对抗知识焦虑,从看懂这条开始
App 下载
25万次钢琴演奏数据集,终结AI练琴的混乱
音乐AI研究|数据清洗|钢琴演奏MIDI|斯科尔科沃科技学院|PianoCoRe数据集|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载音乐AI研究|数据清洗|钢琴演奏MIDI|斯科尔科沃科技学院|PianoCoRe数据集|AI产业应用|人工智能
你或许没听过「数据保姆」这个词,但在钢琴AI研究者的圈子里,这是个让人头疼的身份——他们要花80%的时间,从零散的MIDI文件里挑错、去重、对齐乐谱,真正留给模型创新的时间只剩五分之一。直到2026年5月,俄罗斯斯科尔科沃科技学院的团队扔出了一颗「炸弹」:一个整合了7大公开数据源的超级数据集PianoCoRe,包含25万次钢琴演奏、5625首作品,总时长超过21763小时。更关键的是,它把研究者从「数据清洁工」的苦役里解放了出来。这到底是怎么做到的?
过去的钢琴AI数据,像个堆满杂物的仓库:MAESTRO数据集只有200小时高质量演奏,但风格单一;GiantMIDI-Piano有1237小时,却满是自动转录的错误;ATEPP的表达性演奏数据,又缺了关键的乐谱对齐。PianoCoRe的第一步,是把这些散落的「零件」拼成了一个标准化的「工具箱」。
它把数据分成了四个层级:完整版C保留所有原始数据,适合大规模无监督预训练;基础版B剔除了3万多个重复文件,再用质量分类器筛掉低质样本,剩下21万次干净的演奏;对齐版A实现了15万次演奏与乐谱的逐音符匹配;最高级的A*则进一步剔除了转录精度不足的来源,留下13万次「零误差」的对齐数据。
