对抗知识焦虑,从看懂这条开始
App 下载
把AI训练搬进太阳能家庭,能耗降了500倍
数据中心|通信能耗|太阳能家庭|闲置GPU|分布式AI训练|新能源|大语言模型|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据中心|通信能耗|太阳能家庭|闲置GPU|分布式AI训练|新能源|大语言模型|前沿科技|人工智能
当你家的台式机在深夜闲置时,它可能正在帮着训练一个百亿参数的AI模型——而且用的是屋顶太阳能板发的电。这不是科幻场景:2026年,已有团队把训练任务拆成无数小块,分散到全球各地的闲置GPU上,从科研实验室的休眠服务器,到郊区家庭的游戏电脑。更惊人的是,这种方式让AI训练的通信能耗直接降了500倍,还能避开传统数据中心动辄数亿度的电力消耗。这背后,是一场正在重构AI能源逻辑的革命——我们不再把能源搬进数据中心,而是让计算跑到能源身边。
你可以把传统AI训练想象成一场只能在专业体育场举办的运动会:必须凑齐一整队最顶尖的GPU,用高速网线死死连在一起,稍有延迟就会打乱节奏。但当模型规模从百亿参数跃升到千亿,哪怕是最大的“体育场”也装不下了——单是训练一次的电力消耗,就够一个普通家庭用几百年。
于是有人换了思路:为什么不把比赛搬到街头巷尾?去中心化训练就是把AI模型拆成无数个小任务,派给全球各地的“散兵游勇”——闲置的服务器、太阳能供电的家庭电脑、甚至是办公室里下班就休眠的工作站。这些节点不需要凑在一起,各自完成任务后只需要把结果汇总就行。
