对抗知识焦虑,从看懂这条开始
App 下载
AI终于能说清:3D场景里它是怎么想的
可解释性AI|智能机器人|3D场景推理|北京通用人工智能研究院|SceneCOT框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载可解释性AI|智能机器人|3D场景推理|北京通用人工智能研究院|SceneCOT框架|多模态视觉|人工智能
想象你问家里的智能机器人:“客厅里能放下一张瑜伽垫吗?”它立刻回答“可以”——但你不知道它是看到了沙发和茶几的间距,还是仅凭“客厅”这个词瞎蒙的。过去的3D视觉AI就像这样:能给出答案,却拿不出推理依据,活脱脱一个“考试蒙对却写不出解题过程”的学生。直到北京通用人工智能研究院联合清北团队的SceneCOT框架出现,它第一次让AI在3D场景里的思考过程变得像人类一样清晰可查,甚至能一步步告诉你“我是怎么得出这个结论的”。
你在陌生房间找充电插座时,会先判断“这是卧室,插座大概率在墙边”,再定位到书桌附近,最后盯着墙面找插孔——SceneCOT就是把人类这套思考逻辑,变成了AI的标准流程。它把复杂的3D推理任务拆解成四个不可跳过的步骤:
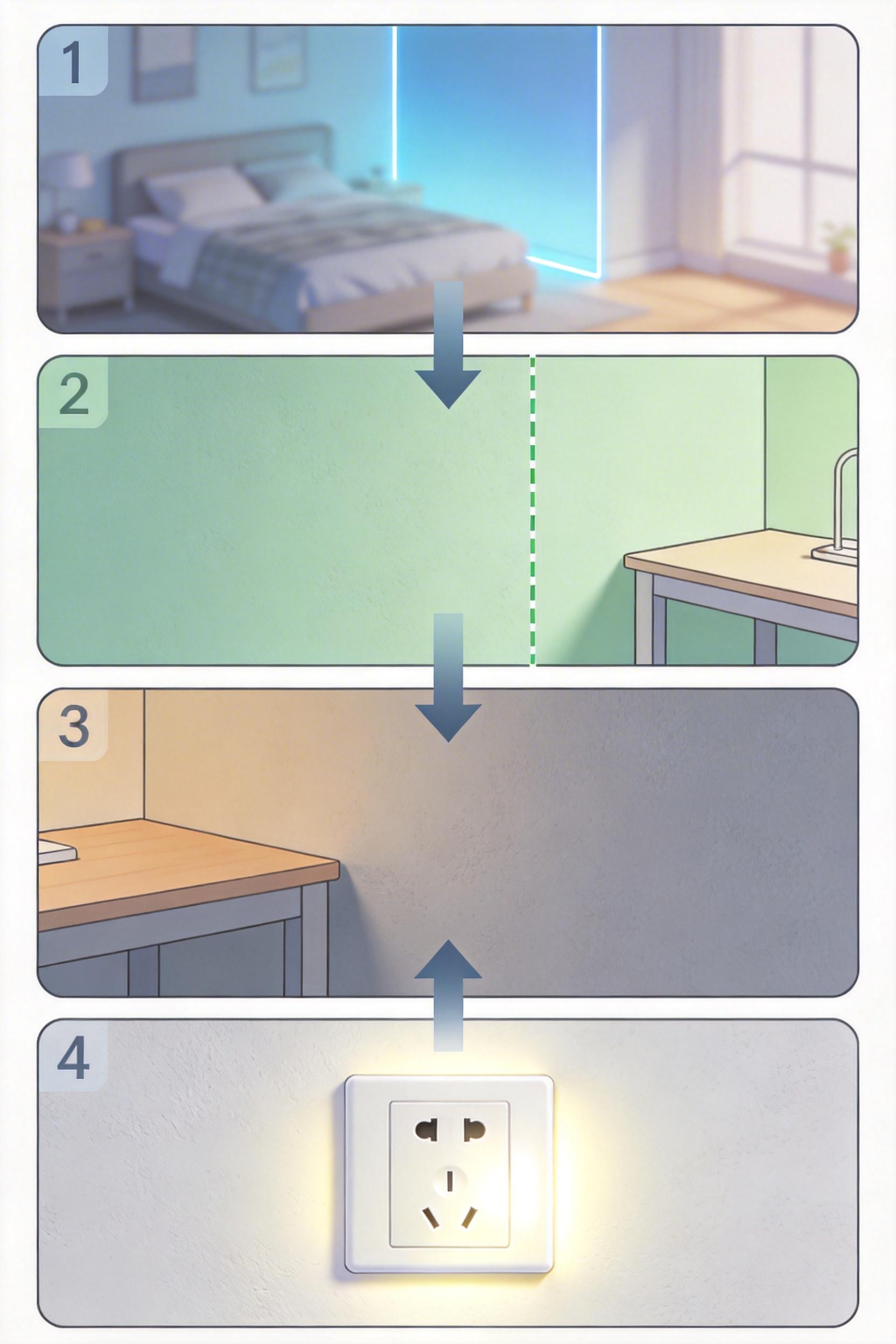
每一步都有对应的视觉证据支撑,就像写作文必须标注引用来源,彻底杜绝了AI“凭空编答案”的可能。在Beacon3D基准测试中,它的“答案-视觉一致性”得分达到34.7%,是传统模型的1.8倍——这意味着AI说“可以”时,9成以上真的是看到了足够的空间。
要让AI学会“一步步想问题”,光有框架还不够——它得先看够人类是怎么思考的。团队专门构建了SceneCOT-185K数据集,这是全球首个3D场景链式推理数据库,里面藏着18.5万条人类面对3D场景时的完整思考轨迹。
比如在MSQA数据集的一个案例里,AI要回答“房间里有多少个带抽屉的柜子”,它的思考链会清晰地写着:“任务是计数→先找房间里的柜子→定位到书桌旁的高柜、床头柜→检查每个柜子的抽屉→数出一共3个”。这些标注不是简单的问答对,而是把“为什么这么想”的过程也写了进去。
