对抗知识焦虑,从看懂这条开始
App 下载
不增GPU也能提算力15%,全靠这张网
集群任务效率|网络拥塞|数据传输协议|网络延迟|GPU集群|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载集群任务效率|网络拥塞|数据传输协议|网络延迟|GPU集群|AI算力|人工智能
想象一下:你手里的GPU集群明明满负荷运转,却有近两成算力被白白浪费——不是GPU不够强,是数据在传输路上堵死了。2026年的AI圈正卡在这个瓶颈上:当GPU集群从千卡扩到万卡,新增的算力根本没法线性释放,网络延迟和拥塞把GPU拖成了“等数据的闲人”。最近有两项技术直接把这个死结剪开了:一个是靠协议让数据“走小路绕堵”,另一个干脆把整个网络的“高架桥”拆了,换成了“平面快速路”。不用加一块GPU,就能让集群多跑15%的任务,还能把用户等首条回复的时间砍去近一半。
要搞懂这两项技术为什么管用,得先把网络拥塞拆成两半——这是很多人之前没搞明白的关键。
第一类是不可避免的拥塞,算是“天灾”:比如10个GPU同时给同一个目的地发数据,最后一条链路必然挤成“早高峰的地铁”,这是物理规律决定的,只能靠流量调度来缓解。
第二类是可避免的拥塞,完全是“人祸”:传统数据中心的网络像座多层立交桥,GPU之间传数据得先“上高架(Spine层交换机)”再“下匝道(Leaf层交换机)”。但AI推理的流量根本不是均匀的——有的GPU要频繁传大段的KV缓存,有的只发小指令,这种“忙的忙死闲的闲死”的流量,被立交桥的设计硬生生逼到了同几条匝道上,明明整体带宽够,局部却堵成了停车场。更糟的是,传统协议要求数据必须按顺序到达,一旦某条链路堵了,后面的数据包只能排队,最后连不堵的路也被拖慢了。
过去行业的思路都是“堵了再疏”:要么让数据绕路,要么给链路扩容。但2026年的这两项技术,直接从根上动手了。
第一个方案是**多路径可靠连接协议(MRC)**——相当于给数据开了上百条并行的小路。
传统数据传输是“单行道”,一条路堵了全完蛋。MRC让一个数据流拆成上百个数据包,同时走不同的路径,哪怕某条路断了,其他包还能继续跑,而且接收端能直接把乱序收到的包放到正确的内存位置,不用等排序。更狠的是,它直接废掉了容易引发“全网堵车”的优先级流控(PFC),改用快速重传补丢包,把故障恢复时间从秒级压到了微秒级。在OpenAI的万卡集群里,这个协议让网络利用率从70%提到了96%,相当于凭空多挤出来近三成的带宽。
