对抗知识焦虑,从看懂这条开始
App 下载
终端里的隐形基建:让海量文本不再失控
运维工程师|Go语言|视口组件|Kubernetes日志|终端文本导航|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载运维工程师|Go语言|视口组件|Kubernetes日志|终端文本导航|软件工程|前沿科技
凌晨三点,运维工程师盯着终端里滚动的上万行Kubernetes日志,指尖在键盘上翻飞——不是在敲命令,而是靠几个快捷键精准定位到了藏在INFO堆里的ERROR。你可能没注意过,当你用git diff查看代码差异,或是用man翻阅手册时,那些能让你在海量文本里自由穿梭的能力,背后是一套被忽略的「终端文本导航基建」。开发者Robinovitch61用Go语言写了个可复用的视口组件,把这套基建拆解得明明白白,而它解决的,正是每个和终端打交道的人都遇到过的痛点:如何在字符网格里,把失控的文本重新变得可控。
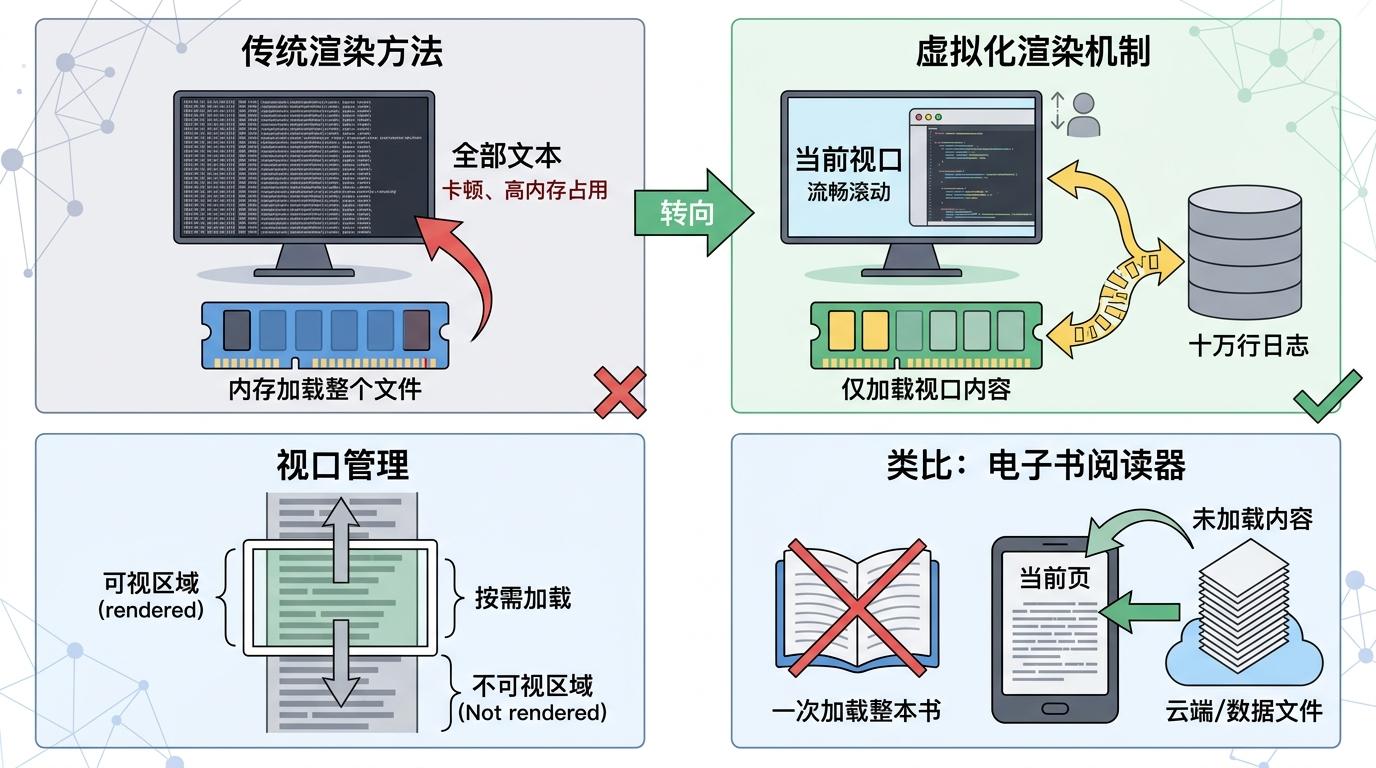
你可以把终端想象成一个固定尺寸的方格本——每个字符占一个格子,超出的部分要么被截断,要么得靠工具帮你翻页。最早的more分页器只能往下翻,后来的less解决了上下滚动的问题,但面对带颜色的日志、宽字符的中文或是格式化的JSON,这些传统工具还是会乱了阵脚。