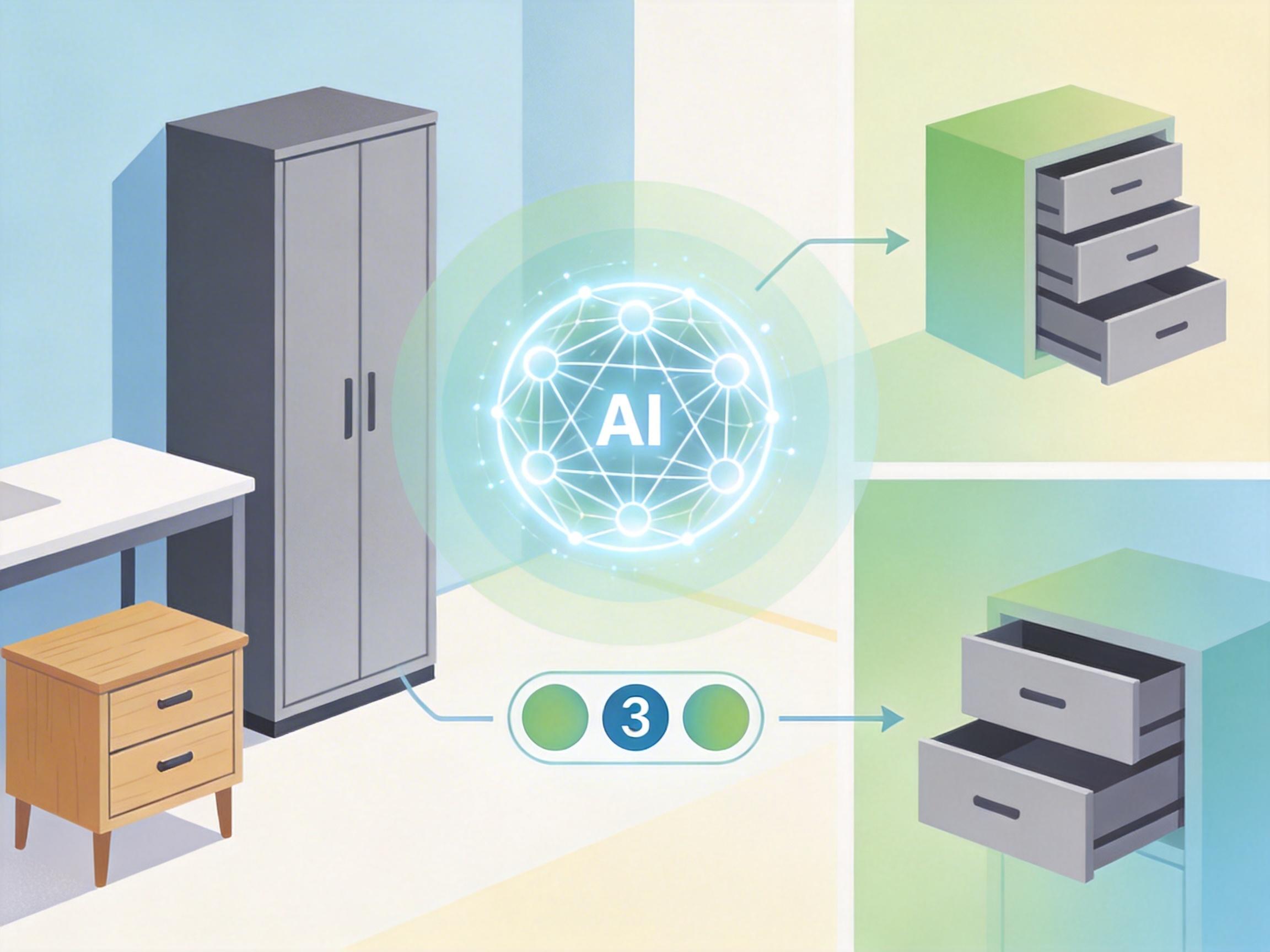
有意思的是,团队发现光靠大语言模型的“空想”还不够,必须给AI配上“3D视觉专家模块”——就像给作家配上实地考察的摄影师,让它既能“说得出道理”,又能“认得出东西”。这种“语言推理+视觉定位”的组合,让AI在计数任务上的准确率直接冲到了47.9%,比纯语言模型高出近20个百分点。
当然,SceneCOT也有局限:它目前还只擅长静态场景,要是遇到客厅里有人走动、沙发被挪动的动态情况,它的推理链条就容易断。而且它的思考步骤是固定的四步,不像人类能根据场景灵活调整——比如有时候我们会直接忽略“区域定位”,一眼就看到插座。
SceneCOT的意义不止于“让AI说清自己的思考”——它给未来的具身智能体(比如能做家务的机器人)铺了一条关键的路。过去的机器人执行“拿水杯”指令时,要么靠预设的坐标瞎撞,要么凭模糊的视觉信息乱抓,很容易把杯子碰倒。