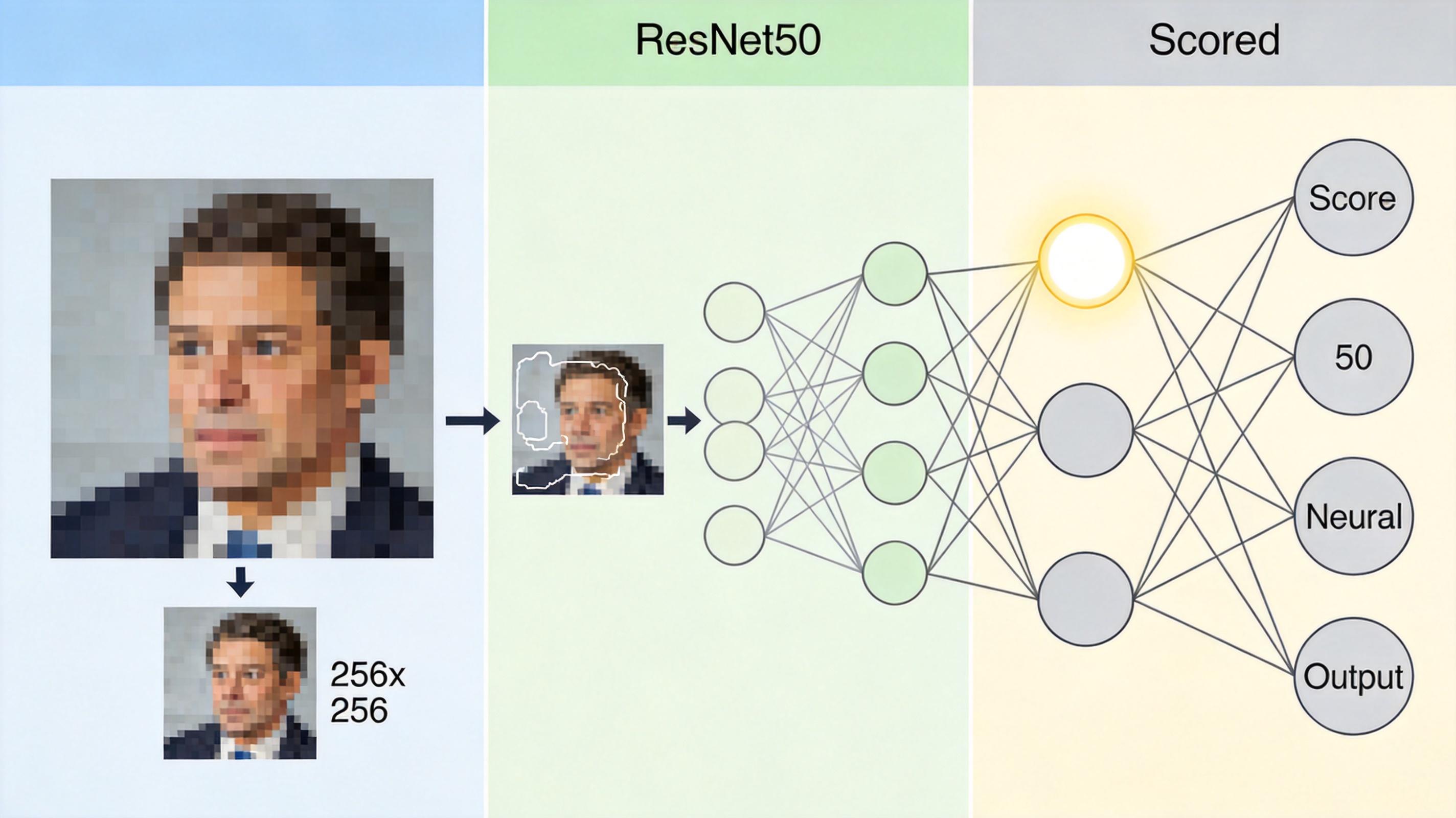
训练调度员的方法很聪明:先用第一阶段训练好的三个专家和检测器,给每张图跑一遍,找到检测损失最低的那个专家作为“标准答案”,再让调度员学习“看一眼图就认出标准答案”。这样训练出来的调度员,判断准确率极高,而且整个过程只需要30个epoch就能收敛。
推理时,调度员的判断只需要几毫秒,然后只运行选中的那个专家,再进检测器。最终的结果是,AMIEOD的推理速度能达到96 FPS,只比纯YOLOv3慢了6%,但准确率却提升了5.6个百分点。
当然,AMIEOD也不是没有局限。比如它的调度员是和特定检测器绑定的,如果换了YOLOv8或者Transformer检测器,就得重新训练调度员;极端暗光下,比如几乎全黑的地下车库,三个专家的增强效果都会打折扣,还是会出现漏检;而且多专家的结构虽然参数量增加不多,但训练时要跑两个阶段,比单一模型麻烦一些。
但它最值得肯定的,是跳出了“用一个模型解决所有问题”的思维定式。过去的低照度检测,要么在增强上死磕,要么在特征提取上硬扛,而AMIEOD把问题拆成了“多方案覆盖”和“自适应选优”两部分——这刚好击中了低照度场景的核心痛点:光线条件太杂,没有万能解,只能按需匹配。
实验数据也证明了这一点:在Exdark数据集上,AMIEOD的mAP达到82.1%,比之前最好的EMV-YOLO高出2.4个百分点;在人脸检测数据集Darkface上,mAP提升了3.3%;甚至能检测出数据集中一些没标注的暗部目标——那些人类标注员可能都没注意到的细节,AI反而找出来了。
我们总说AI要适应真实世界,但真实世界从来不是标准化的:它有深夜的暴雨街头,有背光的楼道拐角,有光线忽明忽暗的工厂车间。AMIEOD的价值,不在于它把暗光检测的准确率提了几个百分点,而在于它提供了一种思路:与其让AI在单一模型里死磕“全能”,不如给它一套“工具箱”,让它学会自己选工具。
好的AI,不是解决所有问题,而是适配每个场景。 未来的视觉AI,可能不会是一个无所不能的超级模型,而是一群各有所长的专家,加上一个聪明的调度员——就像一支配合默契的团队,在复杂多变的真实世界里,把每一件事都做对。