4 个月前
4 个月前
通用人工智能(AI)的浪潮席卷全球,似乎无所不能。然而,当聚光灯从闲聊问答转向毫厘必争的心脏手术台,一个尖锐的问题浮出水面:当生命悬于一线时,我们能将决策权交给一个“博学”却可能“凭空想象”的通用大模型吗?
最近,一场在AI医疗领域的“巅峰对决”给出了一个震撼性的答案。由空军军医大学唐都医院李妍教授团队与深圳清华大学研究院朱锐团队联合完成的COMPARE研究,将一个专为心脏介入手术(PCI)打造的垂直AI系统——CA-GPT,与强大的通用大模型ChatGPT-5以及初级介入医师,置于同一竞技场。
这场对决的背景是全球每年数百万例的PCI手术。手术中,医生需要借助被称为“第三只眼”的光学相干断层成像(OCT)技术,来观察血管内部的微观病变。然而,OCT图像的解读极度依赖经验,初级医生与资深专家的手术成功率差距可高达40%。
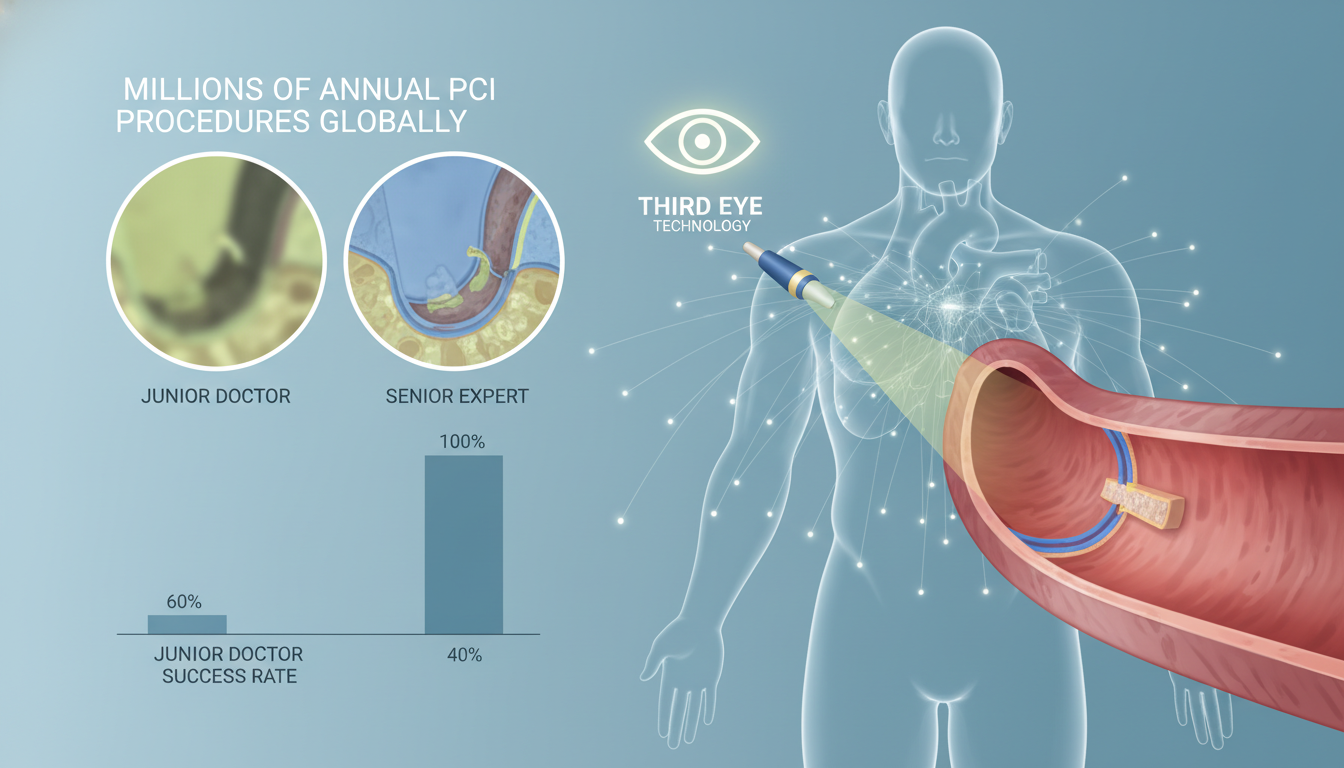
研究结果堪称对通用大模型的“降维打击”:
研究明确指出,ChatGPT-5虽然语言推理能力强大,但在处理精密的医学影像时,缺乏对图像数据的数值敏感性和空间理解力,尤其在面对复杂病变时,容易产生致命的“幻觉”。而CA-GPT则表现出惊人的稳定性,即使在最棘手的病例中也保持了极高水准。
CA-GPT之所以能取得压倒性胜利,其核心在于摒弃了对单一通用大模型的迷信,构建了一套逻辑严密的复合智能体架构。这并非一个简单的聊天机器人,而是一个分工明确的协作系统。
