对抗知识焦虑,从看懂这条开始
App 下载
自动驾驶占比0.006%,却已摸到L4的门槛
北京车展|整体思考|端到端系统|五层蛋糕体系|L4级自动驾驶|自动驾驶
对抗知识焦虑,从看懂这条开始
App 下载北京车展|整体思考|端到端系统|五层蛋糕体系|L4级自动驾驶|自动驾驶
全球每年车辆跑出来的13万亿英里里程里,自动驾驶只占0.006%——这个数字小到几乎可以忽略不计。但就在北京车展的一间会议室里,有技术团队笃定地说,自动驾驶已经到了关键的“ChatGPT时刻”,L4级完全自动驾驶的曙光就在眼前。
这不是空口的乐观:他们正在用一套被称为“五层蛋糕”的体系,把自动驾驶从实验室的零散技术,整合成能落地的完整系统。更关键的是,这套体系的核心,是抛弃了沿用几十年的老思路——自动驾驶的逻辑,正在从“分工干活”变成“整体思考”。
过去的自动驾驶系统,像一条分工明确的流水线:摄像头负责“看”,算法负责“识别障碍物”,另一个算法负责“规划路线”,最后再给方向盘和油门发指令。每个模块各司其职,但问题也很明显——前一个模块出一点小误差,后面就会层层放大,就像流水线里前面的零件歪了,后面的产品全废。
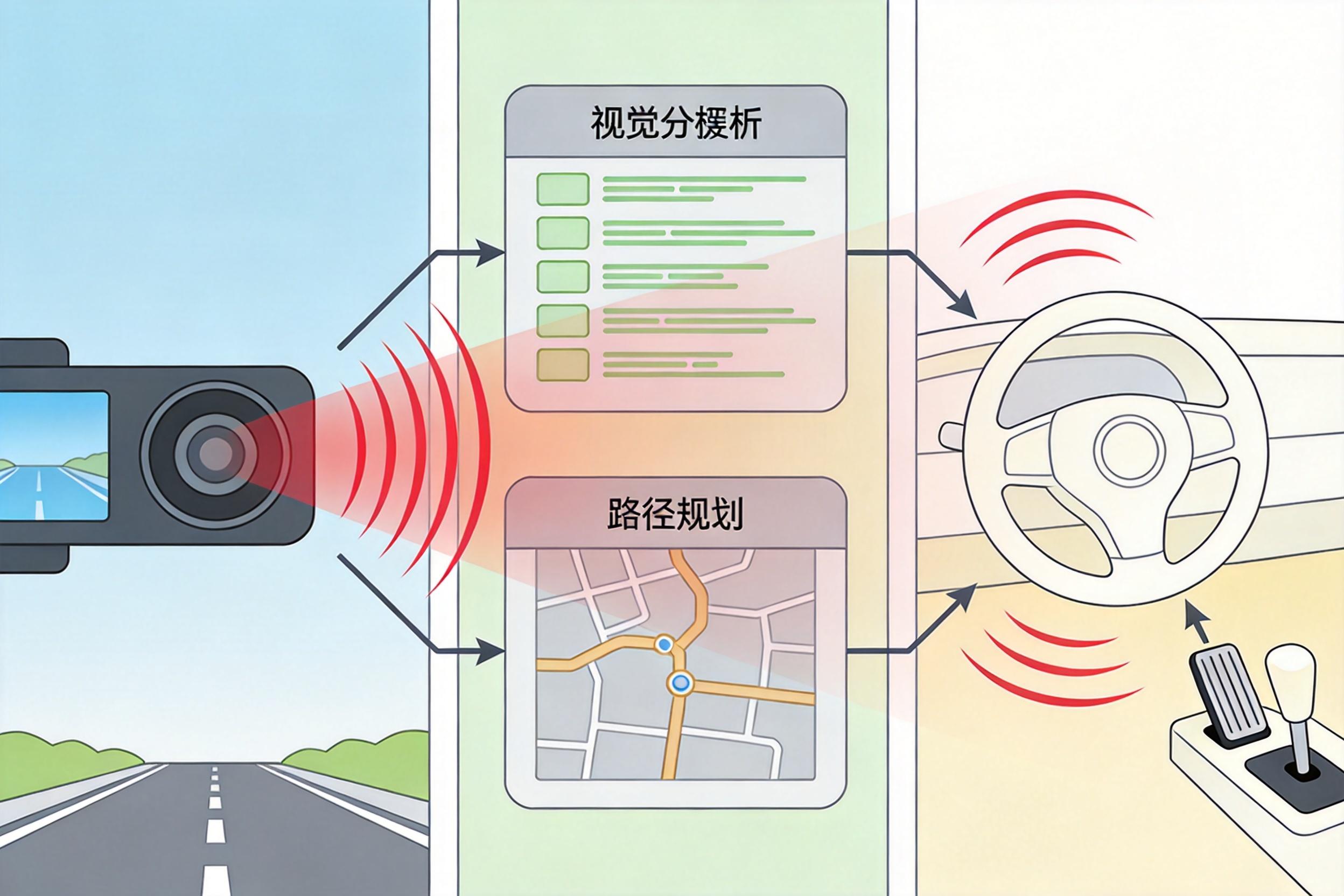
现在的端到端架构,更像一个完整的人类大脑:把摄像头、激光雷达、雷达的所有原始数据直接喂给一个神经网络,它能直接输出“左转”“加速”这样的控制指令,跳过了中间所有拆分的步骤。你可以把它想象成,不用先教孩子“这是红灯”“这是斑马线”,直接让他看路况学开车——通过几百万英里的驾驶数据训练,它能自己学会应对各种场景。
这套架构的优势很直接:没有了模块间的误差累积,系统反应更快,处理复杂场景的能力也更强。比如遇到突然窜出来的行人,它不用先“识别这是行人”“判断距离”“规划避让路线”,而是直接做出刹车动作——就像人类司机的本能反应。

