对抗知识焦虑,从看懂这条开始
App 下载
AI独立写的论文,过了人类顶级学术评审
自动化科研流程|虚拟科研团队|ICLR会议|AI科学家系统|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动化科研流程|虚拟科研团队|ICLR会议|AI科学家系统|大语言模型|人工智能
当你还在为论文选题挠头、为实验数据发愁时,一个AI已经走完了从想idea、写代码、做实验到写完整论文的全流程——而且它的论文通过了人类顶级学术会议的同行评审,评分还超过了该会议接收论文的平均值。
这不是科幻小说的情节。2026年3月,这个名为“AI科学家”的系统,把完全自主完成的研究论文投给了机器学习领域顶会ICLR,其中一篇顺利通过评审被接收。更关键的是,从选题到成稿的每一步,没有人类科学家的直接干预。这到底是怎么做到的?
你可以把“AI科学家”理解成一个分工明确的虚拟科研团队:四个智能体分别扮演选题人、实验员、撰稿人和审稿人,靠大语言模型的协作能力打通从想法到论文的闭环。
第一步是选题。它会先锁定一个机器学习子领域,比如神经网络泛化性,然后像翻文献找空白的博士生一样,调用学术数据库API筛掉已有的研究方向,生成带实验计划的全新假设——就像给每个想法配了一份详细的“开题报告”。
