对抗知识焦虑,从看懂这条开始
App 下载
AI改表情终于告别“变脸”,实现精准可控
图像生成模型|表情编辑|StepFun|复旦大学|PixelSmile|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像生成模型|表情编辑|StepFun|复旦大学|PixelSmile|多模态视觉|人工智能
你有没有过这种经历:用修图软件给照片里的人加个微笑,结果出来的脸要么笑到变形,要么连亲妈都认不出;想调个“惊讶”,结果做成了“恐惧”;稍微把表情调明显点,人物直接换了张脸?这些尴尬,本质上是AI表情编辑卡在了“能改”却“不可控”的瓶颈——要么表情变假,要么身份丢失,要么相近情绪傻傻分不清。直到复旦大学与StepFun联合开源的PixelSmile出现,才第一次把“精准控制表情”这件事落地。它到底是怎么做到的?
传统AI处理表情,就像只有“开心”“愤怒”“惊讶”这几个固定色号的颜料盘——你只能选一个色块涂上去,要么全是,要么全不是,中间没有过渡,更别说混合出“惊喜”“又气又笑”这种复杂情绪。但真实的人类表情根本不是离散的,而是像光谱一样连续渐变:从嘴角微扬到开怀大笑,从挑眉到瞪圆双眼,每一丝细微变化都对应着情绪的精准刻度。
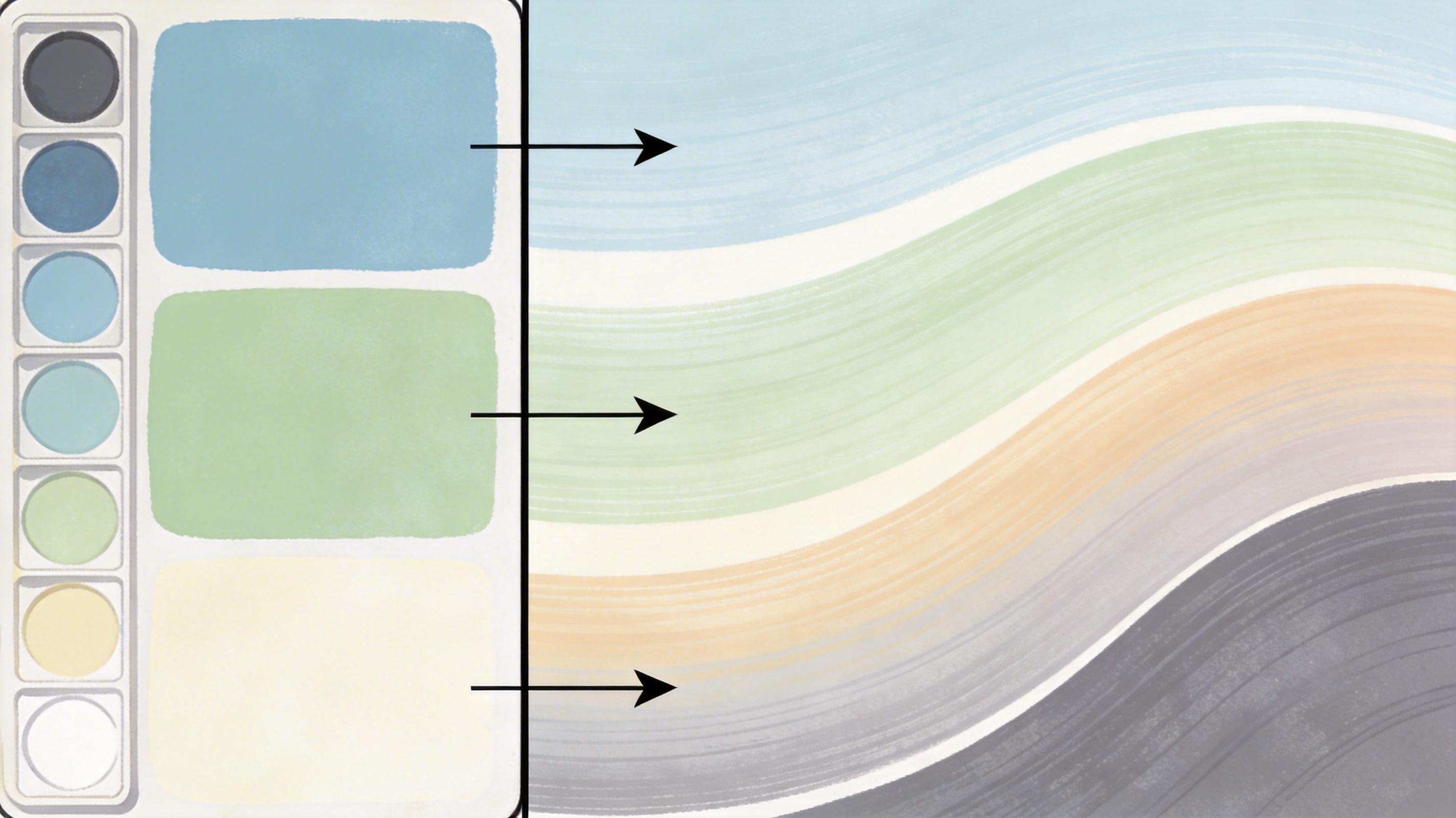
