对抗知识焦虑,从看懂这条开始
App 下载
不用3D标注,机器人也能看懂房间
自然语言理解|RGB照片|室内三维感知|香港科技大学(广州)|LegoOcc|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自然语言理解|RGB照片|室内三维感知|香港科技大学(广州)|LegoOcc|多模态视觉|人工智能
想象你让家里的机器人找玄关柜旁的雨伞——它不需要提前被“灌输”雨伞的标准样本,也不需要有人在三维空间里逐点标记“这是雨伞”,只需要看一眼客厅的照片,就能听懂你的自然语言,精准定位到那把从未见过的折叠伞。这不是科幻片里的场景,而是香港科技大学(广州)团队带来的LegoOcc正在实现的事。它打破了室内三维感知的最大瓶颈:不用昂贵到离谱的3D语义标注,仅凭一张普通RGB照片,就能让机器真正“理解”空间——哪里能走,哪里有东西,那东西又是什么。
传统的室内三维感知,像是让机器人对着一本提前标好所有答案的题库答题——只能认出训练过的固定物体,还得有人花几个月在三维空间里逐个体素标注“这是桌子”“这是地板”。但真实的家里,桌子可能被地毯半挡着,沙发旁会突然多出孩子的玩具,这些“超纲题”能把传统模型直接难住。