视口(Viewport)组件就是为解决这些新问题而生的。它本质是一个可滚动、可调整大小的「文本窗口」,但比传统分页器多了几层关键设计:首先是把每一段文本封装成「Item」,提前计算好每个Unicode字符在终端里占的格子数——比如中文占2格,emoji占2格,连零宽的组合符号也能精准处理;其次是支持ANSI转义码,让彩色日志、语法高亮能正确显示;最后是内置了搜索、过滤和选中功能,不用再依赖终端模拟器的自带工具。
这套设计的核心是「虚拟化渲染」——它不会一次性把所有文本都塞进终端,只渲染当前窗口能看到的部分,就算是十万行的日志,也能保持流畅滚动。就像你看电子书时,阅读器只会加载当前页的内容,而不是把整本书都存在内存里。
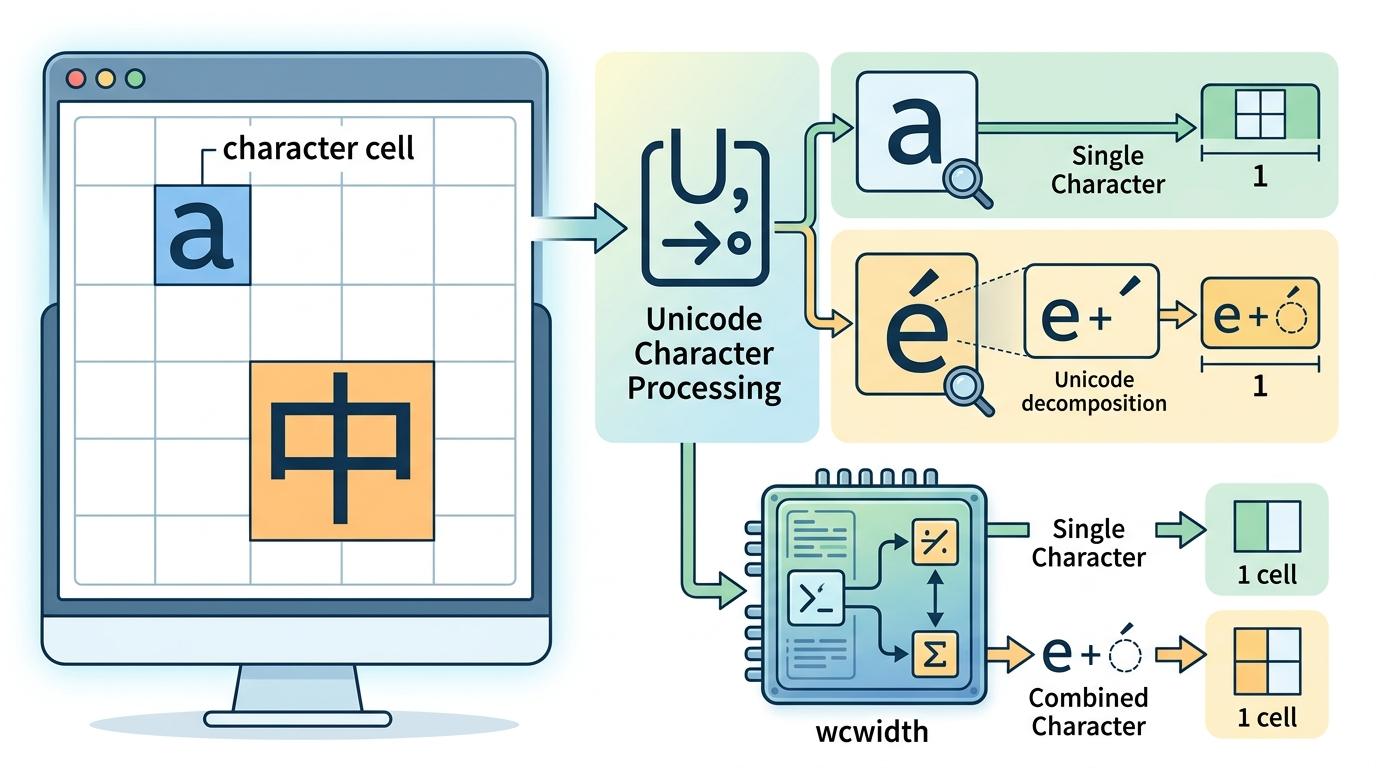
视口组件最不起眼也最关键的技术,是Unicode字符宽度的处理。在终端里,「a」和「中」看起来宽度不同,但程序怎么知道一个字符该占1格还是2格?开发者用了wcwidth库来精确计算每个字符的终端宽度,甚至能处理像「é」这样由两个码点组成的组合字符——它看起来是一个字符,但在Unicode里是「e」加一个重音符号,视口组件会把它当成一个整体来计算宽度,避免出现文字错位。