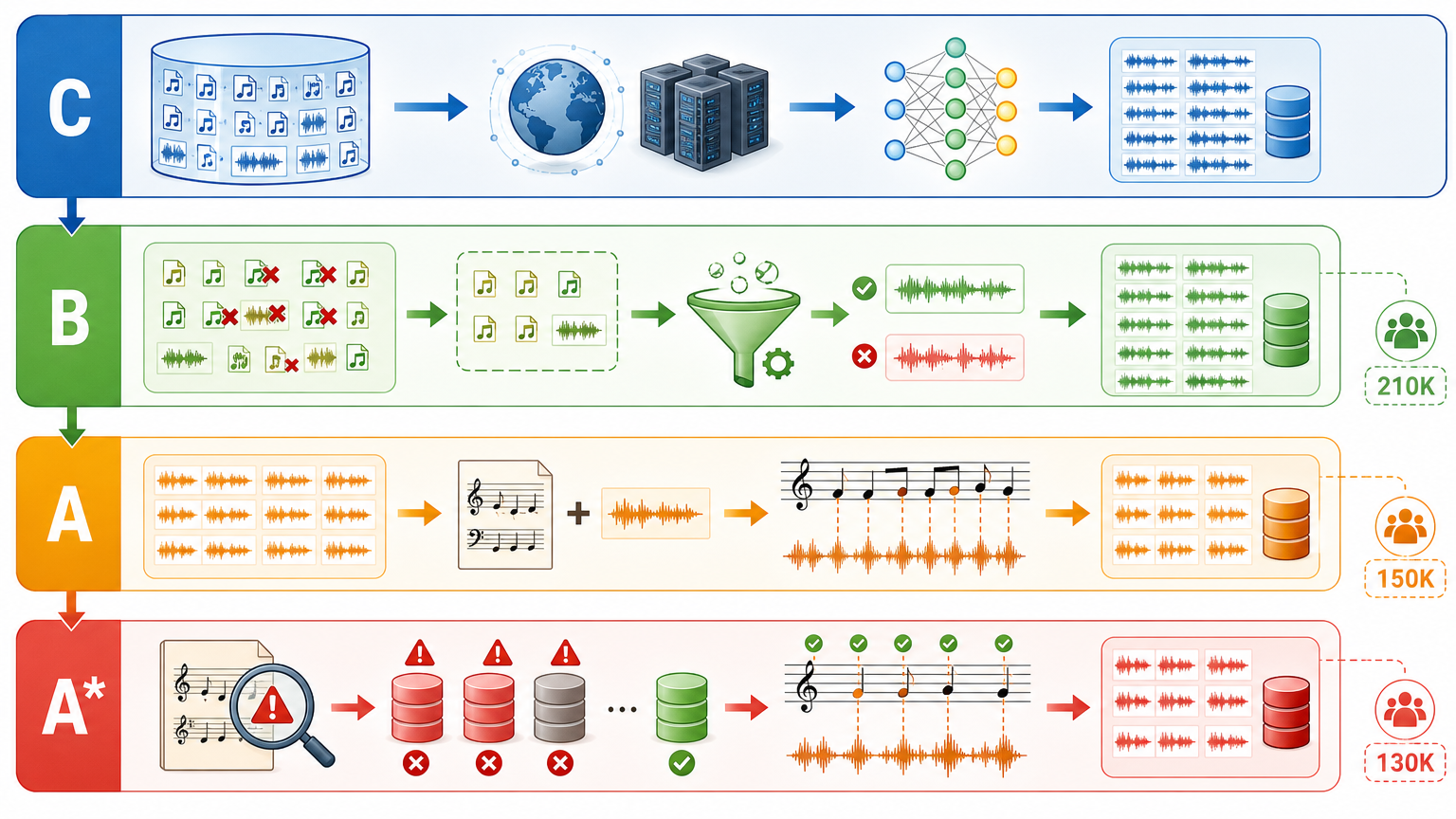
这就像把杂乱的食材分成了「整箱生鲜」「净菜拼盘」和「即食料理包」,研究者不用再自己洗菜切菜,直接就能下锅——有人要练「大锅菜」的火候,有人要做「精细菜」的刀工,都能找到对应的原料。
光把数据堆在一起还不够,PianoCoRe的真正底气,是两个能给数据「治病」的工具。
第一个是MIDI质量分类器。你可以把它想象成钢琴数据的「体检仪」:它会计算演奏音符和乐谱音符的比例,判断是不是漏弹了音或者多了杂音;再看对齐的召回率和精确率,区分是高质量演奏、低质量错漏,还是只是照着乐谱生成的「假演奏」。最后用随机森林算法结合TF-IDF特征——把每个MIDI文件当成一篇「文章」,音符组合当成「词汇」,捕捉高质量演奏的模式——准确率能达到96%。就像医生一眼能看出谁是健康的、谁是亚健康的,谁已经病入膏肓。
第二个是RAScoP对齐精炼流水线,这是给数据「正骨」的大师。自动转录的对齐结果,往往像个骨头长歪的人:有的音符弹早了,有的漏弹了,有的节奏完全跑偏。RAScoP先做「空洞处理」,用周围的音符密度和速度信息,补上漏弹的装饰音;再做「起始偏移清洁」,用中值滤波修正那些弹早或弹晚的音符。处理之后,音符间的时间误差从平均30ms降到了20ms以内,极端快节奏或慢节奏的异常值几乎消失——就像把歪掉的骨头一点点掰正,让每一个音符都精准地落在乐谱的「刻度」上。
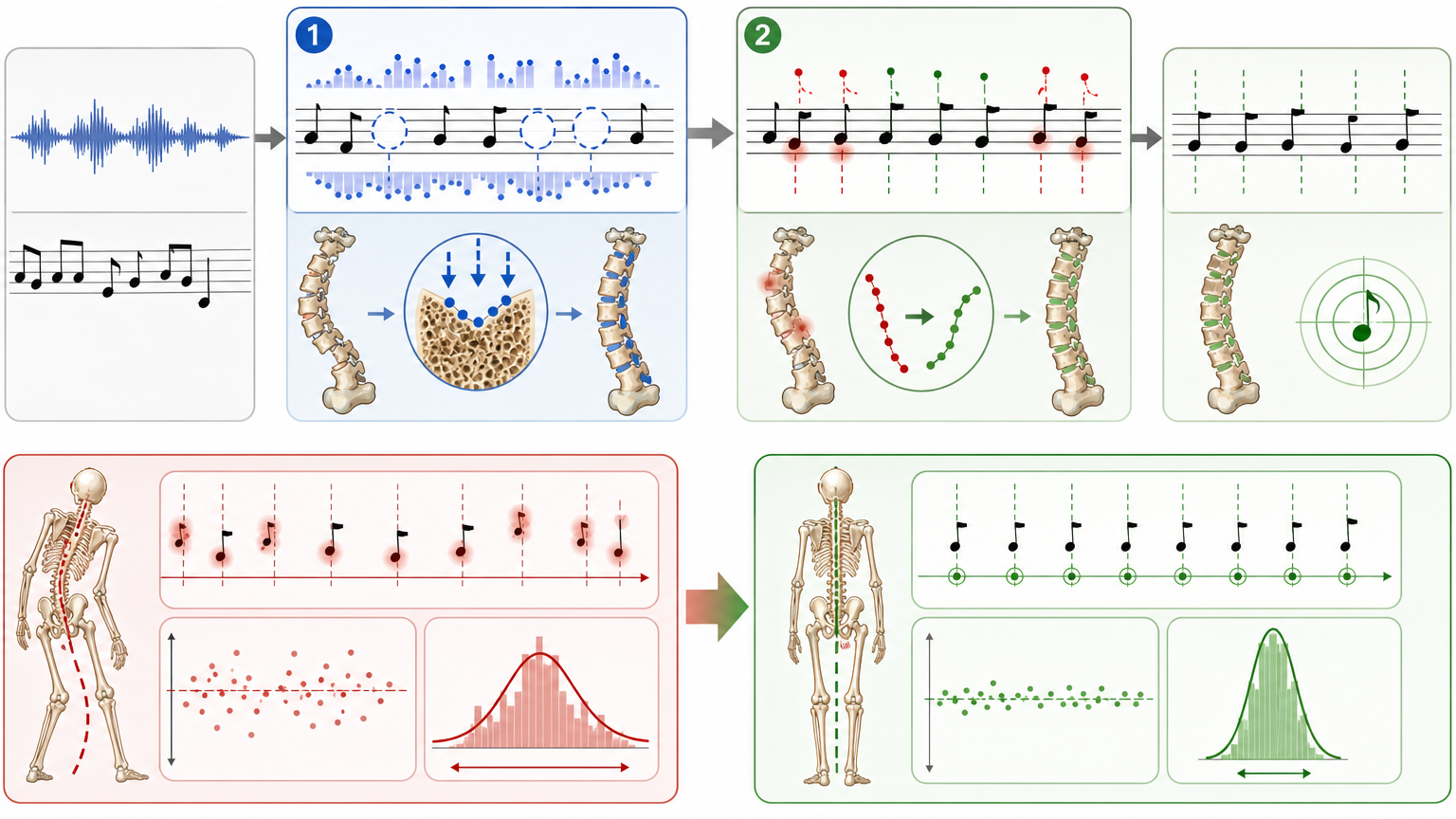
