对抗知识焦虑,从看懂这条开始
App 下载
AI视频生成的核心:从单模态到多模态的跃迁
创作者意图复刻|多模态信号|AI视频生成|DiT技术架构|AI短片《纸手机》|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载创作者意图复刻|多模态信号|AI视频生成|DiT技术架构|AI短片《纸手机》|多模态视觉|人工智能
2026年春,一部5分钟的AI短片《纸手机》在全网播放破亿。观众被小男孩用15块钱给奶奶烧“纸手机”的故事戳中,更惊讶于AI生成画面里的烟火气——角色的眼神、老房子的木纹、烧纸时飘起的灰,每一处细节都像真人拍摄。没人会想到,这背后是AI视频生成技术的一次关键转向:从靠文字“脑补”画面,到用多模态信号精准“复刻”人类的创作意图。而这一切的起点,是一个被称为DiT的技术架构,和一场关于“如何让AI听懂创作者”的革命。
你可以把早期的AI视频生成模型想象成一个只会听模糊指令的实习生——你说“拍一个老人在厨房做饭”,它可能给你一个年轻人在客厅炒菜的画面,甚至锅铲会突然消失。这是因为传统模型用U-Net架构,只能捕捉局部像素的关联,像盲人摸象一样拼凑画面。
而DiT(扩散变换器)架构的出现,把实习生变成了能看懂分镜头脚本的助理。它把视频拆成一个个时空“补丁”,就像把电影剪成一帧帧画面,再给每个画面标上时间和空间标签。通过Transformer的自注意力机制,DiT能记住“老人的脸在第1帧到第10帧都要一致”“厨房的窗户始终在画面左侧”,甚至能捕捉“翻炒时菜的弧度”这种细微动作。