另一个攻坚点是搜索和交互。传统分页器的搜索只能定位到行,但视口组件能支持正则搜索、大小写忽略,还能在搜索结果里快速跳转——按n跳到下一个匹配,按x只显示包含匹配的行,甚至能保留匹配项的上下文。为了让这些操作流畅,开发者把搜索逻辑拆成了独立的filterableviewport模块,和视口本身解耦,既保证了性能,又方便其他应用复用。
还有一个容易被忽略的细节是快捷键的兼容性。不同终端模拟器的快捷键可能不一样,视口组件基于Bubble Tea框架,把键盘事件统一处理成标准的消息,不管你用的是iTerm2还是Windows Terminal,都能用上同样的快捷键——比如用/启动搜索,用方向键滚动,用回车选中内容。
这个视口组件不是孤立的工具,它已经被用到了多个终端应用里:比如Kubernetes日志查看器kl,用两个视口分别显示集群资源树和日志内容,选中一个容器就能实时查看它的日志;还有Nomad集群管理工具wander,用视口展示作业列表和任务日志,支持实时跟踪和命令执行;甚至还有一个替代less的分页器lore,完全基于这个视口组件打造。
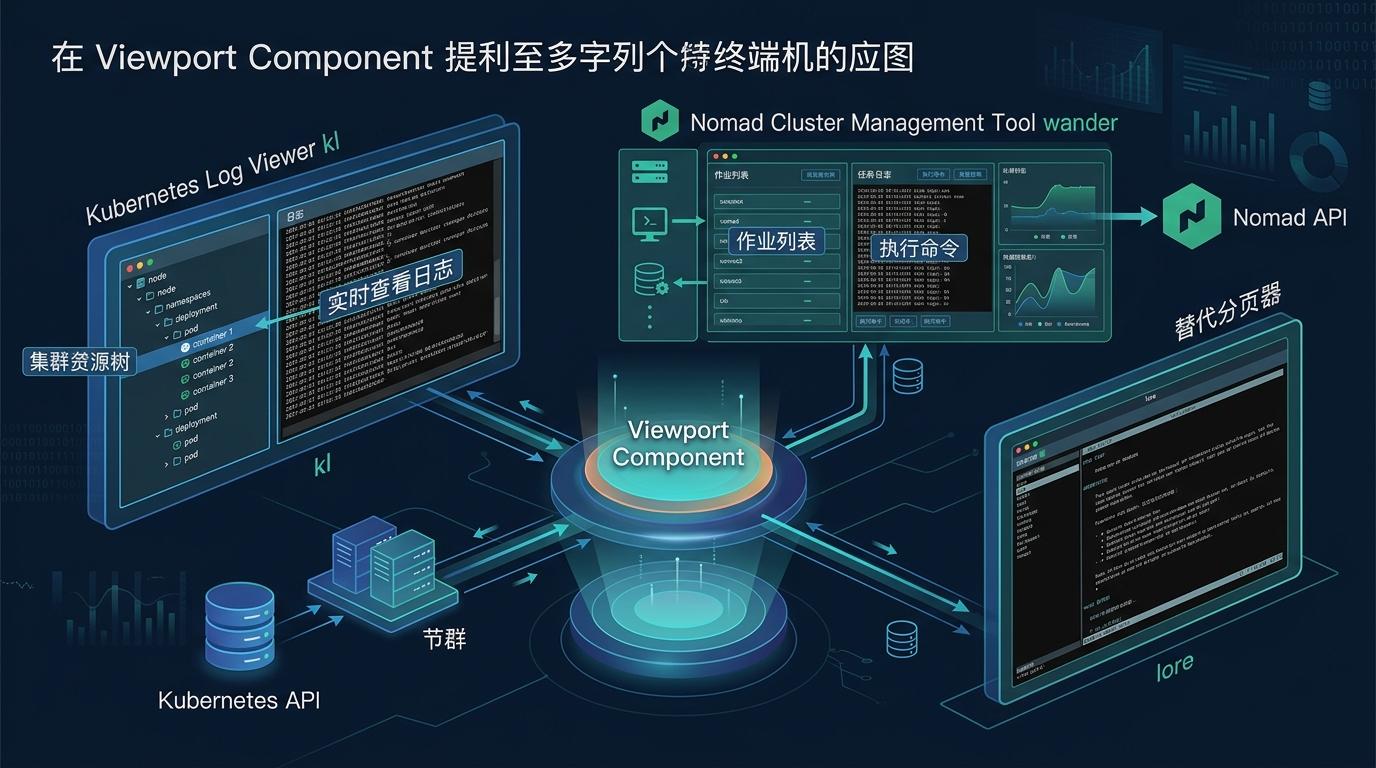
这些应用的成功,证明了视口组件的通用性——它就像终端UI的「乐高积木」,开发者可以用它快速搭建出复杂的交互界面,不用再从零开始处理文本渲染、滚动和搜索。而Bubble Tea框架的生态也在不断壮大,目前已有超过18000个基于它的终端应用,微软、NVIDIA等大厂也在用来开发终端工具。
不过这套组件也有局限:它主要针对的是只读的文本浏览,还不支持多光标编辑、富文本处理等更复杂的功能;而且它基于Go语言,虽然能跨平台,但对于用Python或JavaScript的开发者来说,复用成本还是有点高。
当我们谈论终端时,往往只关注命令行的输入输出,却忽略了那些让文本变得「好用」的底层逻辑。这个视口组件的价值,不在于它做了什么惊天动地的创新,而在于它把终端文本导航的底层逻辑梳理清楚,做成了一套可复用的基建——就像水电管线一样,平时看不见,但缺了它,整个系统就会瘫痪。
在信息爆炸的时代,我们每天要处理的文本越来越多,从日志到代码,从配置文件到数据报表,如何在这些文本里高效找到有用的信息,已经成了一种基础能力。而终端文本导航组件,就是帮我们把这种能力落地的工具。
文本的价值,在于能被高效找到。 这句话放在终端里成立,放在整个数字世界里,同样成立。