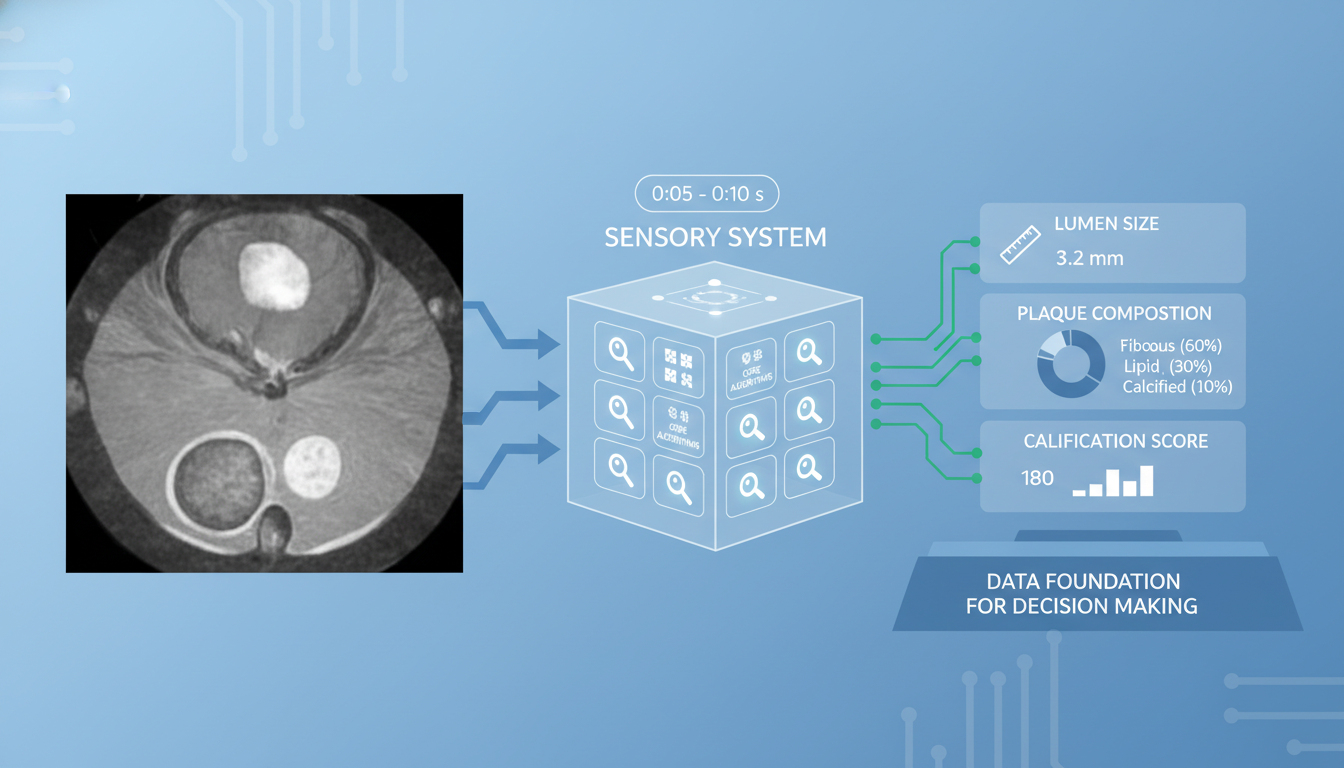
首先,“感官”系统——专有小模型。系统底层集成了13项核心算法,它们如同高倍显微镜,在5-10秒内对OCT影像进行精准的定量分析,将模糊的图像转化为结构化的数据,如管腔尺寸、斑块性质、钙化积分等。这为后续决策提供了坚实、可靠的数据地基。
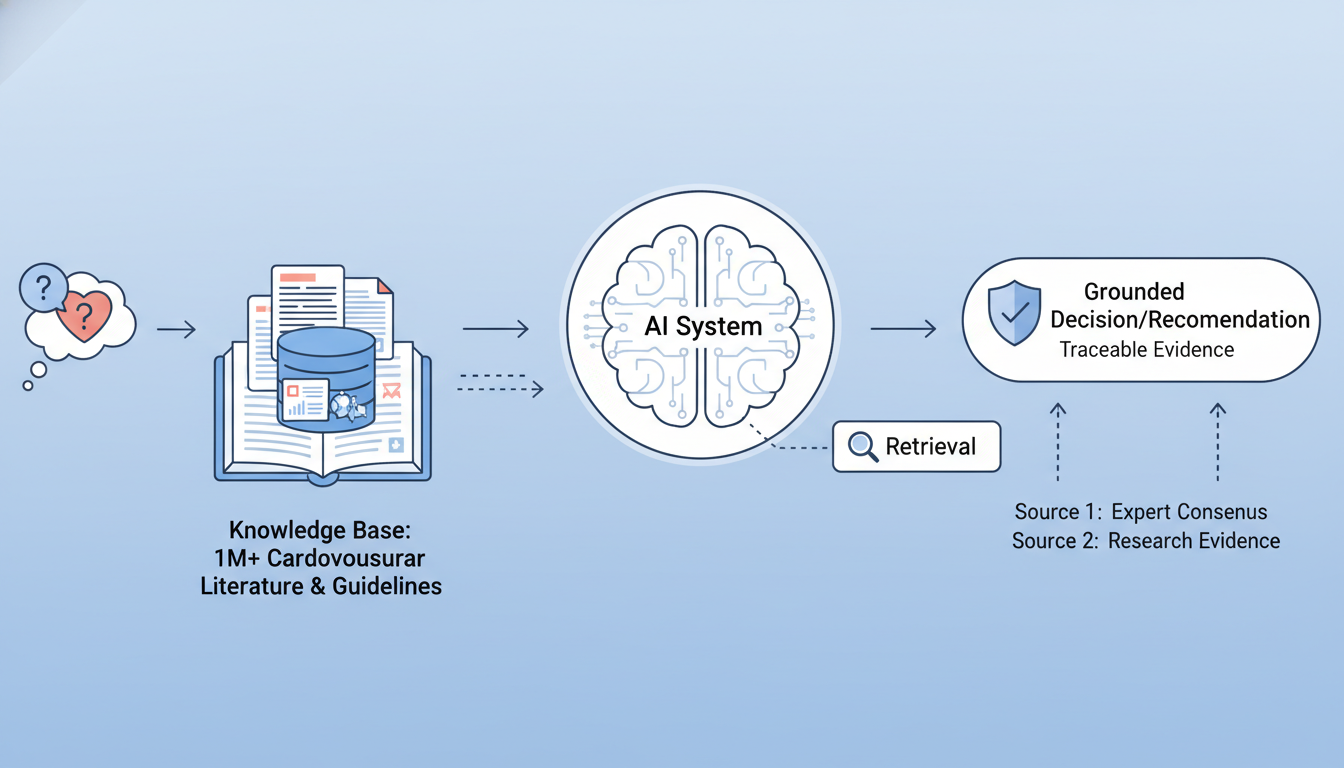
其次,“大脑”系统——基于DeepSeek的逻辑推理。与依赖概率生成文本的通用模型不同,CA-GPT的大模型推理层基于开源的DeepSeek构建,它的任务不是“创作”,而是基于“感官”系统提供的精确数据,进行符合循证医学逻辑的深度推理。
最后,也是最关键的,是**“知识”系统——RAG技术**。通过检索增强生成(RAG)技术,系统实时链接了一个包含超过100万篇心血管文献及最新指南的权威知识库。这意味着,AI的每一次决策建议都有据可查,能够追溯到具体的专家共识或研究证据,从根本上抑制了“AI幻觉”,确保了决策的科学性和安全性。
这场技术胜利的终极意义,远不止于一篇论文或一次算法竞赛。它直面全球医疗领域最严峻的挑战之一:优质医疗资源的极度不均。培养一名能独立处理复杂心脏手术的专家,需要近十年的漫长周期,这使得大量基层和偏远地区的患者无法得到及时、高质量的治疗。
CA-GPT的出现,本质上是在实现“医疗能力的平权”。