PixelSmile的核心突破,就是把表情从“固定色号”变成了“连续调色盘”——它构建了一个**连续语义空间**,简单说就是把所有可能的表情都映射到一个多维的“情绪地图”上。你可以在这个地图上任意滑动,从“平静”到“大笑”选任意强度,也能在“惊讶”和“开心”的中间地带调出“惊喜”,甚至能把“厌恶”和“愤怒”精准区分开,不会再让AI把两者混为一谈。
为了建这个“调色盘”,团队专门做了一件事:打造了包含12万张图像的FFE数据集,每张图都标注了12种情绪的连续强度——不是“有没有”,而是“有多少”。就像给每个表情拍了张“X光片”,让AI能看清情绪的细微结构。

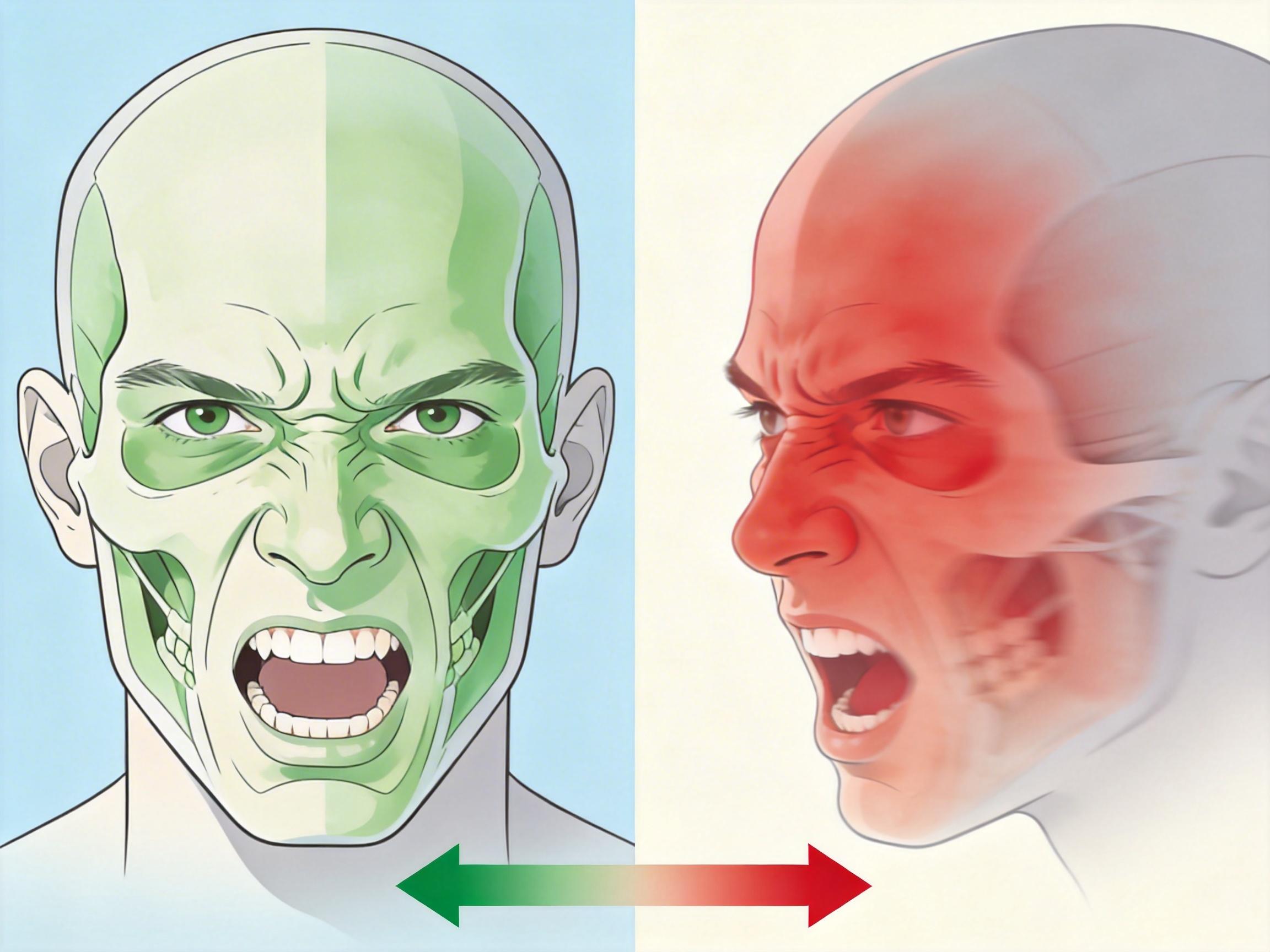
表情编辑最头疼的矛盾:表情越夸张,脸越容易变样。这是因为传统模型里,“表情”和“身份”的信息是缠在一起的,动表情的时候难免会碰倒身份的“多米诺骨牌”。
PixelSmile解决这个问题的思路,是用一种叫**完全对称联合训练**的方法,把表情和身份的信息“解耦”——就像把一杯混合了咖啡和牛奶的拿铁,重新分成纯咖啡和纯牛奶。训练时,它会同时对比“相近表情的差异”和“同一身份的不变性”:一方面让AI能精准区分“惊讶”和“恐惧”这种易混淆的情绪,另一方面死死抓住人脸的核心特征——比如眼角的细纹、下巴的轮廓,不管表情怎么变,这些特征都纹丝不动。
在FFE-Bench基准测试里,PixelSmile的平均结构混淆率只有0.055,是其他主流模型的1/2到1/3;身份相似度在高强度表情下仍能保持在0.6-0.7区间,而其他模型早就跌到0.5以下。简单说就是:笑到劈叉,你还是你。
