对抗知识焦虑,从看懂这条开始
App 下载
AI算力抢电背后,算与电的双向革命已启动
能源革命|潮汐式用电|电力系统|智算基地|新能源|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载能源革命|潮汐式用电|电力系统|智算基地|新能源|AI算力|前沿科技|人工智能
当你刷着AI生成的短视频、用大模型写方案时,可能没意识到:支撑这些内容的智算基地,正以一个中小型城市的用电量疯狂吞噬电力。过去接10千伏变压器就能满足的传统数据中心,如今一座大型智算基地要配3个220千伏变电站,训练任务集中时电不够用,空档期又白白浪费。更棘手的是,这种“潮汐式”用电还在爆发式增长——有人预言,未来2年电网将迎来大规模“阵痛”。这早已不是简单的“用电需求上涨”,而是算力与电力两大系统的深层碰撞,背后是一场没人能躲过去的能源革命。
你可以把算力建设想象成开快车,踩油门就能加速;而电力系统像修高速公路,从规划到通车至少要三五年。这对天然的“节奏差”,是所有矛盾的起点。
国家发改委的专家把这种矛盾总结为“时空错配”:AI技术迭代以月为单位,今天刚建好的智算中心,明年可能就因新模型需要扩容;但电网的变电站、输电线路,得按十年甚至更久的周期规划。结果就是,不少地方算力项目先建起来了,电却接不上,只能临时拉专线、买高价电。
更核心的冲突在运行逻辑上:算力要的是“随叫随到的稳定电”,新能源发的是“看天吃饭的波动电”。比如训练一个大模型需要连续跑半个月,可光伏晚上不发电、风电无风时歇菜,靠储能补缺口的成本又高得吓人。算电协同的本质,是要让两个完全不同逻辑的系统,同时满足“便宜、稳定、低碳”三个要求——这像让一个人同时跑赢三场不同规则的比赛。
