对抗知识焦虑,从看懂这条开始
App 下载
AI越聪明越费钱,我们得学会给它“减肥”
效率优化|AI推理成本|Token消耗|Claude Mythos|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载效率优化|AI推理成本|Token消耗|Claude Mythos|大语言模型|人工智能
2026年的春天,有人在社交平台晒出一张截图:跟AI说一句“你好”,耗掉了当月13%的Token额度。这不是玩笑——当Anthropic推出史上最强也最贵的Claude Mythos,输入百万Token要25美元、输出更是高达125美元时,“和AI说不起话”突然从调侃变成了现实。
你以为发一句简短指令就能省成本?有人试过用文言文提问,结果字符数少了近三分之一,Token数却几乎没差。更离谱的是,大模型明明已经算出答案,偏要绕着圈子说客套话、加冗余解释,把简单的“是”或“否”扯成几百字的小作文。我们到底在为AI的哪部分付费?这背后藏着Token的真实逻辑,还有一场关于“效率”的暗战。
很多人以为Token就是“字数”,这是最致命的误解。Token是AI理解文本的最小语义单元——它可能是一个完整的常用词,可能是生僻词拆成的片段,甚至是标点符号。比如“无恙”两个字,因为“恙”在训练语料里出现太少,会被拆成3个Token;而一串常用的短语,8个字符可能只算1个Token。
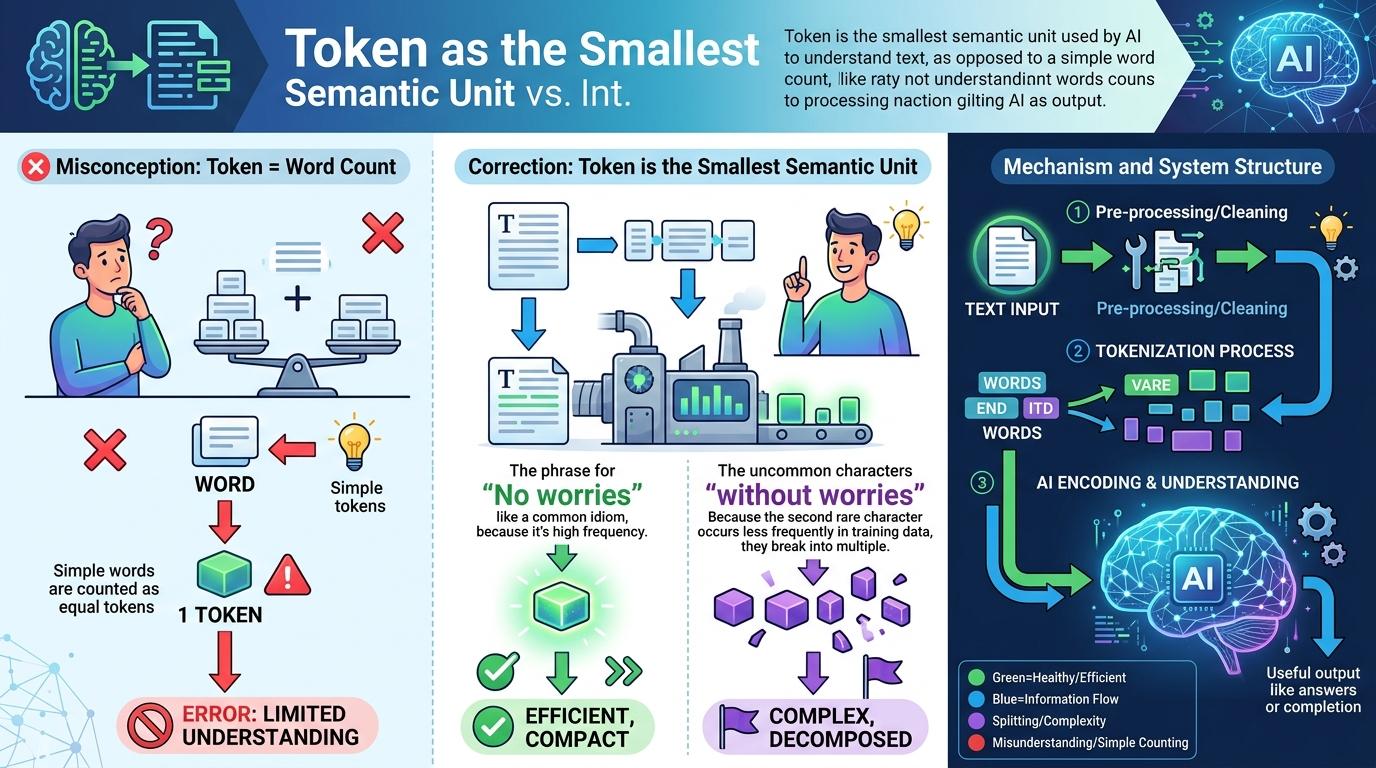
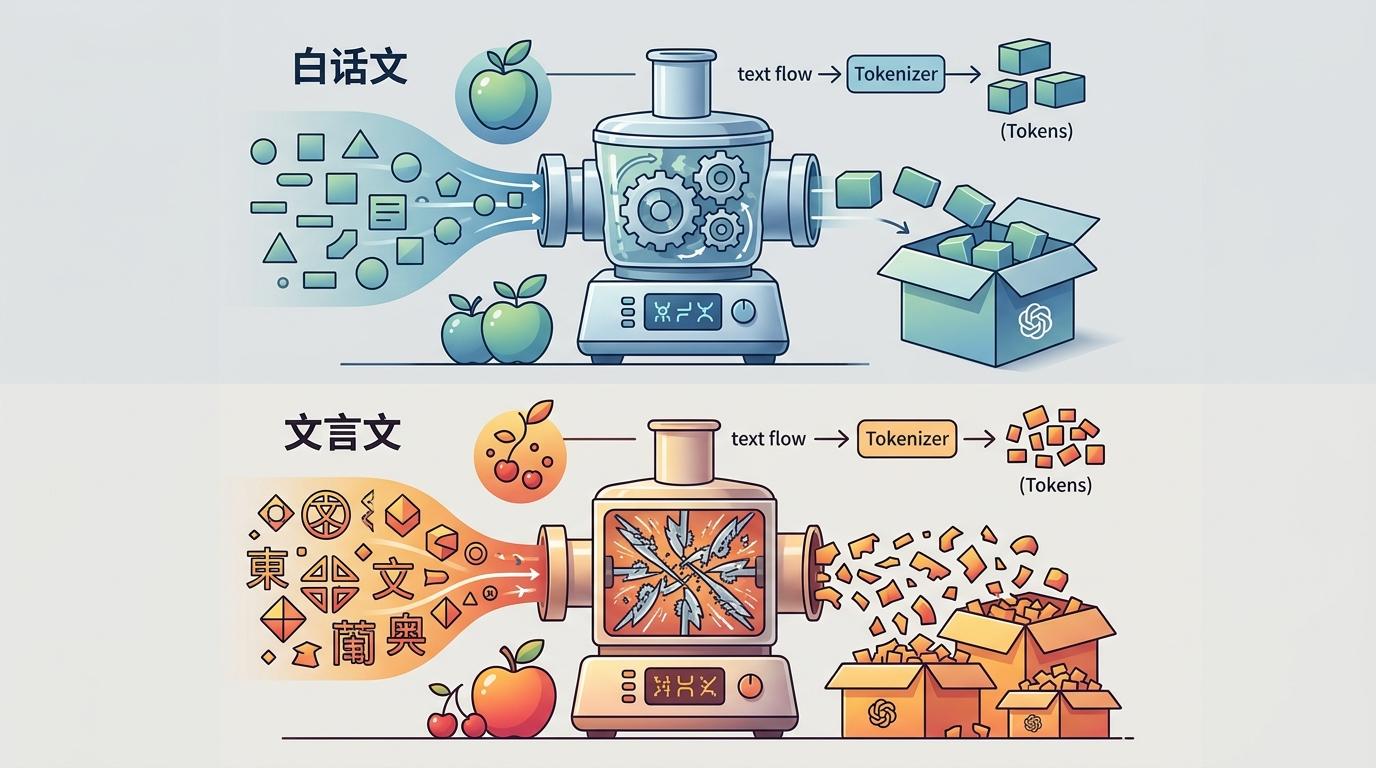
这就像你去超市买水果,不是按个数付钱,而是按“包装单位”:苹果论斤、樱桃论盒,稀有品种的小包装反而更贵。AI的分词器就像打包员,常用词会被打成大包装(1个Token),生僻词只能拆成小份(多个Token)。文言文之所以不省钱,是因为里面的生僻词太多,拆出来的小包装比白话文的大包装还多。
