
19 小时前
19 小时前
想象一下:你手里有张30米分辨率的模糊土地图,只能看出哪儿是一大片绿,哪儿是一大片蓝;同时还有张1米精度的航拍高清大图,细节清晰到能看见田埂。现在要把模糊地图变成和航拍图精度匹配的高清分类图,传统做法是拿模糊图当标签,花几小时训练一个上千万参数的大模型——但北京外国语大学的团队说,不用这么麻烦。他们只用4千个参数,花18分钟,就做出了精度媲美主流模型的高清土地覆盖图。这不是小优化,是直接换了个游戏规则。
要理解这个突破,得先掰明白传统方法的死穴:为了把模糊标签变成高清地图,你得训练一个能「学习从低精度到高精度映射」的大网络,参数动辄千万级,训练一次要占满GPU好几个小时。而且换个区域就得重新训一遍,成本高到让很多小机构望而却步。
MapSR的思路相当于直接掀了这张桌子:我们不训大模型了,直接用别人训好的「视觉大脑」——比如Meta的DINOv2,这是个在海量图像里自学出强大语义识别能力的模型,能从航拍图里精准提取出「森林纹理」「水域反光」这类特征。我们把这个大脑的参数「冻结」,不让它乱动,相当于借了个现成的智慧库。
那模糊标签用来干嘛?它不再是训练模型的教材,而是一本一次性的「说明书」:告诉我们在DINOv2提取的特征空间里,哪堆特征对应「森林」,哪堆对应「农田」。整个过程只需要训一个4千参数的线性探针——本质就是个简单的分类器,18分钟就能在单张RTX 4090上完成。