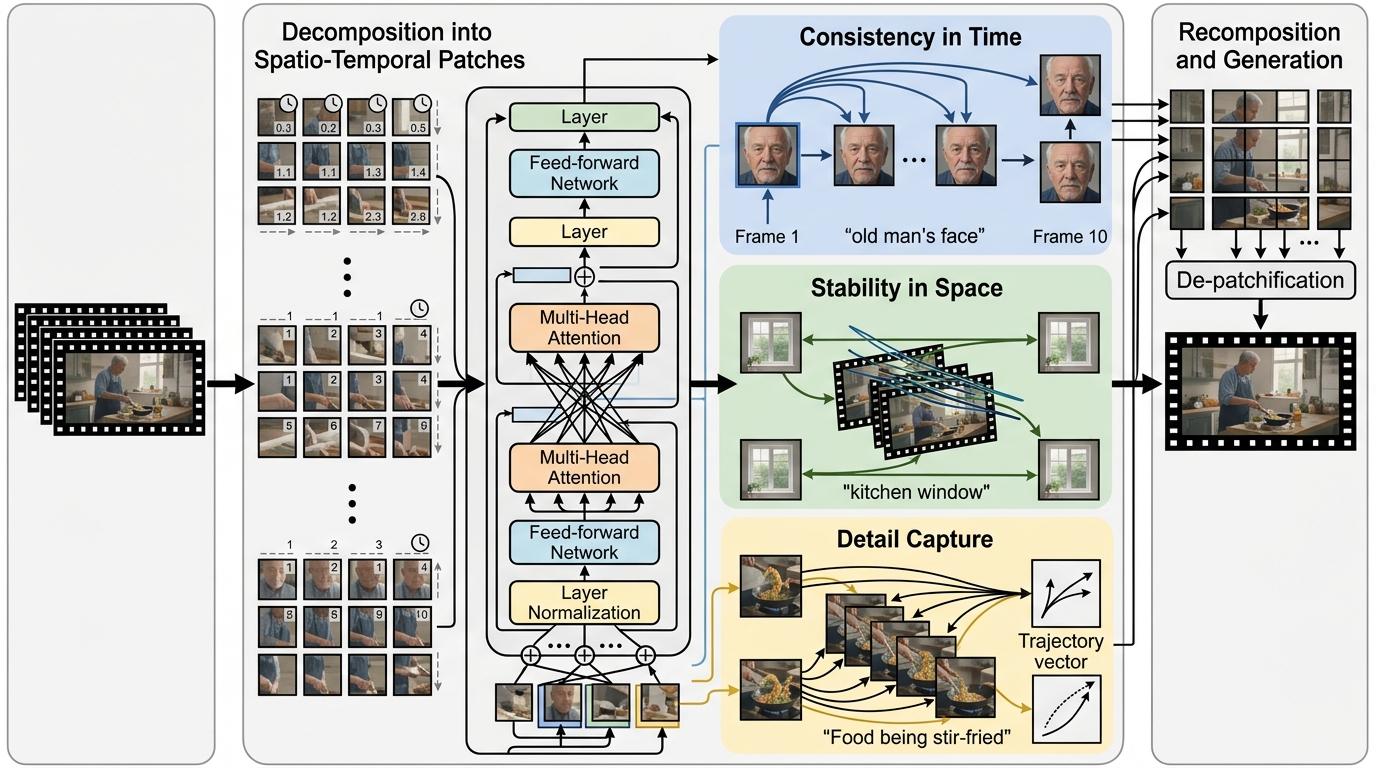
简单说,U-Net是“见招拆招”,DiT是“全局统筹”。这就是为什么《纸手机》里的小男孩从开头到结尾都是同一张脸,奶奶的皱纹在不同镜头里能对应上——DiT让AI第一次拥有了“长时记忆”和“空间感知”。
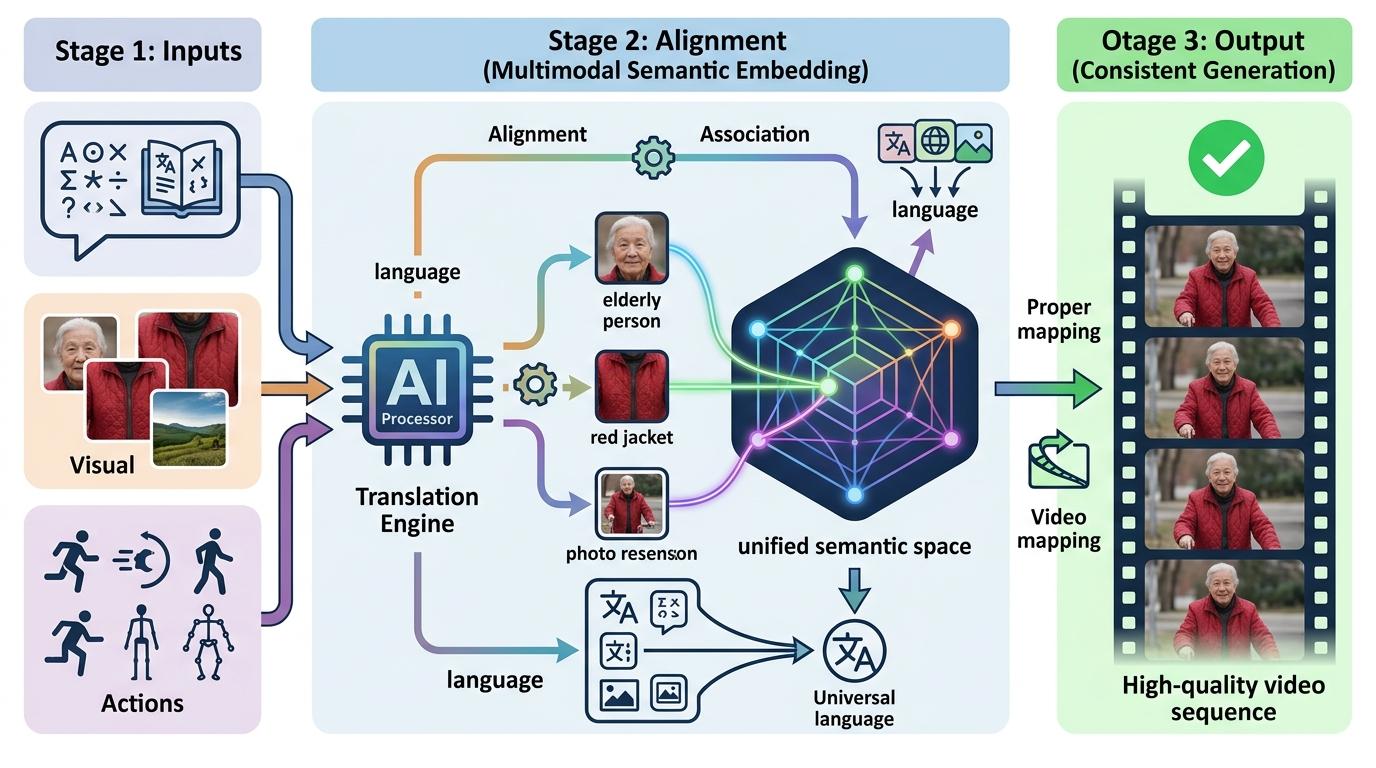
但光有记忆还不够。你试过用文字描述一个人的眼神吗?“悲伤但带着倔强”——这种模糊的感受,AI根本听不懂。这就是多模态架构要解决的问题:它让AI不仅能读文字,还能看参考图、听声音、甚至理解动作轨迹。
比如你想让AI生成一段“小女孩跳皮筋”的视频,不用费劲描述“脚怎么勾皮筋”“手怎么摆动”,只要上传一段跳皮筋的参考视频,或者用鼠标画个简单的动作轨迹,AI就能精准复刻动作。更高级的模型甚至能把“动作”当成独立的模态:你输入“快乐地奔跑”,它能理解“快乐”对应的肢体语言——脚步轻快、手臂摆动幅度大,而不是机械地迈腿。
这背后的逻辑是“模态对齐”:AI把文字、图像、动作都转换成统一的“语义语言”,就像把中文、英文、日文都翻译成世界语。当你说“穿红色外套的老人”,再配上一张老人的照片,AI会把文字的“红色外套”和照片的“人脸”对齐,生成的视频里,老人的脸和外套颜色都不会出错。
当然,这一切也有局限。目前AI还很难生成两个角色真实的物理交互——比如两个人摔跤,他们的身体碰撞、受力变形,AI还做不到完全真实。这也是为什么现在的AI视频大多是“单主角特写”,复杂场景的生成还在摸索中。
