对抗知识焦虑,从看懂这条开始
App 下载
百万token本地推理成真,KV缓存是关键
超长文本处理|内存优化|本地推理|KV Cache|DeepSeek V4 Flash|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载超长文本处理|内存优化|本地推理|KV Cache|DeepSeek V4 Flash|大语言模型|人工智能
当你还在为大模型本地推理的内存限制头疼时,有人已经把2840亿参数的模型塞进了128GB内存的MacBook——还能处理百万级别的超长文本。这不是科幻场景,而是2026年DeepSeek V4 Flash带来的现实。它的核心秘密,是把过去被视为内存负担的KV Cache(键值缓存),变成了可以压缩、甚至能存进硬盘的「可回收资产」。为什么这小小的缓存技术,能打破大模型本地运行的天花板?
你可以把大模型的推理过程想象成写论文:每写一个新句子,都要反复翻看前面的内容确保逻辑连贯。KV Cache就是用来存这些「前面内容」的笔记本——传统模型会把整个笔记本都摊在内存里,句子越长,占的空间就越大,100万token的文本能吃掉上百GB内存。
但DeepSeek V4 Flash换了个思路:它把这个笔记本进行了「分层压缩」。用压缩稀疏注意力(CSA)把每4个token的内容合并成一条记录,再用高度压缩注意力(HCA)把128个token提炼成一个全局摘要,最后把整个压缩后的笔记本存进硬盘——就像把一本厚书做成了可随时查阅的电子书。
这直接把KV Cache的内存占用降到了传统模型的2%。在MacBook Pro M3 Max上,它能以250 tokens/s的速度处理1万多token的长文本,生成速度也能稳定在20 tokens/s以上。
光有缓存压缩还不够,要让2840亿参数的模型在本地跑起来,还得给模型本身「减肥」。这就用到了2-bit非对称量化技术——简单说就是只给模型的「四肢」减肥,「大脑」保持原样。
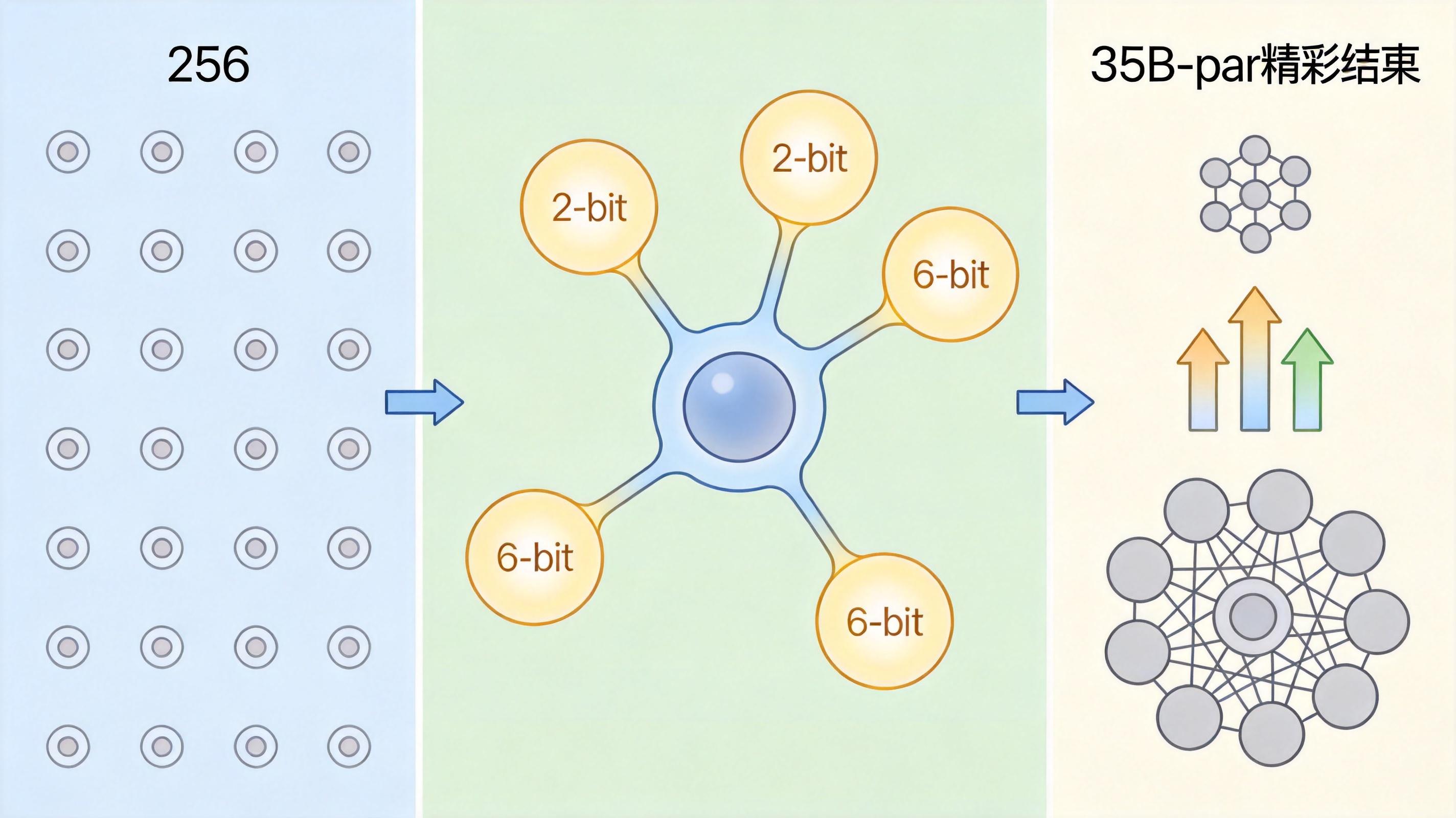
DeepSeek V4 Flash是混合专家(MoE)架构,就像一个有256个专家的团队,每次推理只会激活其中6个。研发团队只对这些被频繁调用的「一线专家」进行2-bit量化,把它们的参数精度从32位降到2位,而负责全局调度的「指挥中心」则保持全精度。这种「精准减肥」让模型体积直接缩水到原来的1/16,却几乎没影响推理质量——在代码生成、长文本理解等任务上,它的表现甚至超过了不少350亿参数的模型。
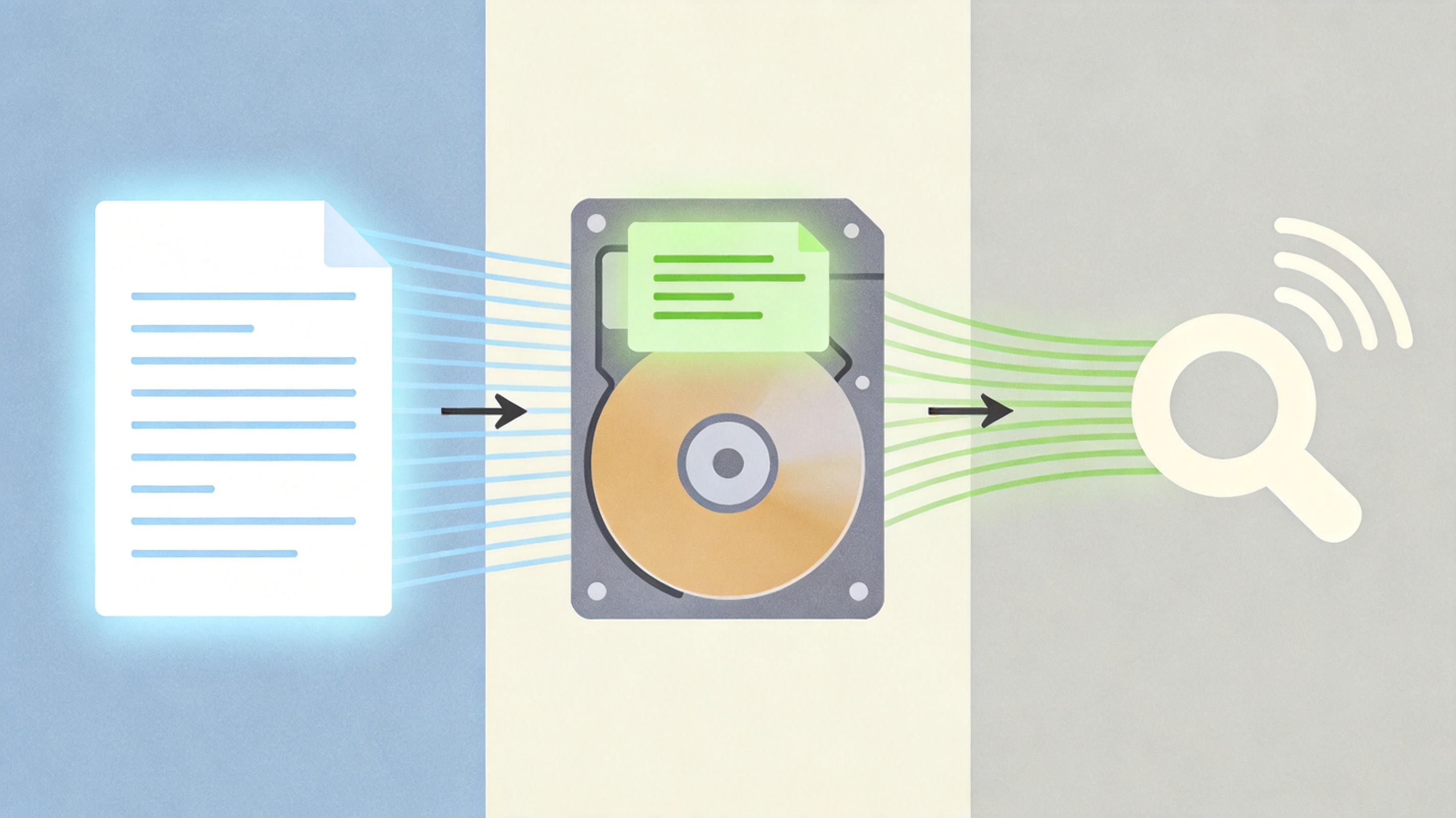