但真实的机制比这更精确:它不是简单的任务拆分,而是让每个节点先在本地完成几百步训练,再把参数变化同步给其他节点。这就像一群作家分头写同一本书,每写完一章再交换修改意见,而不是每写一个字都要凑在一起商量。
去中心化训练最大的难题,是节点之间的通信成本——如果每个节点都要频繁同步数据,光是网络传输的能耗就能抵消所有优势。Google DeepMind的研究者们解决了这个问题,他们开发的DiLoCo算法,把AI训练变成了“岛屿式协作”。
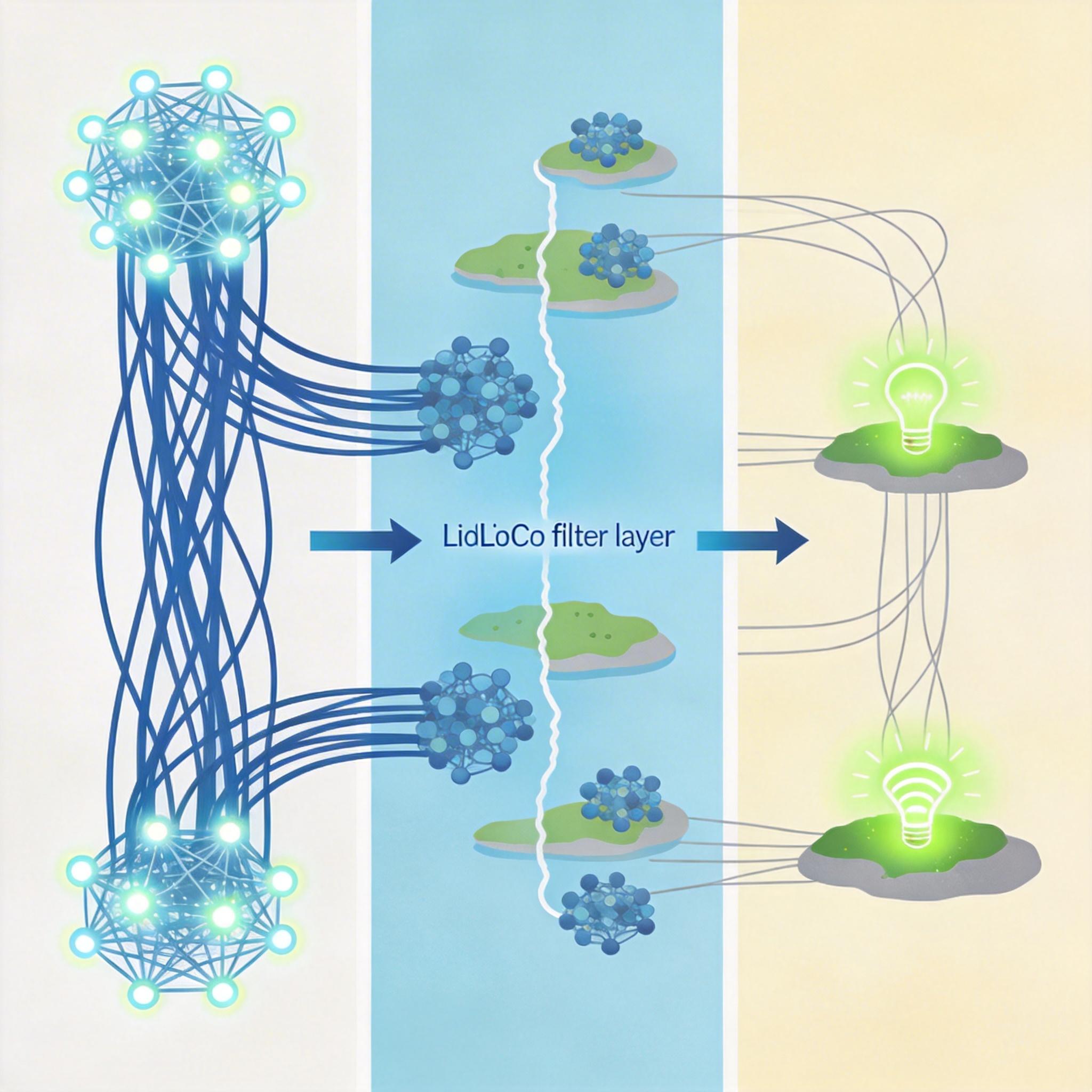
你可以把每个计算节点集群看成一个“岛屿”,岛上的电脑用同一种芯片,能高效完成本地训练。岛屿之间几乎不需要交流,只有当每个岛都完成几百步训练后,才会交换一次“知识”。实验数据显示,这种方式把通信量直接降了500倍,而模型的性能几乎没有损失。
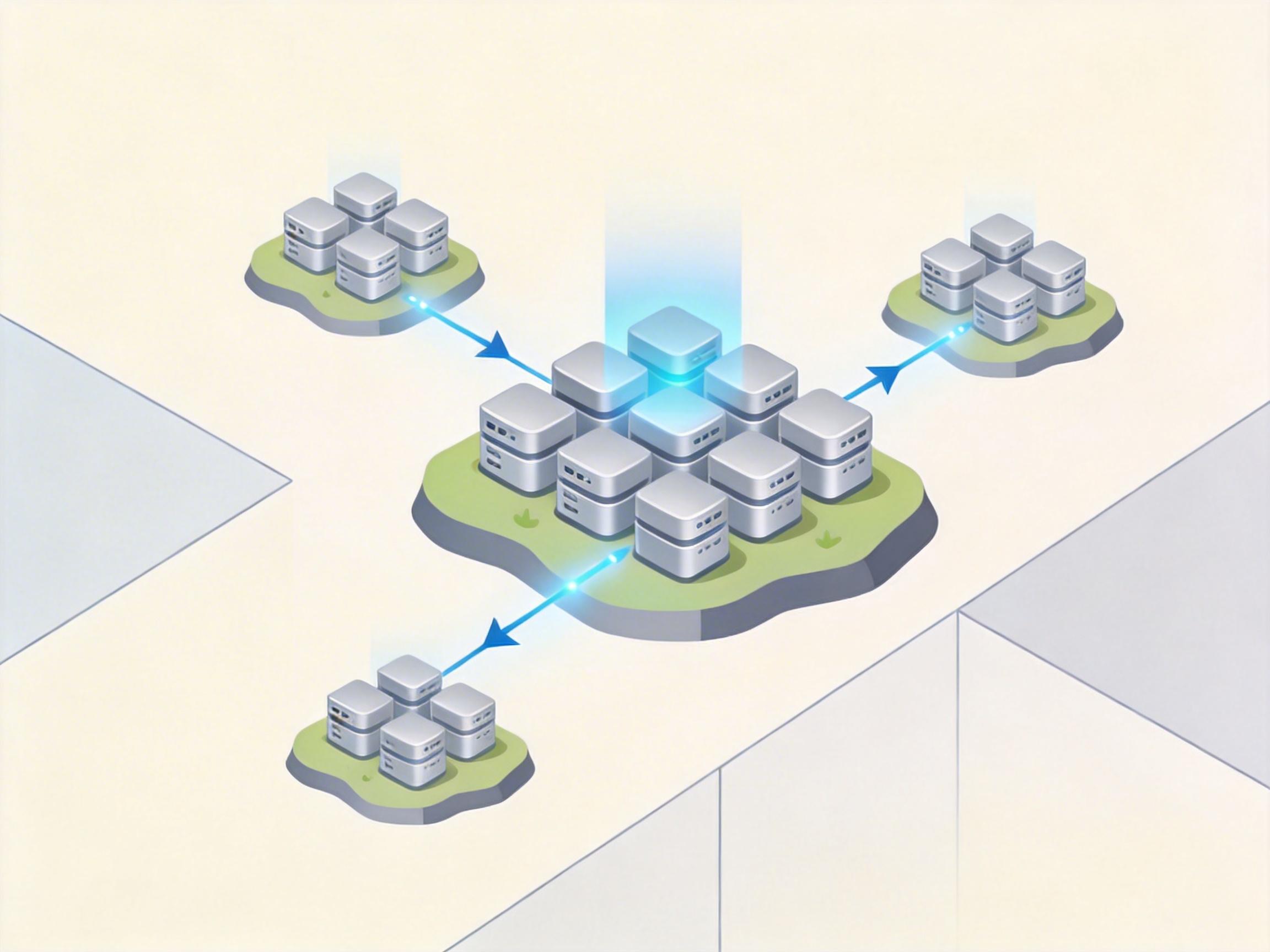
改进后的Streaming DiLoCo更像在线看视频:不需要等整个视频下载完再看,而是一边训练一边同步参数,进一步降低了带宽需求。就像你在写论文时,边写边给合作者发片段,而不是写完一整本再一次性发送。