现在的AI视频生成模型,正朝着“All-in-One”统一架构进化。简单说,就是一个模型搞定所有事:从文字生成视频,到给视频换背景、改动作、加配音,甚至直接生成一整段带音效的短片。
这就像把编剧、导演、摄影师、剪辑师、配音演员都装进了一个盒子里。你输入一个故事大纲,它能直接生成分镜头脚本,再根据脚本生成视频,甚至能自动配上合适的背景音乐和台词。而这一切的核心,是“潜在空间”的设计——AI把视频、音频、图像都压缩到同一个低维空间里处理,就像把所有食材都放进同一个厨房,厨师能随意搭配做出不同的菜。
但统一架构也面临着巨大的工程挑战。比如生成长视频时,AI需要记住几十分钟的剧情和角色,这对算力和内存的要求极高;还有多模态数据的质量问题——如果训练数据里的视频和文字不对齐,AI就会生成“驴唇不对马嘴”的内容。更不用说版权和伦理问题:AI生成的视频如果用到了真实人物的脸,或者模仿了某个导演的风格,算不算侵权?这些都是技术之外需要解决的问题。
当我们为《纸手机》里的细节感动时,其实是在见证一场“工具革命”——AI正在把视频创作的门槛从“专业团队”拉低到“普通人”。未来,你可能不需要会用摄像机、剪辑软件,只要能说出你的想法,AI就能帮你变成视频。
但我们也要清醒:AI是工具,不是创作者。它能帮你把脑海中的画面变成现实,但真正能打动人心的故事,还是来自人类的情感和经历。AI放大创意,而创意源于人。当AI的画笔越来越精准,我们更要守住的,是自己作为创作者的“初心”——那些关于爱、离别、成长的故事,才是视频真正的灵魂。