试想一个场景:在一家县级医院,一位年轻医生面对一例复杂的血管钙化病变束手无策。此时,CA-GPT系统在数秒内给出了清晰、具体的手术策略建议:
这几乎等同于一位顶级三甲医院的专家,在手术台旁进行“手把手”的实时指导。这不仅是辅助,更是在重塑基层医疗的能力边界,让县域医生也能拥有“顶级专家”的视野和决策水平。
过去,中国医疗器械行业更多是在追赶。而CA-GPT的成功,标志着中国企业和科研机构在高端医疗AI领域,开始从“追随者”转变为“定义者”。它证明了,在医疗这种零容错率的领域,深耕垂直场景,将深度学习的精准度与大模型的推理能力、再结合可追溯的知识体系,才是AI落地的真正坦途。
然而,技术的飞跃也伴随着深刻的伦理拷问。尽管CA-GPT这样的垂直系统通过RAG技术增强了可解释性,但AI医疗的普及依然面临着三大挑战:
CA-GPT的胜利并非宣告机器将取代医生,而是预示着一个“人机共生”新时代的开启。未来的医疗,不再是“不可能三角”(质量、成本、可及性三者无法兼得)的困局。
垂直AI将作为医生的“智能协作者”和“决策伙伴”,承担海量、重复性的数据分析工作,提供基于海量证据的决策支持,从而将医生从繁重的劳动中解放出来,让他们能更专注于最核心、最无可替代的工作——与患者的沟通、复杂情况的综合研判以及人文关怀。
这或许就是中国医疗科技的“DeepSeek时刻”——不再沉迷于通用能力的宏大叙事,而是脚踏实地,用自己的技术,去解决最真实的临床痛点,用精准、可靠、可及的智能,重塑行业的标准与未来。
点击充电,成为大圆镜下一个视频选题!