还有个看不见的壁垒:两个行业“语言不通”。电力人说的“负荷率”“调峰”,算力人听不懂;算力人讲的“潮汐式任务”“推理时延”,电力人摸不着头脑。连基础的技术标准都不统一,更别说数据共享了。
就在矛盾快要绷断时,四部门联合发布的方案,把算力的角色彻底改了——它不再是只会“耗电”的包袱,而是能帮电网“调峰”的帮手。
这其中最关键的技术叫**构网型储能**——你可以把它理解成给算力中心装了个“智能充电宝”,但它比普通充电宝厉害:不仅能在用电低谷存电、高峰放电,还能像电网的“稳定器”,实时调整电压和频率,甚至在电网波动时临时“顶上去”。比如当风电突然没风时,构网型储能能立刻补上空缺,不让训练中的大模型突然断电前功尽弃。本质上,它让算力中心从“电网的负担”变成了“电网的一部分”。
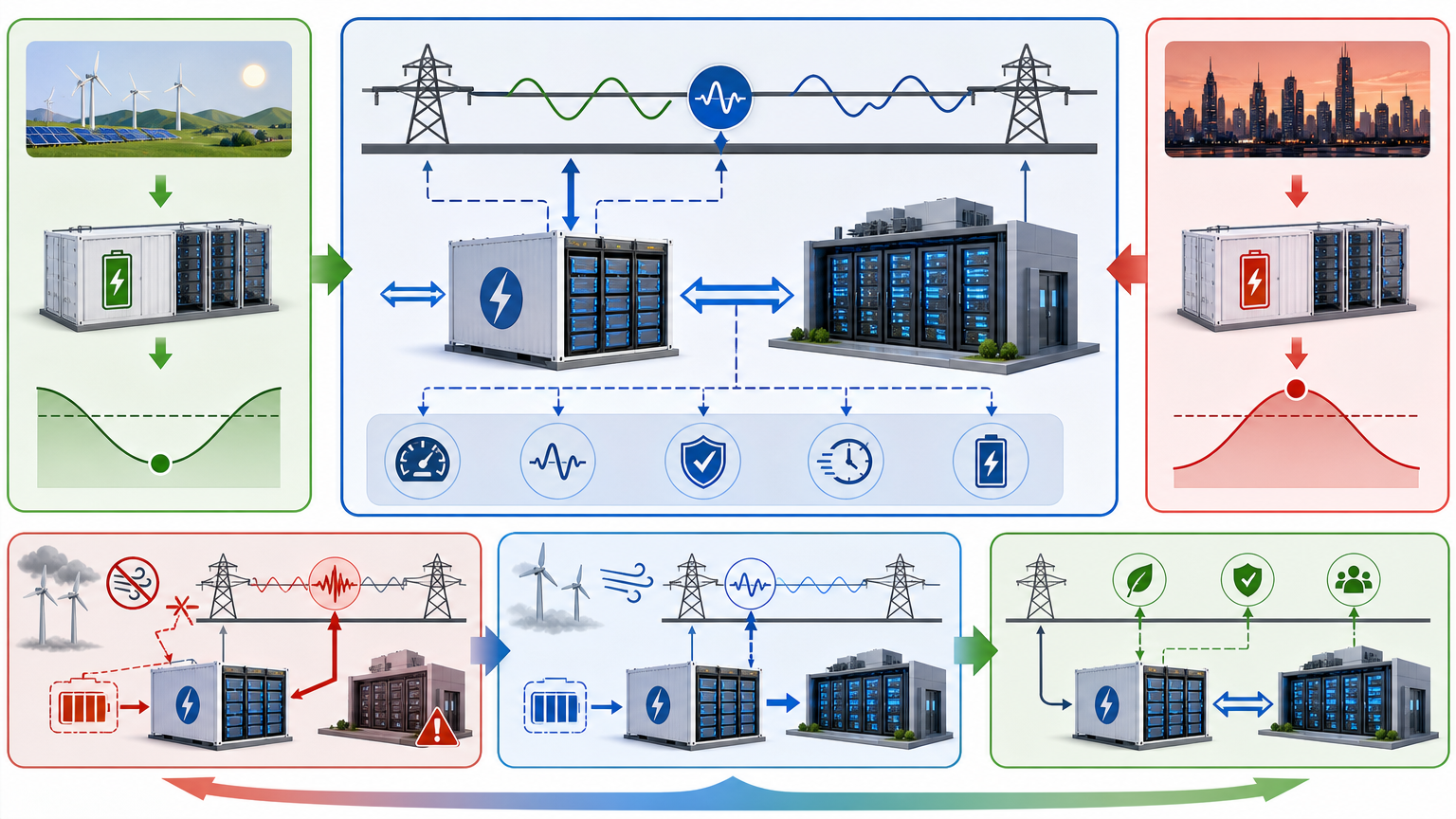
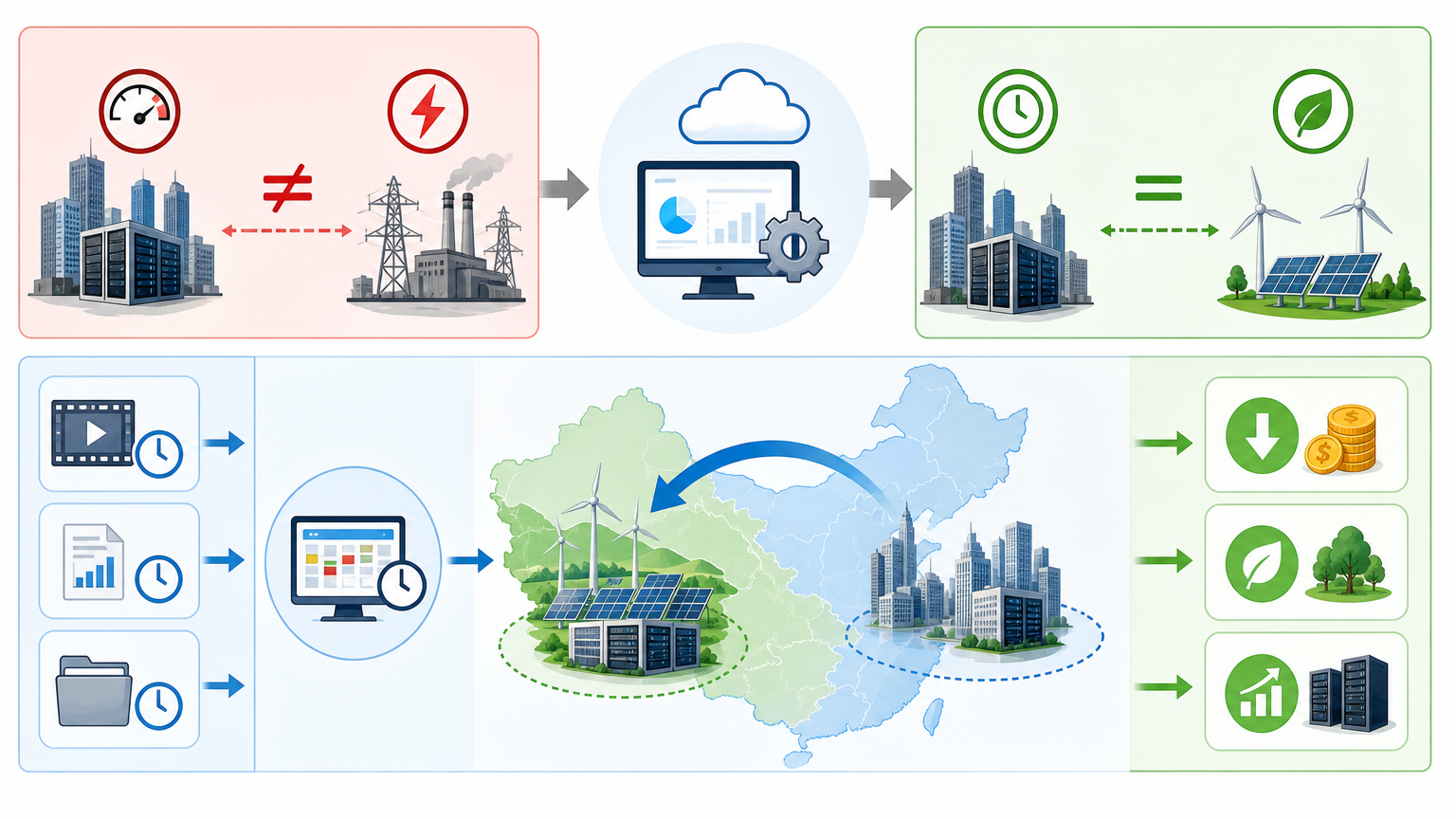
方案里还有个更重要的转向:把算力设施定义为电力系统的“新型负荷”。简单说就是,电网可以给算力中心发“价格信号”——用电高峰时电价涨,算力中心就把非紧急的训练任务暂停;低谷时电价跌,再开足马力。谷歌已经这么干了:他们的数据中心会根据实时电价调整算力负载,一年能省几千万美元电费。
还有个解决时空错配的办法:让算力跟着电走。比如把东部的非实时算力任务,调度到西部的新能源基地——那里风电光伏多,电便宜又绿色。这就是“东数西算”的核心逻辑,不是把数据搬过去,而是把“合适的任务”放到“合适的电”上。