有了这两个工具,PianoCoRe的数据就从「参差不齐的毛坯房」,变成了「精装修的样板间」。
当然,PianoCoRe也不是万能的。它的自动转录数据里,依然可能藏着低音线错乱、踏板模拟不准的错误;RAScoP的补全逻辑,对付不了钢琴家即兴发挥的加花;它的曲库也偏重于古典音乐,爵士、流行的内容少得可怜;更别说受欧盟版权限制,很多20世纪的重要作品没能收录。
但这些「不完美」,恰恰是它的诚实。就像一位严谨的工匠,它会告诉你这块木料的瑕疵在哪里,而不是把它吹成无瑕的美玉。研究者不用再在数据的「雷区」里摸索,可以放心地把精力放在真正有价值的地方:比如用A*数据集训练能模仿大师风格的AI演奏模型,或者用C数据集做超大规模的自监督预训练,探索音乐的深层规律。
有研究者测试过,用PianoCoRe-A*训练的Transformer模型,困惑度低至2.87,和声一致性达到79.4%,生成的音乐在主观测试里接近人类演奏的水平——这在过去,是要花几个月时间自己整理数据才能达到的效果。
当我们谈论AI钢琴的未来时,我们常常会想起那些能模仿肖邦风格、能和人类钢琴家对弈的模型,但很少有人意识到,所有这些惊艳的表演,都建立在「数据地基」之上。PianoCoRe的意义,不仅是提供了25万次演奏,更是第一次给钢琴AI搭建了一个标准化的「跑道」——从此研究者不用再自己修路,只需要专注于把车开得更快。
数据不是负担,是创新的燃料。 当AI终于能站在统一、高质量的数据集上,我们离真正能理解音乐、表达情感的AI钢琴家,又近了一步。而这,或许才是PianoCoRe最珍贵的礼物:它让我们看到,当基础科学的「慢功夫」做扎实了,技术的突破会来得比想象中更快。