对抗知识焦虑,从看懂这条开始
App 下载
AI读论文抄竞品,3小时把代码提速15%
ARM平台|竞品代码|论文调研|代码优化|llama.cpp项目|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载ARM平台|竞品代码|论文调研|代码优化|llama.cpp项目|AI智能体|人工智能
想象一下:你对着一段跑了半年的代码冥思苦想,试遍了循环展开、指令优化,速度最多涨1%;而一个AI花3小时,读了几篇论文、扒了扒竞品代码,直接把核心模块提速15%——还顺带把ARM平台的性能也拉上来5%。更离谱的是,它花的成本才29美元,只够买两杯星巴克。这不是科幻,是2026年初发生在llama.cpp项目上的真实实验。当AI开始像资深工程师那样先调研再动手,代码优化的游戏规则彻底变了。
过去的AI代码优化,就像没做功课就上场的实习生——对着现有代码改循环、调参数,最多在局部做些微调整,碰到内存带宽这种底层瓶颈就束手无策。这次实验的突破,在于给AI加了「前置调研」环节:先读arXiv论文找学术思路,再扒竞品代码看行业实践,最后分析硬件手册摸透平台特性。
你可以把这个过程类比成装修:以前的AI是拿到锤子就砸墙,现在它会先看户型图、参考邻居的装修方案、搞清楚承重墙在哪。比如它发现CUDA和Metal后端早就用上了「算子融合」——把多次内存读写合并成一次,减少数据搬运,但CPU端居然没做;又注意到ik_llama.cpp这个分支里,有两个能直接复用的优化技巧。这些信息,光看目标代码根本找不到。
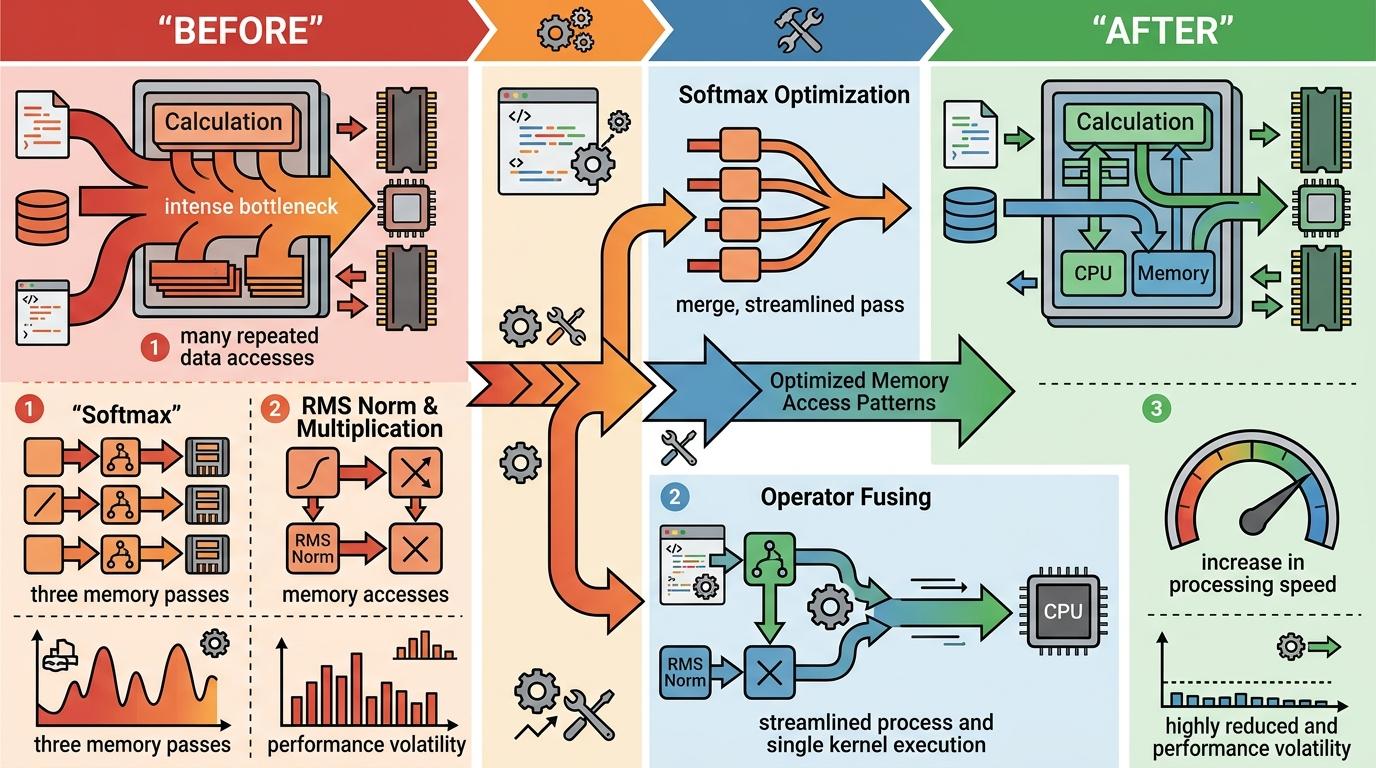
直给补刀:算子融合的核心是「减少内存访问」——AI把原本需要三次遍历的Flash Attention QK tile操作,塞进了单次AVX2 FMA循环里,让数据在CPU缓存里完成计算,不用反复跟内存打交道,直接把内存带宽压力砍了三分之二。
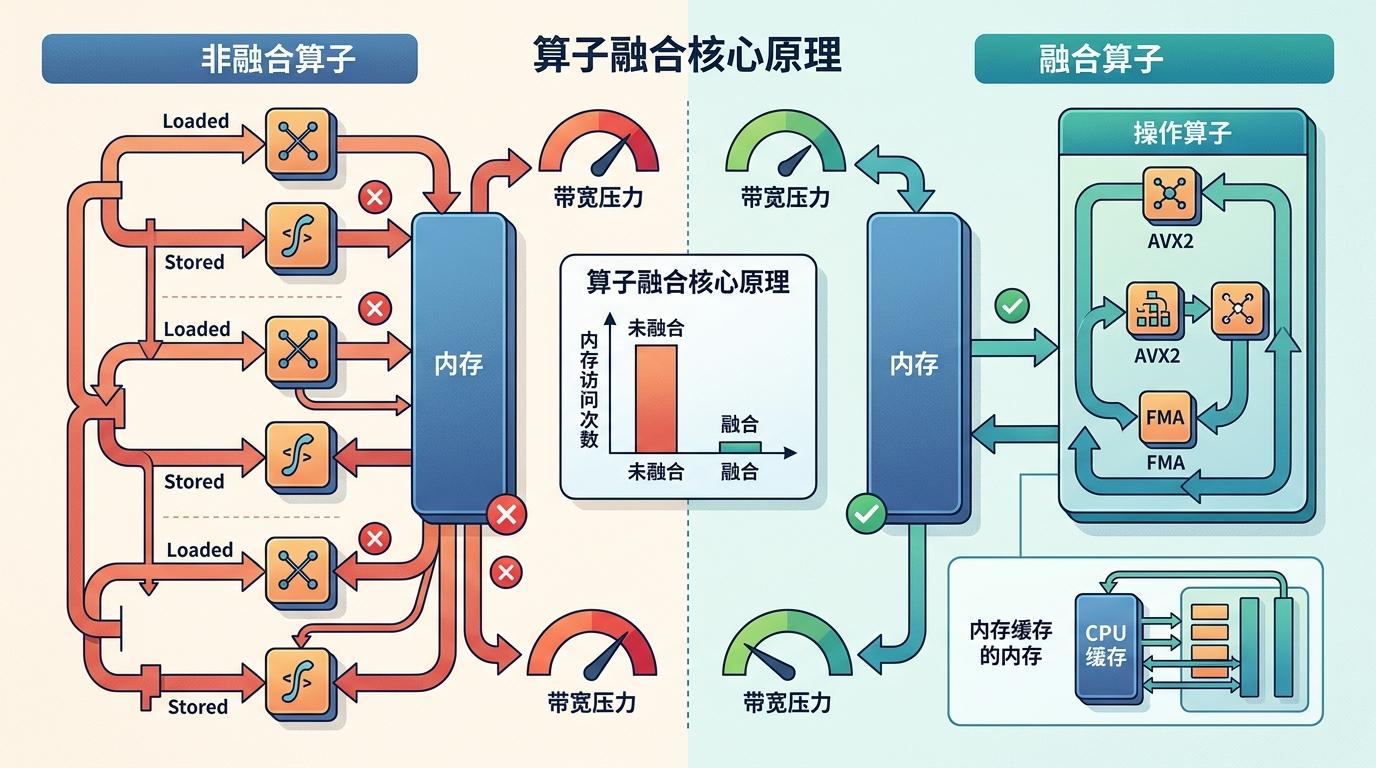