更关键的是,输出Token的价格是输入的3到8倍——因为生成文本需要的算力,比读取文本要高得多。你花1块钱让AI读一段文字,可能要花5块钱让它写回复,而那些客套话、冗余解释,全是你掏钱买的“无效包装”。
大模型的“啰嗦”不是天性,是训练出来的。为了符合人类的“礼貌预期”,训练师会偏好更详尽、更委婉的回答,结果AI学会了用冗余内容掩盖不确定性——说得越多,越不容易出错,却把成本转嫁给了用户。
但2026年3月的一篇论文推翻了这个逻辑:强制大模型输出简洁回答,不仅没让它变笨,反而在数学推理等任务上准确率提升了26个百分点。就像考试时,直接写答案比绕圈子写废话更不容易出错。
有人把这个发现做成了工具——比如Caveman技能,它让AI用“穴居人”的方式说话:去掉所有客套话、冠词和模糊表达,只说核心内容。测试显示,它能把输出Token压缩65%,同时保持100%的准确率。还有Zoom提出的“草稿链”策略,让AI像人类解数学题那样,只写关键步骤和公式,不用解释每一步的思路,Token消耗最低只有传统“思维链”的7.6%。
这些方法的本质,是把AI从“讨好人类的聊天机器人”拉回“解决问题的工具”——去掉所有不必要的“包装”,只给你最核心的“商品”。
除了用工具强制AI简洁,普通人也能靠改变习惯省Token。比如:
这些技巧加起来,能让Token消耗降低40%到70%——相当于你原本能和AI聊10次,现在能聊20次,而体验几乎没差别。
从短信时代的“惜字如金”,到AI时代的“Token省着用”,人类对“高效沟通”的追求从来没变过。我们不是要回到用文言文交流的年代,而是要重新定义和AI的关系:它不是用来聊天的朋友,而是解决问题的工具——工具不需要客套,只需要精准。
更值得关注的是,Token的成本逻辑正在改变AI的进化方向。过去我们追求“更大的模型、更长的上下文”,现在开始转向“更高效的Token、更精准的输出”。当Token越来越值钱,“用最少的Token解决最多的问题”会成为AI的核心竞争力。
每个Token,都要换对等的价值。 这不仅是省钱的技巧,更是我们和AI相处的新准则。