对抗知识焦虑,从看懂这条开始
App 下载
激活3亿参数,打赢31亿参数模型
多模态推理|代码生成|参数高效模型|稀疏激活|混合专家架构|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载多模态推理|代码生成|参数高效模型|稀疏激活|混合专家架构|大语言模型|人工智能
当谷歌拿出31亿参数的密集模型时,没人想到它会被一个只激活3亿参数的对手挑落马下——后者的总参数虽有35亿,却像一支只派出精锐小分队的集团军,用1/10的计算量,在代码生成、多模态推理等核心任务上全面领先。这不是算力的胜利,是对“大模型必须堆参数”这个惯性思维的一次精准破局。
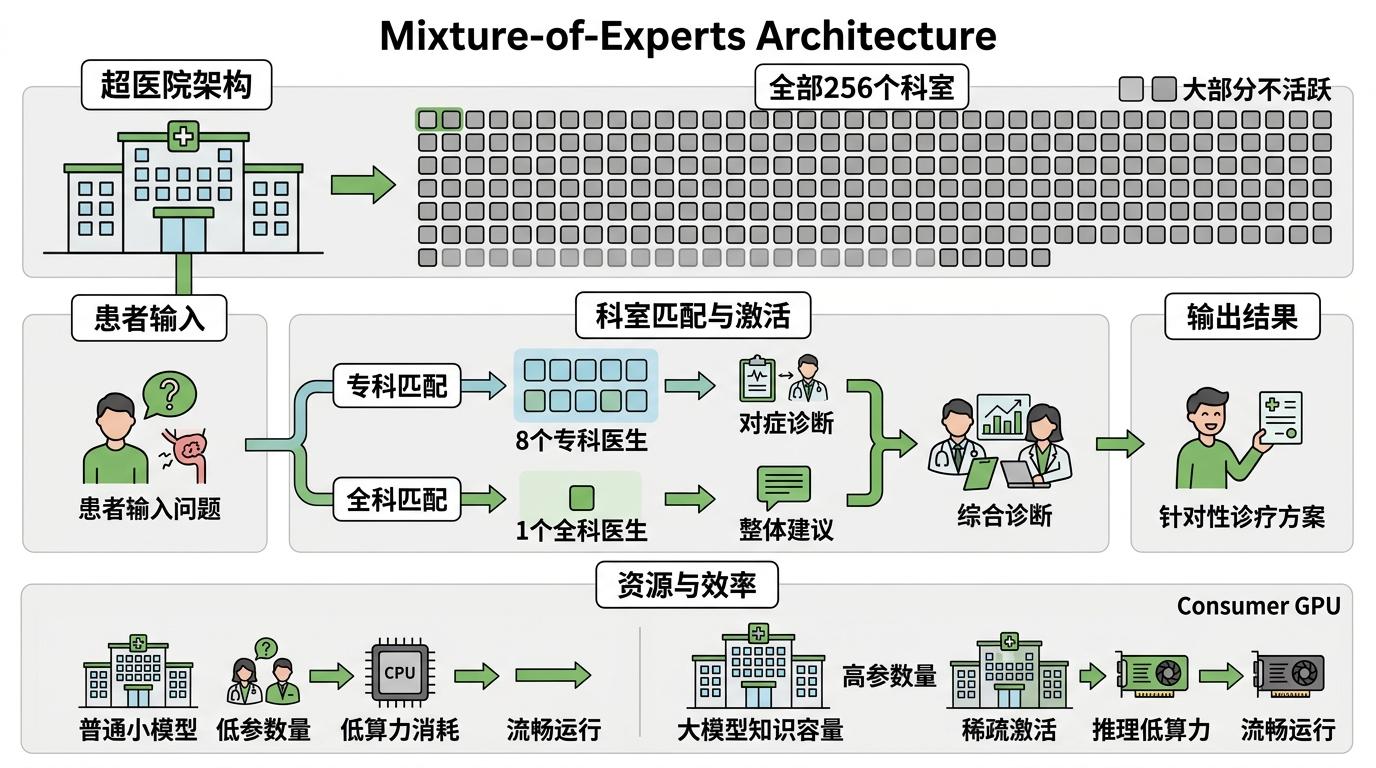
这场以小胜大的关键,藏在稀疏激活的混合专家架构里。你可以把它想象成一个拥有256个科室的超级医院,每个患者输入进来,系统只会匹配最对症的9个科室——8个专科医生加1个全科医生,其余247个科室全程待命不占资源。这种“按需调用”的设计,让模型总参数保持了大模型的知识容量,实际推理却只消耗小模型的算力,甚至能在普通消费级GPU上流畅运行。
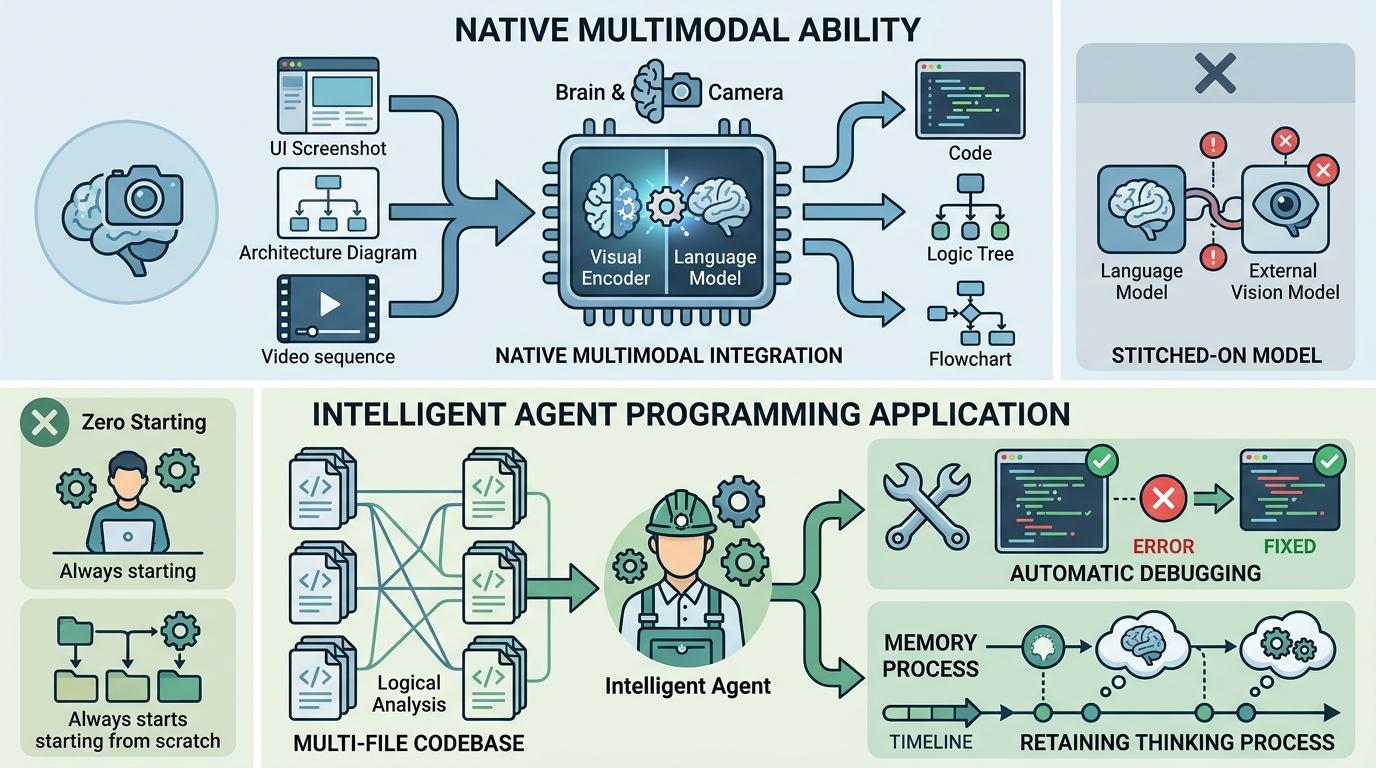