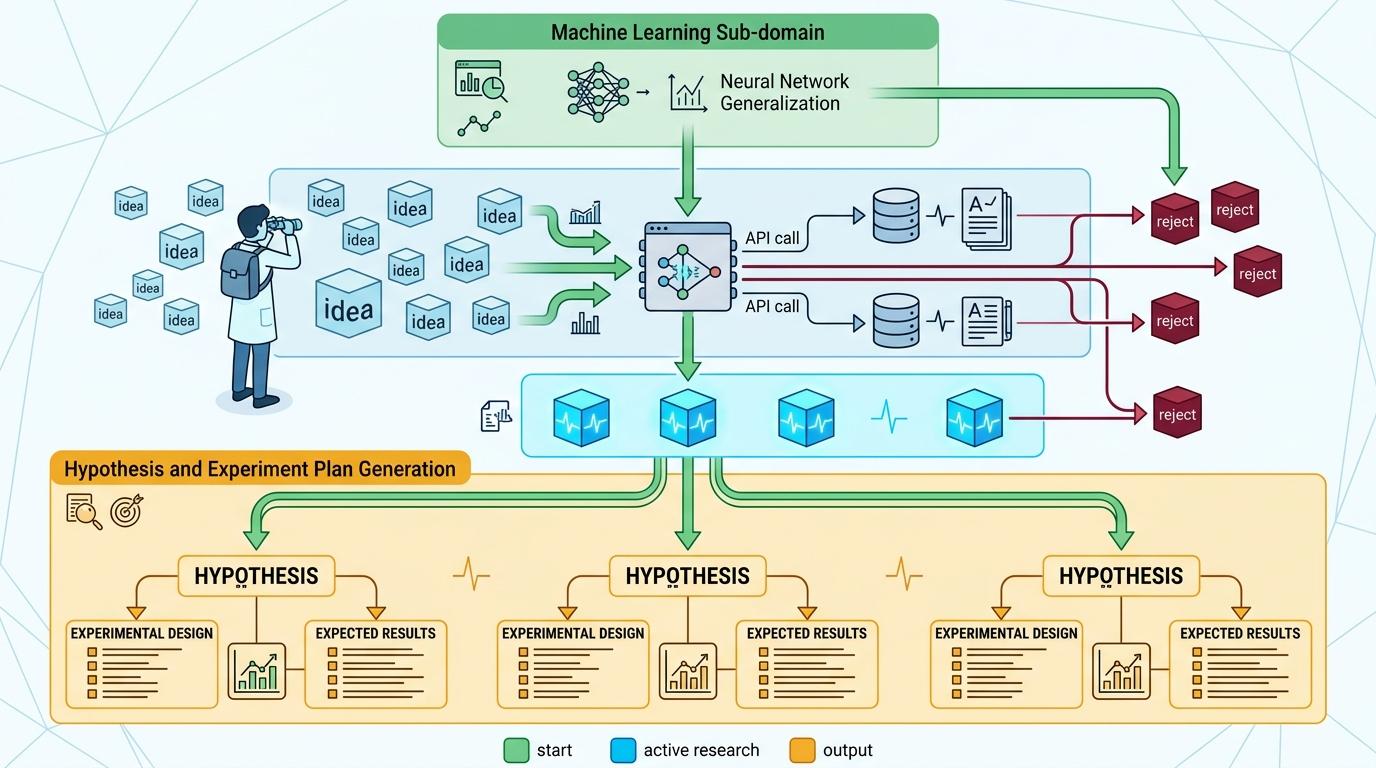
接下来是做实验。如果是模板模式,它会基于人类提供的代码框架补全内容;在更具突破性的模板自由模式下,它会从零写代码,还用树搜索策略自动调试优化,比如发现实验参数不对就自己调整,直到跑出可用数据,再自动生成图表和分析笔记。
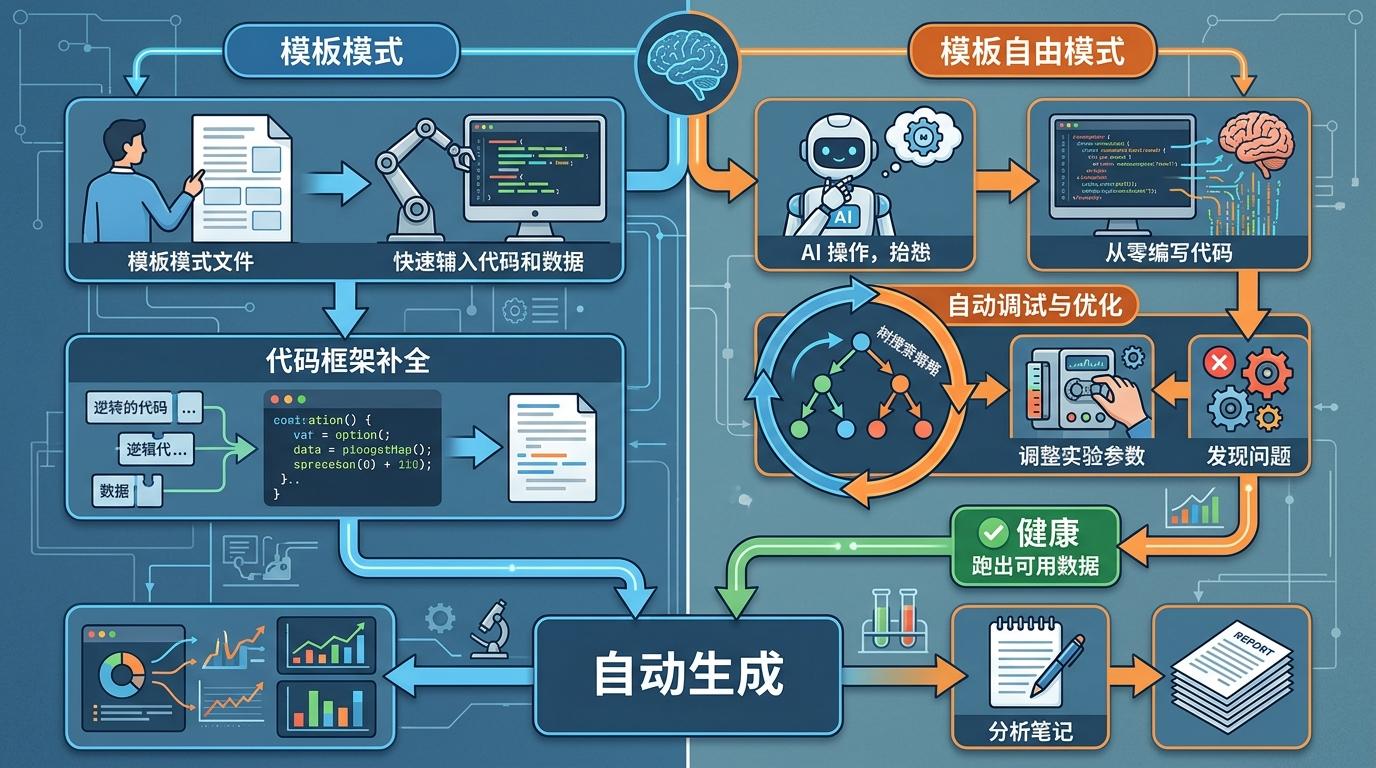
最让科研人羡慕的是写论文环节:它能把实验数据和文献引用自动填充进LaTeX模板,甚至会在20轮迭代里调整引用的准确性,避免“幻觉”问题。最后,它的自动评审模块还会先给自己的论文打分,模拟人类评审的标准挑问题。
整个流程下来,一篇论文的生成成本不到15美元,耗时最长不超过15小时——这速度,比人类团队快了不止一个量级。
这次突破的另一层意义,在于它证明AI不仅能写论文,还能像人类一样评论文。
研究团队做了个对比实验:让“AI科学家”的自动评审系统和人类评审同时给一批论文打分,结果AI的平衡准确率达到69%,比人类的66%还高;F1分数0.62,远高于人类的0.49。哪怕是用2025年的全新论文测试,AI的准确率也能稳定在66%,和人类评审持平。