LegoOcc的思路,是把整个三维空间拆成一个个带“智能标签”的“乐高块”——也就是带语言特征的三维高斯表示。每个“乐高块”里同时装着两个信息:一是它在空间里的位置、大小和透明度,用来判断“这里有没有东西”;二是一组能和自然语言对齐的语义向量,用来回答“这东西是什么”。
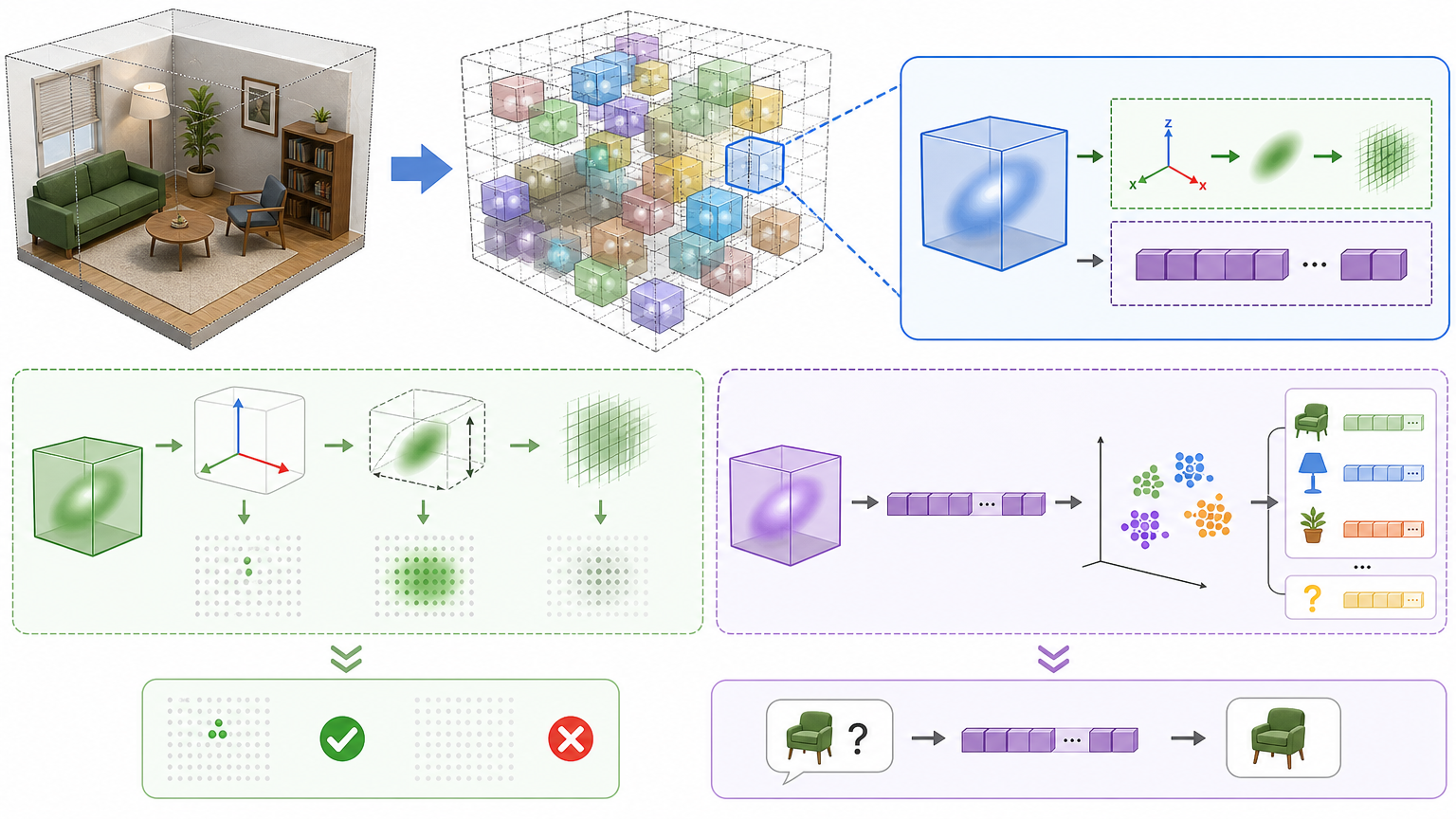
你可以把这个过程想象成给每个空间小方块贴了张隐形的“语义二维码”,机器人扫到它,既能知道自己能不能踩上去,也能通过和文本特征比对,认出这是雨伞还是充电线。
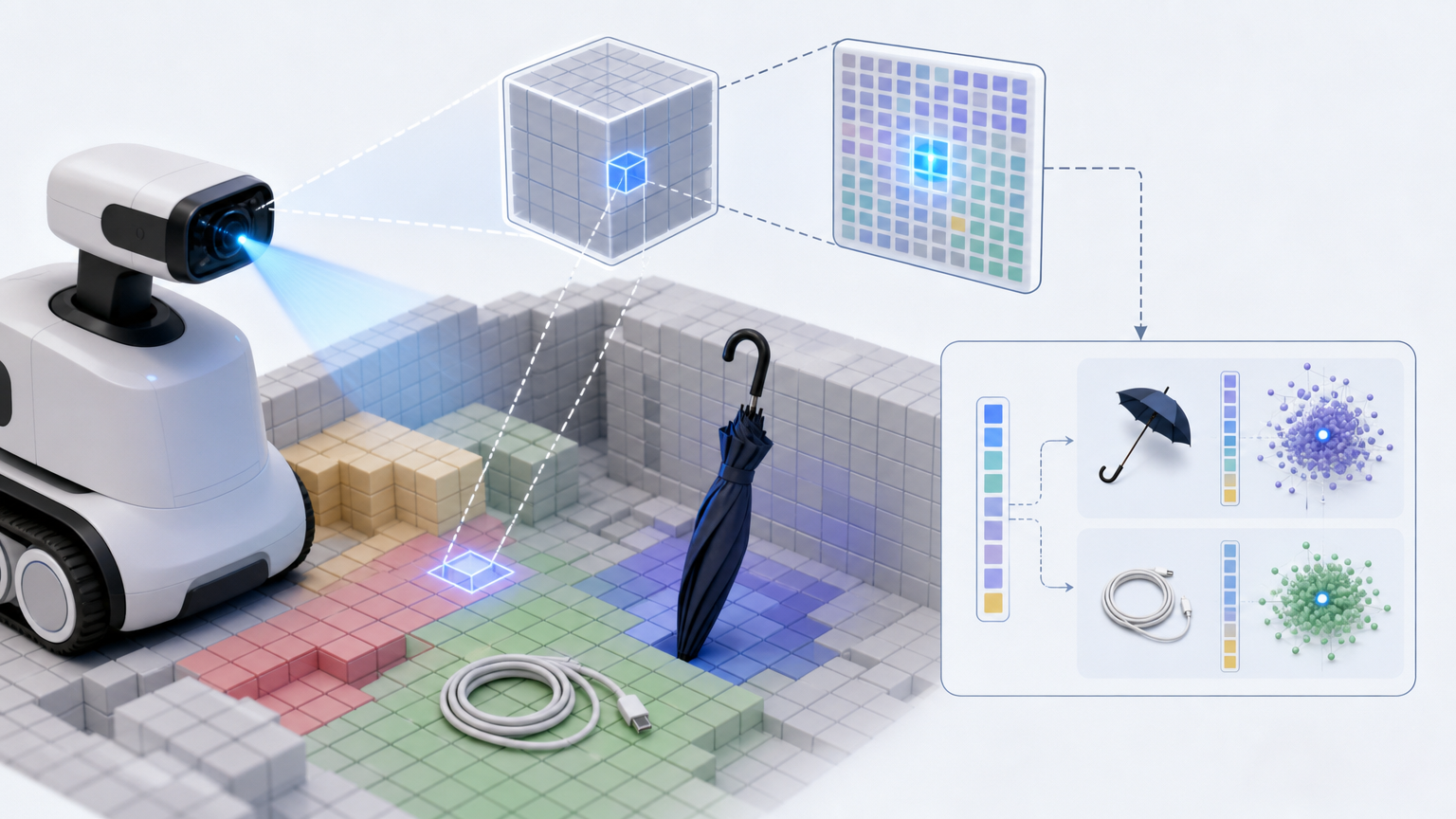
LegoOcc能做到无3D标注也精准,靠的是两个针对性的技术突破。
第一个是基于泊松分布的高斯到占用转换。传统方法处理重叠的“乐高块”时,要么忽略它们的透明度信息,要么简单平均导致语义混乱——就像把红、黄、蓝三块乐高混在一起,最后只能得到模糊的棕色。