整个流程像搭积木一样清晰,没有多余的步骤:
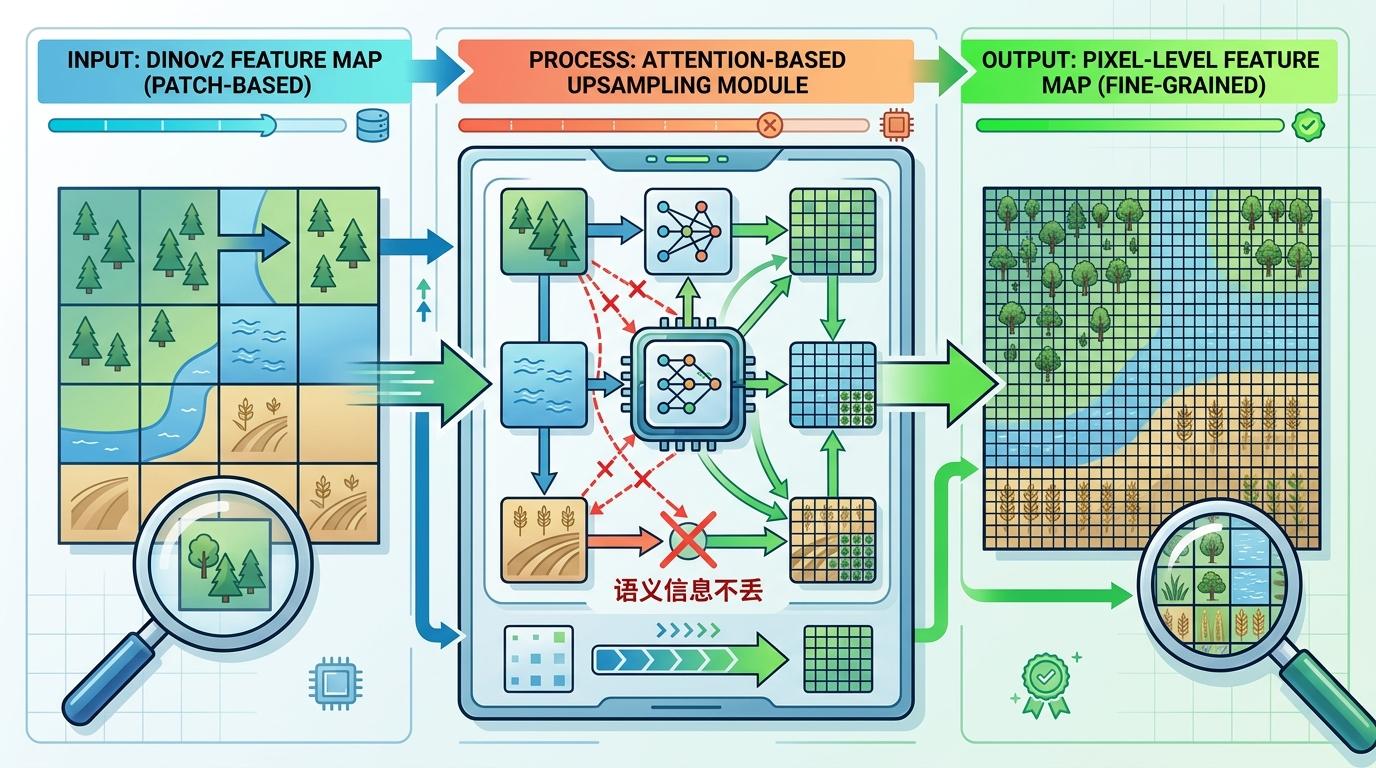
第一步是「把特征掰碎到像素级」。DINOv2原本是按块提取特征的,比如16×16像素一块,这不够精细。MapSR用了个基于注意力的上采样模块,就像给模糊的拼图块补上细节,把块特征扩展到每个像素,同时还能保证语义信息不丢——比如不会把「森林」的特征错安到「农田」上。
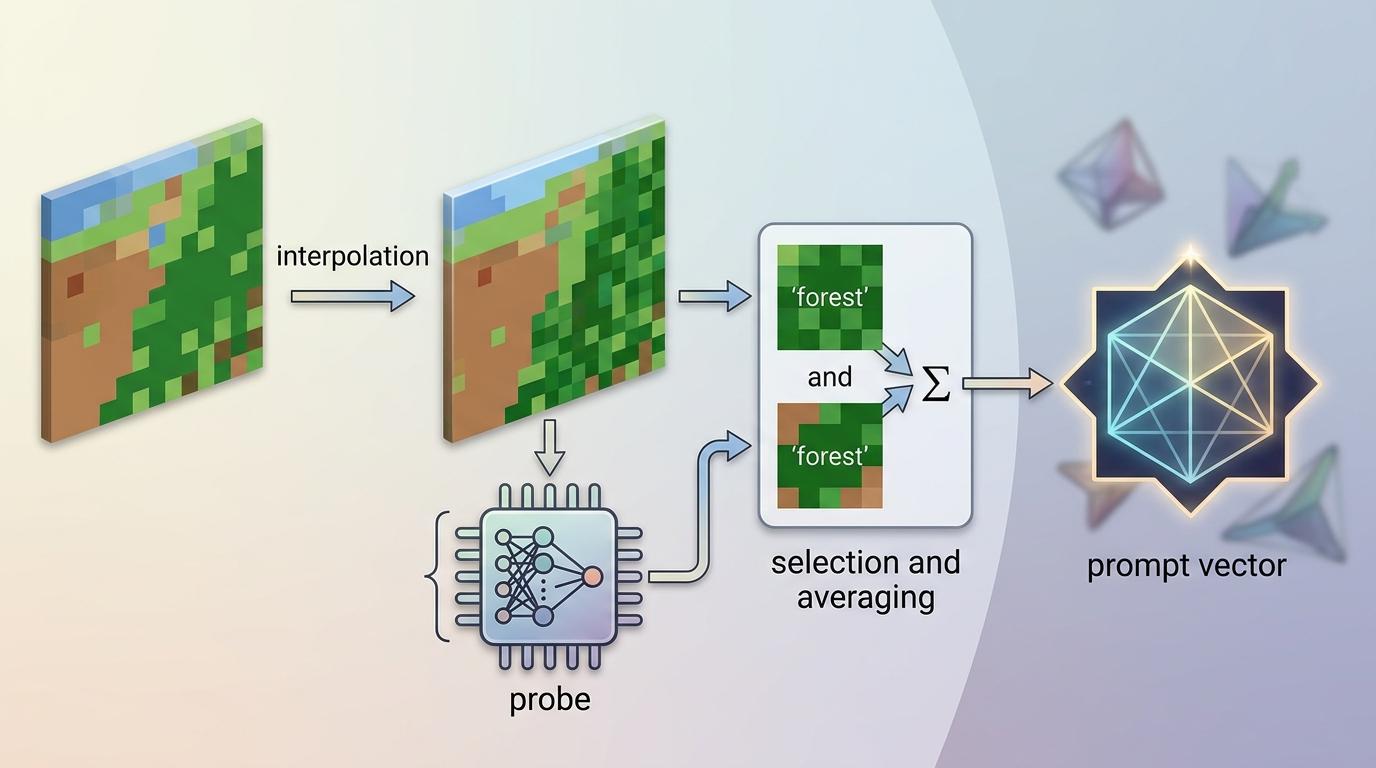
第二步是「用说明书做提示」。把低分辨率标签插值放大到高清像素,然后用那个4千参数的探针,从像素特征里筛选出「探针预测是森林,同时插值标签也标了森林」的高置信度像素,把这些像素的特征平均一下,就得到了「森林」这个类别的「提示向量」——相当于在特征空间里给每个类别拍了张标准证件照。
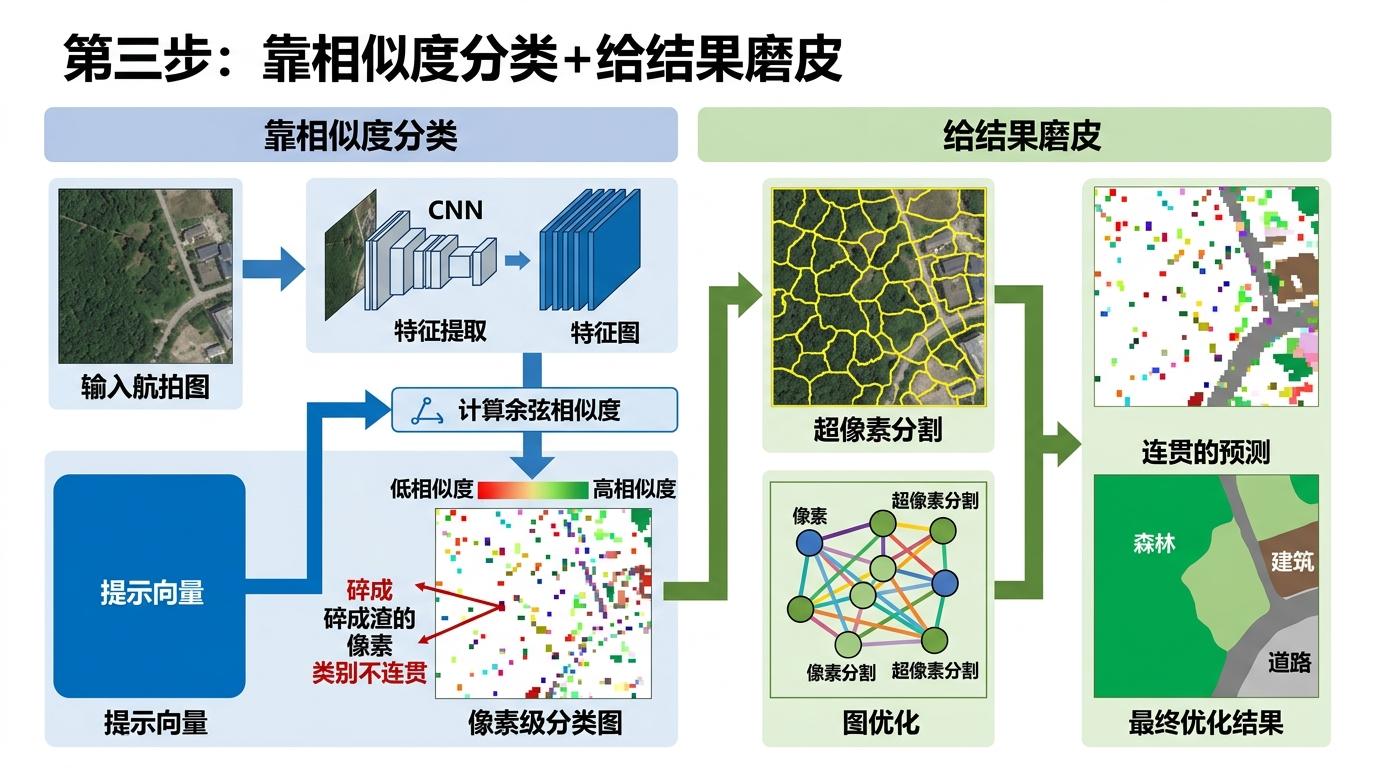
第三步是「靠相似度分类+给结果磨皮」。拿到提示向量后,再处理新的航拍图时,直接算每个像素特征和提示向量的余弦相似度,最像的就是对应的类别。最后用超像素分割和图优化给结果「磨个皮」,让同一片森林的预测更连贯,不会出现碎成渣的像素。
在Chesapeake Bay数据集的测试里,完全不用高清标注的MapSR,mIoU(衡量分割精度的核心指标)达到了59.64%,和最好的弱监督模型持平,还超过了部分全监督模型。