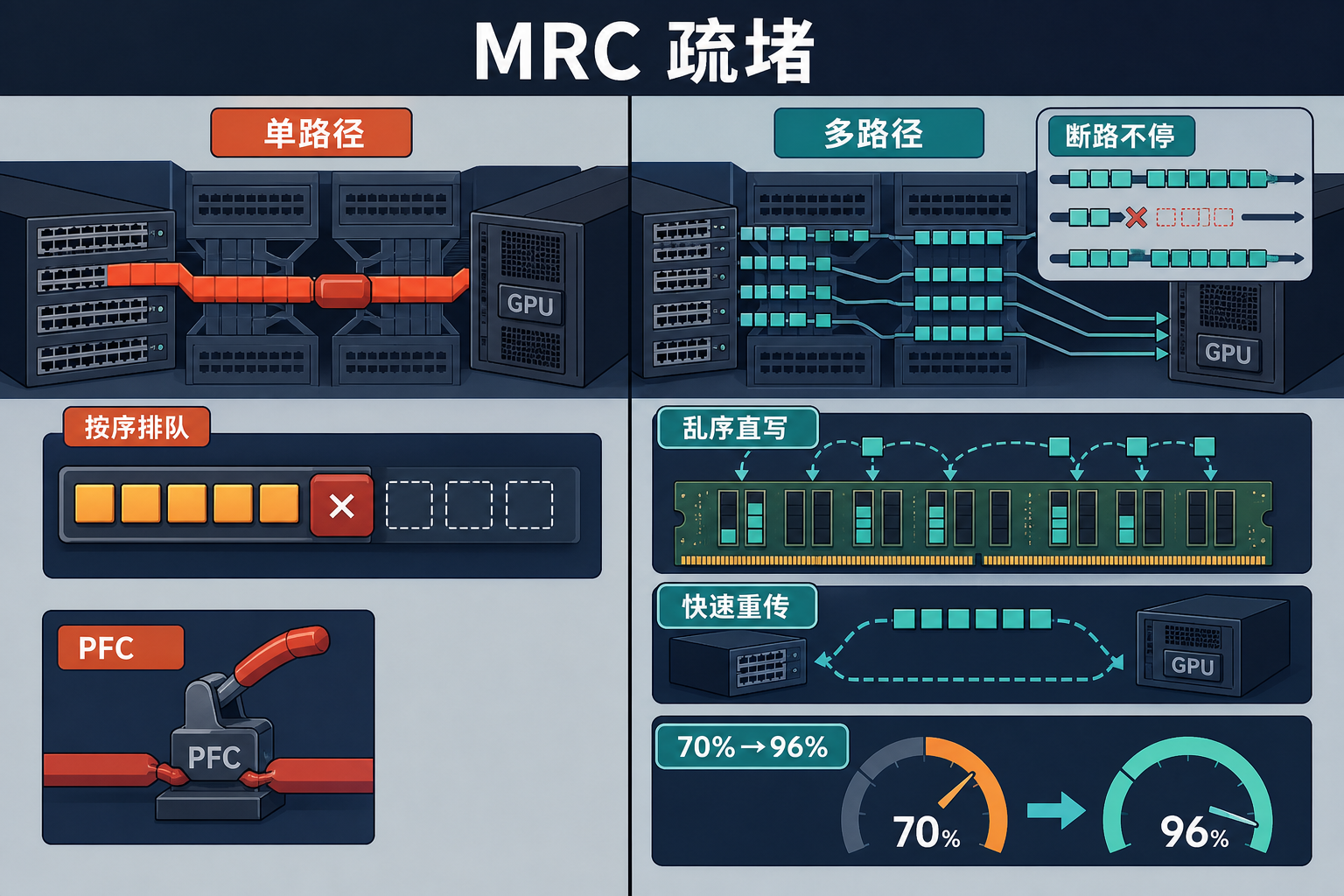
第二个方案更彻底:把多层立交桥拆成平面快速路。
传统的三层网络架构被彻底推翻,所有交换机分成两组,像棋盘的黑白格一样两两互联,GPU之间传数据最多只需要经过两台交换机,比原来少了一跳。更巧妙的是,每张GPU的两个网卡,一个“绑定”固定的交换机,另一个“打散”接入不同的交换机,这样任意两个GPU之间都有且只有一条最短路径——不用再纠结走哪条路,也不会出现多条路抢资源的情况,从架构上就把“可避免的拥塞”掐死了。
在千卡级的实际测试里,这套架构让推理吞吐直接涨了15%,首Token响应的尾延迟降了40.6%,还能少买三分之一的交换机和光模块——相当于花更少的钱,让GPU从“等数据”变成了“满负荷干活”。
这两项技术还有一个共同的信号:以太网正在把AI网络的“老霸主”InfiniBand拉下马。
过去InfiniBand靠低延迟、零丢包垄断了高端AI集群,但它是个封闭的生态,价格贵,只能绑定特定硬件。而MRC和扁平化架构都是基于开放的以太网标准,现在的以太网芯片已经能做到和InfiniBand差不多的延迟,还能靠更高的端口密度和更便宜的成本,支撑起十万卡甚至更大的集群。
更重要的是,以太网的开放生态让更多玩家能参与进来——不再是一家公司说了算,从交换机到光模块,整个产业链的成本都能降下来。比如现在已经有厂商把800G的网卡拆成8个100G端口,用多平面设计实现更高的容错率,成本却只有InfiniBand的一半。
当然,这套方案也不是没有局限:扁平化的网络需要更多的光纤布线,对数据中心的物理空间要求更高;MRC的多路径传输对网卡的计算能力也有要求,不是随便拿个旧网卡就能用。但这些都是工程问题,而非原理瓶颈。
当大家都在抢GPU的时候,有人转头把网络的“高速公路”重修了一遍。这背后其实是AI基建的逻辑变了:从“堆硬件”转向“提效率”。
过去我们以为,AI的瓶颈永远在算力——GPU越多,模型就越大,速度就越快。但现在发现,当GPU多到一定程度,网络就成了“木桶的短板”:你给木桶加了更长的木板,却没把桶底的漏洞补上。
算力的极限,其实藏在看不见的网里。未来的AI集群比拼的不再是谁的GPU更多,而是谁能让每一块GPU都跑满效率;不再是谁的链路更宽,而是谁能让数据走得更聪明。当十万卡、百万卡的集群成为常态,今天的这两项技术,可能就是未来AI基建的“标准配置”。