而用SceneCOT框架的机器人,会先“想”:“我要拿水杯→水杯应该在餐桌或茶几上→定位到餐桌上的玻璃杯→伸手去拿”,每一步都有视觉证据,出错的概率会大大降低。
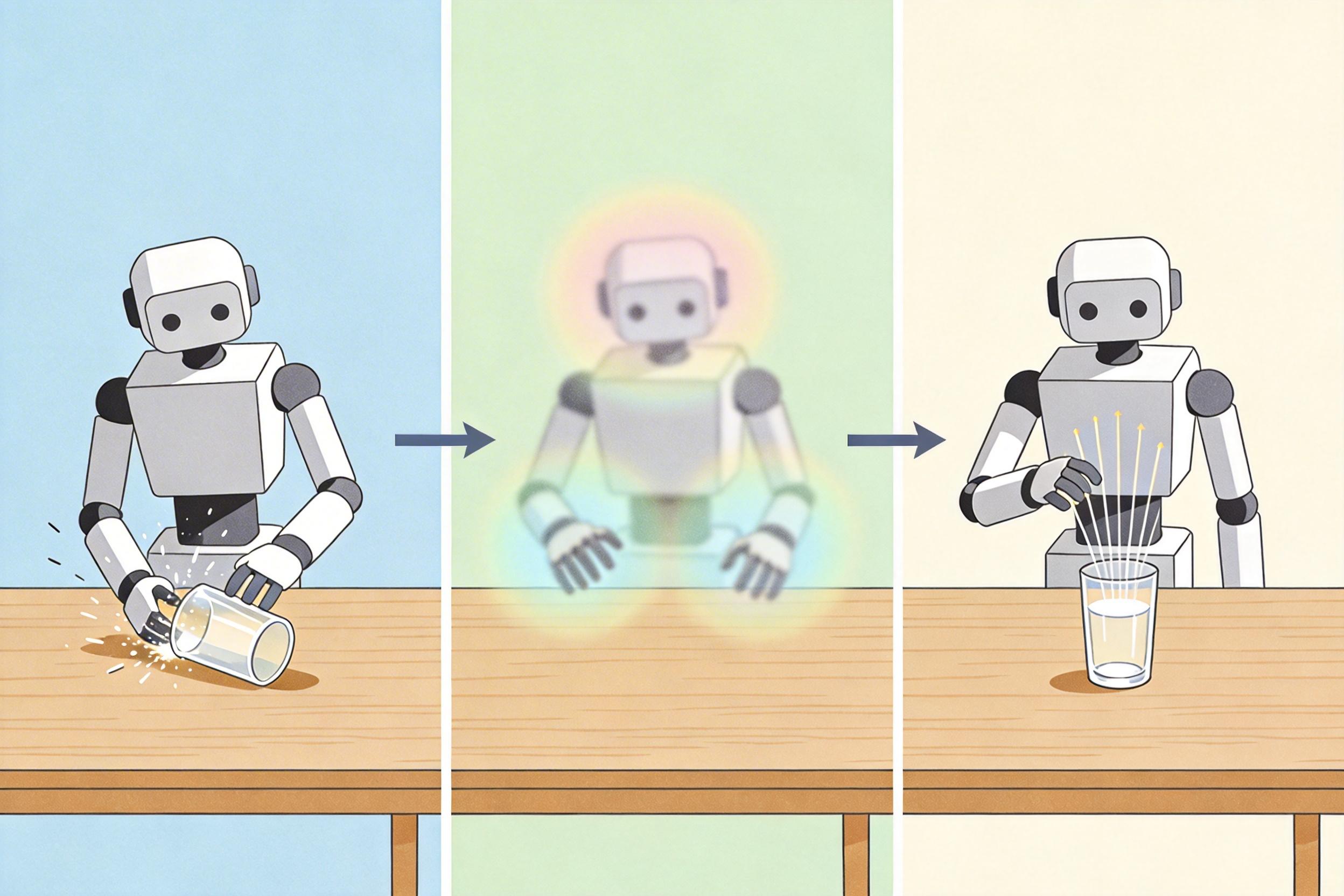
团队已经在探索下一步:用强化学习让AI学会“动态调整思考链”。比如当它发现茶几上的水杯被书挡住时,能自动加一步“移开书”,而不是卡在“找不到水杯”的死胡同里。这种“边想边做、边做边改”的能力,才是机器人真正走进人类生活的核心。
我们总说要“让AI更智能”,但很多时候,“智能”的前提是“透明”——就像你不会信任一个永远藏着解题过程的学霸。SceneCOT让AI第一次在3D世界里“摊开了草稿纸”,它的每一个结论都有迹可循,每一步推理都有证可查。
让AI会思考,先让AI会“说”思考。未来的机器人不用再做“沉默的执行者”,它会告诉你“我这么做是因为看到了什么、想到了什么”——这种“可解释的智能”,才是我们真正需要的、能放心共处的AI。