当然,这个方法也不是完美的。最明显的问题是「时间差陷阱」:如果低分辨率标签是2020年的,而航拍图是2025年的,中间这片森林可能已经被砍成了工业区,那用旧标签做的提示向量就会完全失效。目前MapSR还没解决这种跨时间的鲁棒性问题。
另外,它的性能完全绑定在基础模型上——如果DINOv2没见过某些特殊地貌,比如西北的雅丹地貌,那提取的特征本身就不准,再怎么调提示向量也没用。跨区域泛化时,可能还是得用当地的低分辨率标签重新做一遍提示,虽然比训大模型快,但也不是完全的「开箱即用」。
还有个隐性成本:推理时还是得跑DINOv2这个大模型,计算量并没有减少多少。它解决的是「训练成本高」的问题,而不是「推理成本高」的问题——对于需要实时处理的场景,比如灾害应急监测,这个瓶颈还在。
MapSR的真正意义,从来不是「用4千参数做了个地图模型」,而是它证明了:在视觉任务里,我们可以不用反复训练大模型,只需要给现成的基础模型递一本「说明书」,就能完成复杂的任务。这就像你不用重新造一辆车,只要换个导航仪就能去新的目的地。
这种「冻结基础模型+轻量提示」的范式,正在悄悄改变AI的应用逻辑——从「为每个任务训一个模型」,转向「用一个基础模型适配所有任务」。对于遥感、医学影像这种标注成本极高的领域,这可能是比「更大的模型」更有价值的突破。毕竟,AI的终极目标从来不是造最复杂的模型,而是用最简单的方法解决最实际的问题。
点击充电,成为大圆镜下一个视频选题!