而泊松分布的思路,是把每个“乐高块”当成“这里有物体”的一份证据,一个位置是否被占据,由所有相关“乐高块”的证据共同决定。就像多个目击者描述同一个嫌疑人,越多人提到某个特征,这个特征的可信度就越高,自然能更准确地还原真相。实验里,这个设计直接让几何占用准确率IoU从36.70跳到了59.50,超过了所有依赖3D标注的闭集方法。
第二个是渐进式温度衰减策略。训练初期,模型还没搞懂空间结构,就像刚进陌生房间的小孩,需要先整体熟悉环境——这时候用“高温”模式,让语义特征平滑融合,避免因细节纠结而崩溃。等模型对空间有了稳定认知,再慢慢降低“温度”,让每个“乐高块”的语义边界变得清晰,就像孩子熟悉房间后,能准确区分“这是我的玩具区”“那是妈妈的书架”。其中指数式衰减效果最好,能让模型在“清晰语义”阶段停留更久,最终把语义识别准确率mIoU从9.25提升到21.05,翻了一倍多。
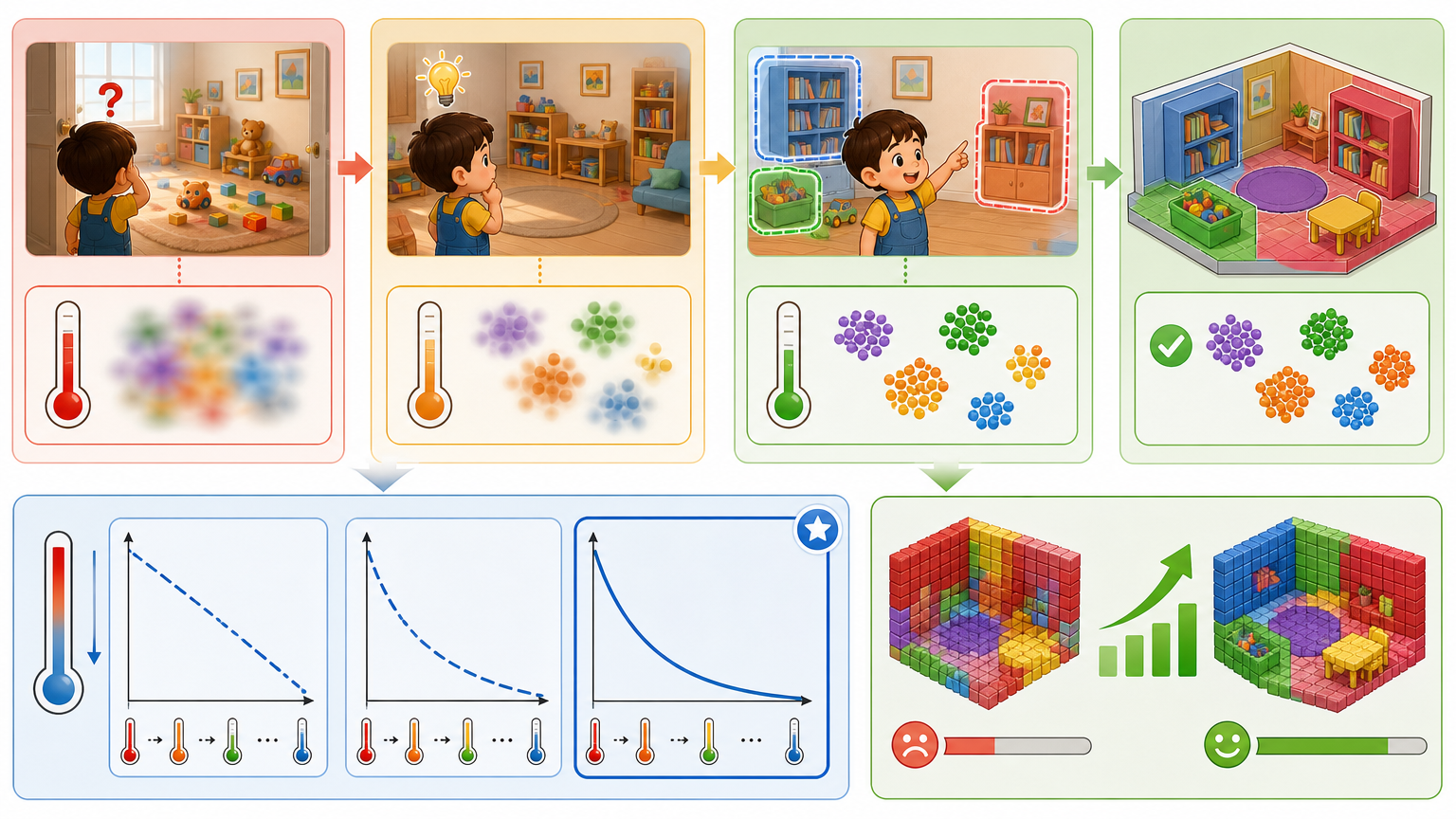
当然,LegoOcc还不是完美的。它的语义识别准确率mIoU,和依赖完整3D语义标注的闭集方法比如RoboOcc的47.76相比,还有不小差距。这背后是三道暂时没完全跨过的坎:
一是室内类别本身的细碎和模糊——椅子和沙发的边界在哪里?“杂物”又该包含多少东西?这些连人类都可能纠结的问题,机器更难精准区分。二是单目输入的固有缺陷——一张照片里的深度歧义,比如远处的小桌子和近处的小凳子,模型偶尔会判断失误。三是对2D开放词汇分割模型的依赖,如果2D模型认错了物体,3D空间里的语义也会跟着出错。
但这些局限,反而更凸显了LegoOcc的价值:它用极低的成本,摸到了三维开放词汇感知的门槛,为家庭机器人的大规模部署扫清了最关键的障碍。
当我们谈论机器人的“智能”时,往往容易陷入“它能认出多少物体”的误区。但真正的室内智能,从来不是“认出桌子”,而是“理解桌子和周围空间的关系”——知道桌子边缘不能碰,知道桌子下面可以躲,知道桌子上的水杯需要被小心拿起。
LegoOcc的意义,就是让机器从“看物体”转向“懂空间”,从“答题库”转向“解应用题”。未来的家庭机器人,不会再因为你换了个新款式的拖鞋就认不出,也不会因为地上多了根充电线就不知所措。
空间理解的本质,是让机器学会像人一样感知世界。