对抗知识焦虑,从看懂这条开始
App 下载
三个本科生,给AI生成开了倍速
图像生成|TPU|AI生成速度|归一化流模型|BiFlow模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像生成|TPU|AI生成速度|归一化流模型|BiFlow模型|多模态视觉|人工智能
当你用AI生成一张256×256的ImageNet图片时,可能没意识到背后的两难:要么像扩散模型那样慢得像挤牙膏,要么像传统归一化流模型,为了快只能在画质和架构上妥协——就像给赛车装了限速器,还拆了半个引擎。
2026年CVPR的聚光灯下,三个20岁出头的本科生拿出了破局方案:他们的BiFlow模型,把AI生成速度拉快了两个数量级,在TPU上比传统流模型快697倍,同时还把生成画质推到了流模型的新高度。更关键的是,他们砸碎了困住归一化流几十年的枷锁——那把要求“逆向必须是前向精确逆运算”的锁。
你可以把归一化流模型想象成一套加密解密系统:前向过程是把图片“加密”成标准噪声,逆向过程是用“解密算法”把噪声还原成图片。传统流模型有个死规矩——解密算法必须是加密算法的精确逆运算,就像钥匙和锁必须严丝合缝,差一丝都转不动。
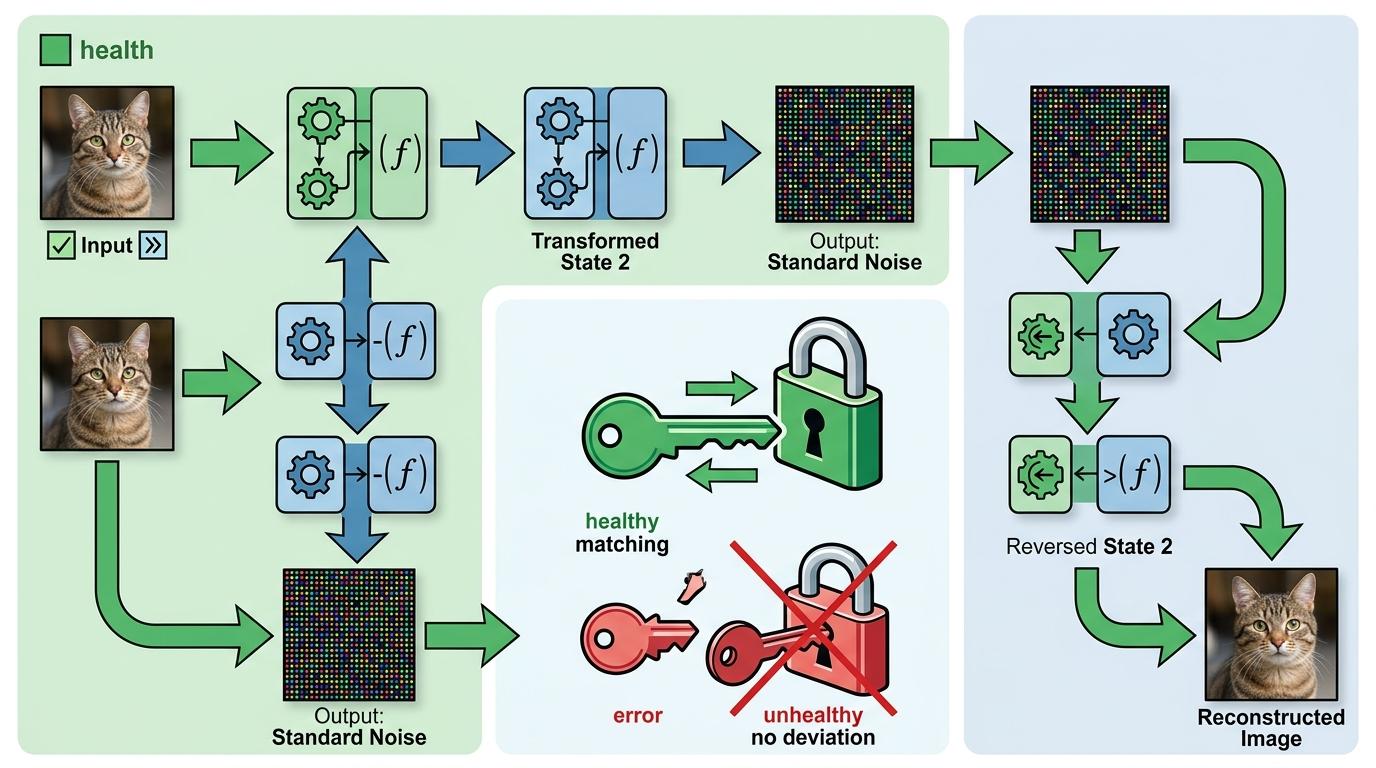
这个规矩带来了两个致命问题:一是架构被锁死,像视觉Transformer这种强大的通用架构,因为没法保证严格可逆,根本没法用;二是速度被拖慢,为了达到足够的画质,模型只能往深了堆、往宽了扩,生成时还得像自回归模型那样一步步计算,连并行加速都做不到。比如曾经的TARFlow,生成一张图得按顺序跑完全部步骤,就像用一根手指敲完一篇论文。
何恺明团队的研究一直盯着这个死穴。这次,三个本科生直接把“钥匙必须配锁”的规矩给废了。
BiFlow的核心逻辑简单到离谱:把加密和解密彻底分开,各干各的。
前向过程依然用改进版的TARFlow,负责把图片精准转换成噪声,这部分保留了流模型训练稳定、似然估计精确的优势。关键的逆向生成过程,他们直接换了一套独立的可学习模型——不用再当加密算法的“影子”,而是自己学怎么把噪声还原成图片。就像加密用复杂的军用电码,解密却用智能翻译器,不用死记硬背密码本,只要能准确还原信息就行。