当然,这些转变也有门槛:构网型储能的成本比普通储能高30%以上;算电协同的市场机制还没完全打通,比如绿电直连的成本谁来摊、调峰的收益怎么分,都还在摸索。而且不是所有算力任务都能调度——比如给你实时生成导航的推理任务,就不能等到半夜电价低了再算。
行业里有个共识:AI基础设施的上半场是“堆算力”——谁的服务器多、谁的芯片强,谁就赢;下半场是“组织算力”——谁能把绿色、稳定、便宜的电和算力高效绑在一起,谁才是赢家。
这背后是整个产业链的重构。比如传统的电源供应商,以前只卖变压器,现在要给算力中心做全套能源管理方案;数据中心的设计师,以前只考虑散热和机柜密度,现在得懂电网调度和新能源消纳。
有个国际案例可以参考:美国的“Power Couples”模式,让数据中心和风电光伏基地建在一起,直接用绿电,不用绕电网,不仅省了输电损耗,还能快速落地。国内的内蒙古、甘肃也在这么干——风电基地旁边直接建智算中心,电从风机出来就进服务器,全程不“拐弯”。

但这也不是万能药:这种模式适合非实时的训练任务,对实时性要求高的推理任务还是得靠电网。而且初期投入巨大,一个吉瓦级的智算基地,光储能设备就得花几十亿。
当我们谈论AI算力时,其实在谈论未来的能源形态。过去是“电跟着需求走”,现在要变成“需求跟着电走”——这不是谁迁就谁,而是两个系统的双向进化。
算电协同的本质,是用数字技术重新定义能源的流动:让AI帮电网预测风电光伏的出力,让算力中心帮电网平衡峰谷,让绿电的价值真正传导到每一个服务器。未来的智算基地,不会是一个孤立的“耗电怪兽”,而是能和电网、新能源基地对话的“智能节点”。
算力与电力的双向革命,才是AI可持续的底色。 当你下次用AI时,不妨想想:支撑它的,是一场正在改变能源格局的深层耦合。