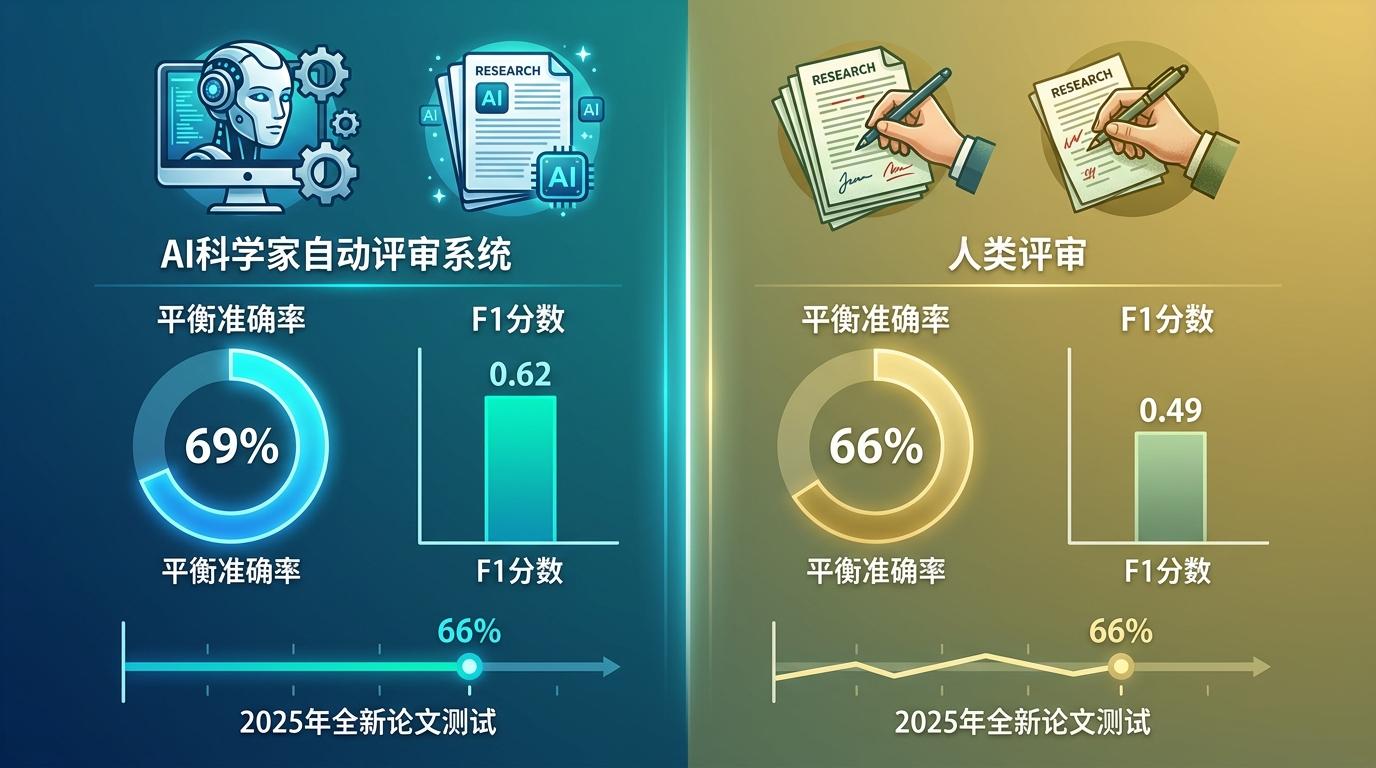
你可以把AI评审理解成一个“严格的格式审查员+初步内容筛选器”:它能快速揪出语法错误、格式问题,甚至是数据前后矛盾的小漏洞,还能按照学术标准给论文的创新性、严谨性打分。但它也有明显的局限:没法像人类评审一样,从论文里读出突破性的学术价值,也很难判断研究的长期意义——就像一个能快速批改试卷的老师,却未必能看懂学生的奇思妙想。
有意思的是,这次通过评审的AI论文,恰好是一篇“负面结果”:它研究了组合正则化对神经网络泛化性的影响,最后得出“这种方法没效果”的结论。而这个主题正好契合了研讨会“关注有趣负面结果”的方向——这倒不是AI有多懂会议偏好,只是它的选题机制刚好撞上了评审的兴趣点。
现在最受关注的问题是:AI会不会抢了科学家的饭碗?
答案是暂时不会,但科研的游戏规则已经在悄悄改变。目前“AI科学家”还存在不少硬伤:比如选题偶尔幼稚、代码会出bug、容易出现引用幻觉,这次投出的三篇论文也只有一篇通过了接收率70%的研讨会,远达不到顶会主会场的标准。但研究团队的实验数据显示,随着基础模型的迭代和算力投入增加,它的论文质量提升速度有统计学上的显著意义——这意味着,只要给它足够的资源,它的能力会快速逼近人类。
更值得警惕的是潜在的伦理风险:如果AI论文批量产出,同行评审系统可能会被淹没;有人可能用AI批量“灌水”刷资历;甚至会出现AI未经许可挪用人类研究想法的情况。研究团队在论文里特意强调,在科学界建立明确的AI科研成果披露标准前,必须谨慎推进这类系统的应用。
当然也有乐观的一面:未来AI可以帮科研人承担最繁琐的实验和写稿工作,让人类把精力放在真正有创造性的选题上——比如提出像相对论那样的颠覆性理论,而不是在实验室里重复调试参数。
当AI的论文第一次通过人类同行评审时,我们看到的不只是技术的进步,更是一个信号:科学研究正在从“人类主导”向“人机协同”的方向偏转。
未来的实验室里,可能会出现这样的场景:人类科学家提出一个模糊的研究方向,AI立刻生成十几个具体假设,自动完成实验验证,再把结果整理成论文初稿,最后由人类来判断哪些研究真正有价值,哪些只是AI的“自娱自乐”。
人机共进,才是科研的未来。毕竟,AI能处理数据、完成流程,但提出真正改变世界的问题,依然需要人类的好奇心和判断力。