过去评价AI表情编辑,全靠“看脸”——觉得自然就是好,觉得变样就是差,没有统一的标准。这就像没有尺子的裁缝,做出来的衣服全凭手感。
PixelSmile团队不仅做了模型,还搭了一套叫FFE-Bench的评测框架,第一次把表情编辑的效果拆成了可量化的指标:用mSCR衡量相近表情的区分度,用CLS衡量表情强度的线性可控性,用HES综合评价表情准确性和身份保持度。就像给裁缝递上了精确的尺子、量角器和天平,让“好不好”变成了“具体哪里好、好多少”。
这套标准有多管用?在测试中,GPT-Image和Nano Banana Pro这些通用大模型,在表情强度拉满时都会出现明显的身份偏移,而PixelSmile能在表情精准变化的同时,把身份特征稳稳攥住。数据不会说谎,这就是“可控”和“不可控”的本质区别。
当然它也不是完美的——比如对更细微的微表情处理还不够精准,跨文化的表情差异适配也还有提升空间,但它已经把表情编辑从“碰运气”拉到了“讲科学”的轨道上。
从“能改表情”到“可控表情”,PixelSmile迈出的这一步,本质上是AI对人类情绪理解的一次升级——它不再把情绪当成一个个孤立的标签,而是开始理解情绪的“灰度”和“层次”。这不仅是技术上的突破,更是AI向“读懂人心”又靠近了一小步。
未来,当数字人能精准复刻你嘴角的一丝苦笑,当虚拟主播能根据观众的情绪调整表情,当AI能帮你把照片里的遗憾表情改成恰到好处的微笑,你会想起今天这件事:让AI学会精准控制表情,是让虚拟世界更有温度的开始。毕竟,能精准传递情绪的技术,才是真正能连接人和人的技术。