为了让这个独立的逆向模型不跑偏,他们加了三个关键补丁:
一是**隐藏层对齐:把前向过程中每一步的中间状态都拿出来当监督信号,让逆向模型的“思考过程”和前向过程对齐,就像给翻译器配了原文的草稿,保证不会译得面目全非。 二是端到端去噪**:把传统流模型生成后额外的去噪步骤,直接塞进逆向模型里,生成出来就是干净的图,省掉了额外的计算开销。 三是训练时无分类器引导:把生成引导的逻辑提前到训练阶段,不用像扩散模型那样生成时跑两次前向传播,一次就能出结果。
最狠的是,逆向模型用上了非因果的双向Transformer——所有像素可以同时计算,不用再一步步等前面的结果,生成速度直接起飞。
实验数据给了最直接的证明:在ImageNet 256×256数据集上,BiFlow的FID分数达到2.39,刷新了流模型的最好成绩;采样速度比基线模型快了两个数量级,TPU上快697倍,GPU上最快也能快83倍。
更意外的是,因为双向映射的特性,BiFlow不用额外训练就能直接做图像修复和类别编辑——给一张缺了半张脸的图,它能精准补上;把猫的图改成狗,细节丝毫不乱。这在传统流模型里是不可想象的,毕竟连架构都被锁死,哪来多余的能力做拓展。
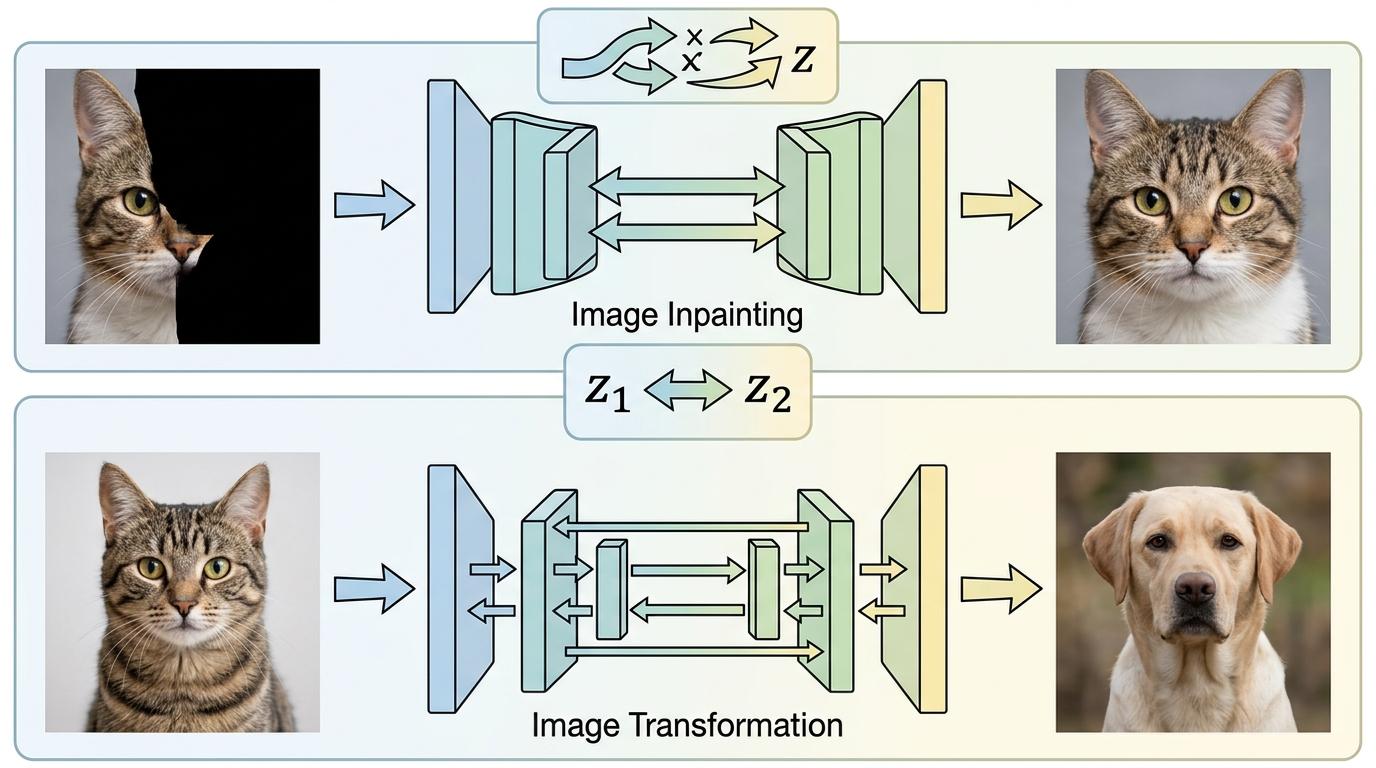
当然,它也不是完美的。目前BiFlow的逆向模型在处理更复杂的多模态数据时,训练稳定性还会波动;要适配边缘设备,还得进一步压缩模型体积。但它打开的那扇门,已经足够让人兴奋——原来生成模型不用在“快”和“好”里二选一,也不用为了数学严谨性牺牲架构的自由度。
当我们谈论AI生成的未来时,总在说更大的模型、更多的数据,却常常忘了那些被“严谨性”捆住的手脚。BiFlow的突破,本质上是给生成模型松了绑:让算法回归解决问题的本质,而不是被数学规则框死。
三个本科生的研究,也像一个信号:在AI的前沿领域,打破陈规的勇气,有时候比复杂的公式更重要。毕竟,真正的创新,从来不是在既有框架里修修补补,而是敢先问一句“为什么必须这样”。
规矩是用来打破的,不是用来守死的。