更聪明的是,它还会把常用的文本前缀缓存起来。比如你反复问同一篇文档的问题,第一次加载后,后面的请求直接调用硬盘里的缓存,不用再重新处理整个文档,速度能提升数倍。
当然,这套方案也不是没有短板。它的MoE架构比普通模型复杂得多,调试和优化的难度指数级上升;压缩后的缓存虽然能存进硬盘,但频繁读写还是会比内存慢一些;而且目前它只支持Apple Silicon的Metal平台,Windows和Linux用户还得再等等。
最关键的是,长上下文推理的「最后一公里」问题还没完全解决——模型虽然能记住百万token的内容,但在处理中间部分的信息时,准确率还是会下降,就像人读一本百万字的书,难免会忘记中间的细节。而且它的思考模式本质上是调节计算资源,并没有真正实现更智能的推理逻辑。
但这些问题都掩盖不了一个事实:它第一次让普通人能在本地设备上,用大模型处理整本书、整个代码库级别的任务。这就像第一次把超级电脑放进了个人书房,意义远不止于技术本身。
当大模型从云端走进本地,我们对AI的想象边界也在被重新定义。过去我们得把数据传到云端,才能用大模型处理复杂任务;现在我们可以在自己的电脑上,安全地处理机密文档、生成长篇代码,不用再担心隐私泄露。
「AI的未来,是在你身边的智能」。这句话正在从口号变成现实。DeepSeek V4 Flash和它的KV Cache压缩技术,不是终点,而是一个开始——它让我们看到,只要找对了方向,大模型的「平民化」其实离我们并不远。