这个算法已经被用到了实际训练中:有团队用它在三大洲五个国家的节点上,训练出了10亿参数的模型,通信开销只占总训练时间的7%。
去中心化训练听起来完美,但离真正走进普通家庭,还有几道绕不开的坎。
第一道是带宽限制。普通家庭的上传带宽通常只有几十Mbps,如果用传统方法训练千亿参数模型,光是同步数据就要花5000年。虽然DiLoCo算法把通信量降了500倍,但当节点数量超过8个,模型性能还是会明显下降。
第二道是设备稳定性。家庭电脑可能随时关机、断网,这对需要持续运行的AI训练来说是个大问题。目前的解决方案是让系统自动跳过故障节点,但这会增加额外的计算开销。
第三道是激励机制。为什么要把自己的电脑贡献出来?目前的模式是像出租算力一样付费,但要让普通用户愿意参与,还需要降低门槛——比如补贴备用电池和冗余网络的成本。有团队计划在2027年前实现家庭节点的规模化接入,但要让数百万家庭参与,还有很长的路要走。
当我们为AI的算力焦虑时,往往会想“建更多数据中心”“买更多GPU”,但去中心化训练给了我们另一个答案:与其创造更多能源需求,不如利用已经存在的资源。它不仅是一种技术创新,更是对AI能源逻辑的重构——从“让能源迁就计算”,变成“让计算找到能源”。
未来的AI训练,可能不再是少数巨头的游戏。也许某一天,你家的电脑在深夜完成的训练任务,会让AI多学会一种语言,多识别一种疾病。算力的民主化,才是AI可持续发展的真正起点。