对抗知识焦虑,从看懂这条开始
App 下载
AI按Token收费,背后藏着语言的秘密
计费机制|文本处理|语义拆分|Token计价|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载计费机制|文本处理|语义拆分|Token计价|大语言模型|人工智能
你有没有过这种经历:给AI发了段长文本,收到的回复没头没尾,或是账单跳出时,数字比预期高了好几倍?问题的根源,可能藏在你从未在意的「Token」里——这个被当作AI计价单位的小东西,其实是机器理解人类语言的核心密码。
Token不是词,也不是字符,是大模型把语言拆碎后得到的「最小语义积木」。它的大小全看频率:英文里「ing」「tion」这类高频后缀会被打包成整块Token,生僻词则会被拆成单个字母;中文里大多是单字成Token,但「所以」「因为」这类高频词组,也会被模型自动合并。这种拆分逻辑,是为了在计算效率和语义完整间找平衡——既不让模型因处理单个字符累死,也不让它因拆分太粗错过关键语义。
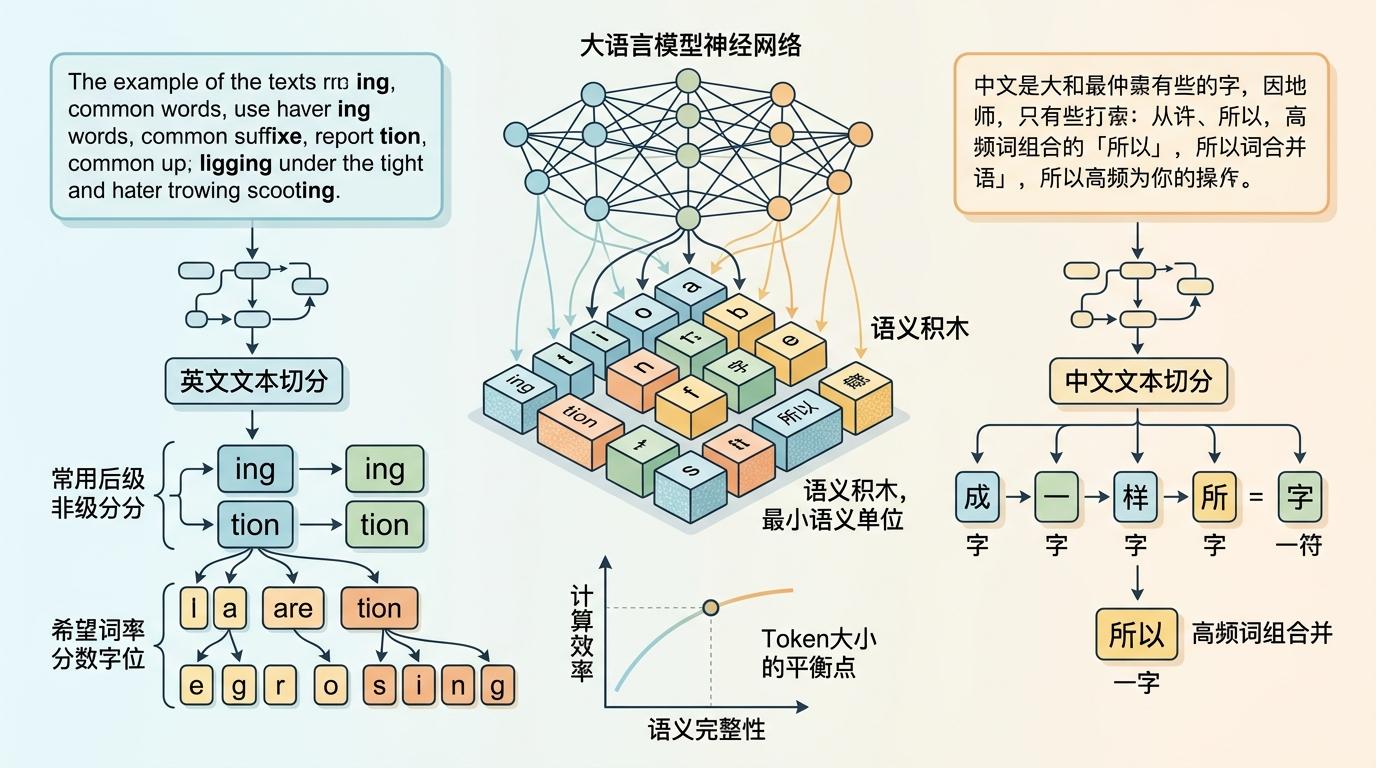
你或许没意识到,Token的划分直接决定了AI的能力边界。Transformer模型的注意力机制,计算量会随Token数量的平方增长——这就是为什么大模型的「上下文窗口」总有上限,超过后要么报错,要么开始「失忆」。更现实的影响是计费:输入和输出的Token分开计价,输出Token的价格通常是输入的3到5倍,冗长的提问、要求长篇回复,都会让成本指数级上升。
但这里藏着一个被忽略的不公平:现有Token化算法几乎都是基于英语语料训练的,中文、阿拉伯语这类非英语语言,或是乌克兰语这类低资源语言,会被拆成更多Token。同样一段语义,中文的Token数可能比英文多20%到30%,直接推高了使用成本。甚至专业领域的文本,比如代码、法律条文,也会因特殊符号和术语被过度拆分,让Token数再涨30%。
优化Token使用,早已不是技术细节,而是AI落地的核心命题。精简提问、压缩对话历史、用语义分块替代固定长度拆分,能让Token消耗骤降80%以上;一些企业甚至会用专门的工具压缩结构化数据,把JSON格式里的冗余字段替换成短标识符,再把Token数砍去六成。这些操作不会降低回答质量,却能把成本拦腰斩断。
未来的Token化,会朝着更智能的方向走:动态调整拆分粒度,根据不同语言、不同任务定制Token字典,甚至把图像、音频也转换成统一的Token序列。但眼下最该明白的是:AI本身不贵,不受控的Token消耗才贵——就像你不会为了喝杯水买一整桶矿泉水,学会给AI「精准喂料」,才是用好它的第一步。