端到端系统的训练,需要海量的真实驾驶数据,但现实中不可能覆盖所有极端场景——比如暴雨天加施工路段加突然变道的货车。这时候,仿真技术就成了关键。
现在的高保真仿真系统,能1:1还原真实世界的物理规则:路面的摩擦力、雨天的能见度、其他车辆的随机行为,甚至连阳光反射的角度都能精确模拟。技术团队现在每天能在虚拟世界里进行200万次场景验证,相当于把一辆车开了几百万英里,而且能反复测试同一个极端场景,直到系统学会正确应对。

更聪明的是,他们还能用AI生成“合成数据”——比如把真实的城市道路和虚拟的极端天气结合,造出“暴雪天的十字路口”这种现实中很难遇到的场景。这些数据能帮系统补上“长尾场景”的短板,让它在真实世界里遇到意外时,不会像个没见过世面的新手。
最近行业里有个热门争论:能不能跳过需要人类接管的L3,直接做完全自动驾驶的L4?但技术团队的判断是,两者会长期并存。
L3的价值在于“解放双手但不解放大脑”——你不用握着方向盘,可以刷手机,但需要随时准备接管。这听起来有点鸡肋,但它刚好击中了通勤族的刚需:每天一两个小时的堵车时间,不用再全神贯注盯着路。而L4需要的是“全程不用管”,这不仅需要更强大的硬件,还需要云端远程操控的能力,成本是L3的好几倍,短期内很难普及到家用车。
更重要的是,L3的落地能积累大量真实世界的数据,反过来喂给L4的训练模型。就像先学会骑自行车,再学骑摩托车——两者共享平衡感和路况判断的经验,能大大降低高阶技术的落地难度。
当我们盯着0.006%这个微小的数字时,其实忽略了另一个事实:自动驾驶的技术逻辑,已经从“堆硬件”变成了“拼系统”。从模块化到端到端,从真实路测到仿真训练,这套体系正在把自动驾驶从“科幻概念”拆解成“可落地的工程问题”。
“每一英里都会变成自动驾驶”的愿景,现在看起来还很远,但技术的拐点往往就藏在这些不起眼的细节里。当系统学会像人类一样“整体思考”,当虚拟世界能补上真实场景的短板,那0.006%的星星之火,或许真的能燎原。
技术的迭代,从来不是跳跃,而是把小事做透。