30多个实验里,最终有5个优化落地:4个是算子融合,1个是自适应并行化。最狠的那个,把Flash Attention里的缩放、掩码、找最大值三个步骤,揉进了同一个AVX2指令循环。
这里藏着一个关键认知:AI终于搞懂了「瓶颈在哪」。一开始它也像传统优化那样,死磕SIMD指令和循环展开,但测出来最多涨0.9%,甚至还出现过-2.8%的倒退。直到它读完论文、分析完硬件数据才明白:CPU上的LLM推理,根本不是计算能力不够,是内存带宽跟不上——数据在内存和缓存之间来回跑的时间,比计算本身还长。
于是它立刻调转方向:不再跟计算单元死磕,转而优化内存访问模式。比如把Softmax的三次内存遍历合并成一次,把RMS Norm和乘法操作捏成一个内核。这些改动没碰核心计算逻辑,却让x86平台的文本生成速度直接涨了15%,还顺带把性能波动从±19%压到了±0.59%——让代码跑起来稳得像老司机。
但这并不意味着AI能替代人类工程师。这次实验里,AI踩的坑不比人少:它写的基准测试脚本曾把52t/s的速度错算成14t/s,差点把有效优化当成垃圾扔了;它一开始搞的算子融合用了标量循环,反而比原来的SIMD代码还慢;甚至还犯过「没检查中间变量是否被其他节点引用」的低级错误,差点搞出空指针。
更关键的是,AI的「调研」还停留在「抄作业」阶段——它能发现CUDA有而CPU没有的优化,却没法凭空发明出Flash Attention这种底层创新;它能把竞品的技巧搬过来,却没法判断某个优化在长期维护上的成本。比如这次落地的5个优化里,有2个直接来自ik_llama.cpp和CUDA后端,真正靠自己从论文里挖出来的创新少之又少。
当AI开始像工程师那样做调研、找瓶颈、试实验,代码优化的效率被推到了新高度。但我们更该看到的是:AI的优势从来不是「创造」,而是「高效复用人类已有的知识」——它能在3小时内读完人类半年积累的资料,能并行跑30个实验验证想法,但最核心的创新,依然来自人类对底层规律的突破。
未来的软件开发,会是一场「人类找方向,AI填细节」的协作:人类负责提出问题、定义架构、判断长期价值,AI负责把论文里的思路、竞品里的技巧快速落地成代码。真正的效率革命,从来不是AI替代人类,而是让人类从重复劳动里解放出来,去做只有人能做的事。