更值得注意的是它的原生多模态能力。不同于需要额外外挂视觉模型的“拼接式”多模态,它的视觉编码器和语言模型从底层就长在一起,能直接看懂UI截图生成前端代码,能对着架构图拆解工程逻辑,甚至能理解视频里的操作流程。这种原生融合的优势,让它在智能体编程场景里成了香饽饽——它能像人类工程师一样,对着多文件代码库梳理逻辑,调用测试工具自动排错,还能记住之前的思考过程,不用每轮都从零开始。
开源的选择让这波技术突破的影响被放大了百倍。以往只有大厂能玩得起的高效大模型,现在中小企业甚至个人开发者都能本地部署,不用再担心数据隐私,不用再为API调用成本发愁。这相当于把原本锁在实验室里的高端工具,直接放到了每个开发者的工具箱里,而不是只提供一个付费使用的云端接口。
但它也并非没有短板。稀疏架构的专家路由容易出现负载不均,部分“热门专家”会被反复调用导致过载,而“冷门专家”则可能长期闲置;超长上下文处理虽能hold住百万级token,却对内存管理提出了极高要求。这些问题不是技术终点,而是下一轮效率竞赛的新起点。
从全球AI生态的角度看,这是中国开源模型在效率赛道上的一次卡位。当美国大厂还在比拼谁的模型参数更大、训练数据更多时,这边已经转向了“用更少资源做更多事”的计算经济学。这种思路的转变,正在重新定义大模型的性价比,也让全球AI生态从少数玩家的军备竞赛,转向了更普惠的技术扩散。
算力不是AI的未来,效率才是。当我们不再用参数规模定义模型的强弱,而是用“每单位算力能解决多少实际问题”来衡量时,真正的AI普惠时代才会到来。