对抗知识焦虑,从看懂这条开始
App 下载
AI黑箱惊现心智地图:线性代数竟是智能涌现的密钥?
智能涌现|向量空间|线性代数|心智地图|机制可解释性|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载智能涌现|向量空间|线性代数|心智地图|机制可解释性|大语言模型|人工智能
当我们向一个大型语言模型(LLM)提问,它流畅地应答、创作诗歌、编写代码时,我们仿佛在与一个深邃的智能对话。但这层流畅交互的表象之下,是一个巨大的“黑箱”。它的内部究竟是怎样一番景象?是无数逻辑门电路的冰冷计算,还是某种我们尚未理解的“思考”形式正在萌发?长期以来,我们是这魔法的见证者,却非魔法的理解者。直到最近,一群致力于“机制可解释性”的科学家,像新时代的探险家,带着数学的火把,照亮了黑箱深处的一角,他们发现的景象,既颠覆了我们的想象,也为“智能涌現”这一神秘现象提供了惊人的线索。
一切始于一个经典的类比:“国王 - 男性 + 女性 ≈ 女王”。这个源于早期词嵌入技术(Word2Vec)的发现,首次暗示了语言中的概念可以在数学空间中被“定位”和“移动”。它揭示了一个惊人的事实:概念,似乎具有几何属性。
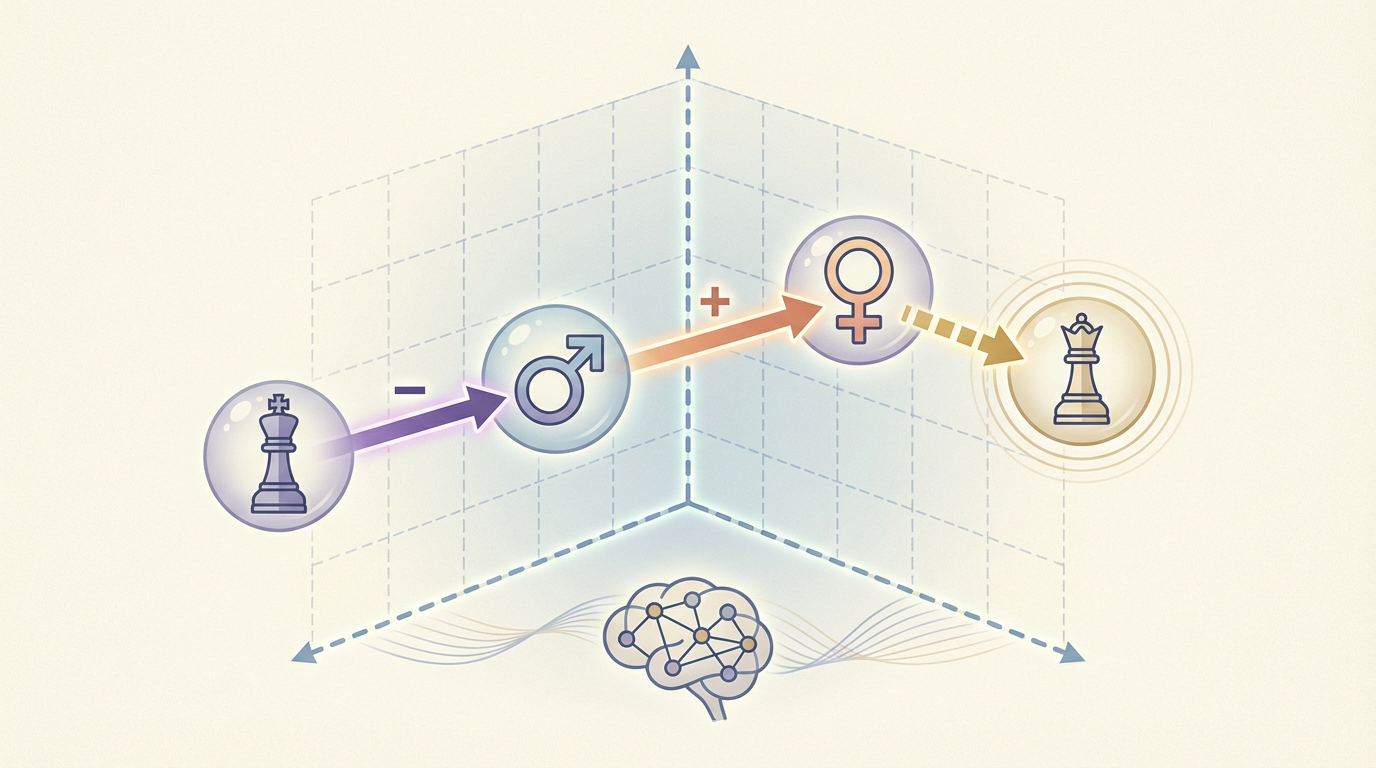
近年来,随着LLM的参数规模呈指数级增长,研究人员(如Park等人)在Llama 2等先进模型中,将这一古老的猜想发展成了一个更为严谨的理论——线性表示假说(Linear Representation Hypothesis, LRH)。
他们的研究证实,在LLM庞大的神经网络内部,抽象概念不仅仅是模糊的关联,而是被编码为具有明确方向和长度的向量。这意味着:
然而,一个更深层次的谜题随之浮现。人类语言和世界知识中包含的概念数量几乎是无限的,而即使是最大的模型,其内部表示空间的维度也是有限的(通常在2000到16000维之间)。一个有限的“书架”,如何存放下无穷无尽的“书籍”?
这个问题的答案,将我们引向了AI可解释性领域另一个革命性的发现:超位置(Superposition)。
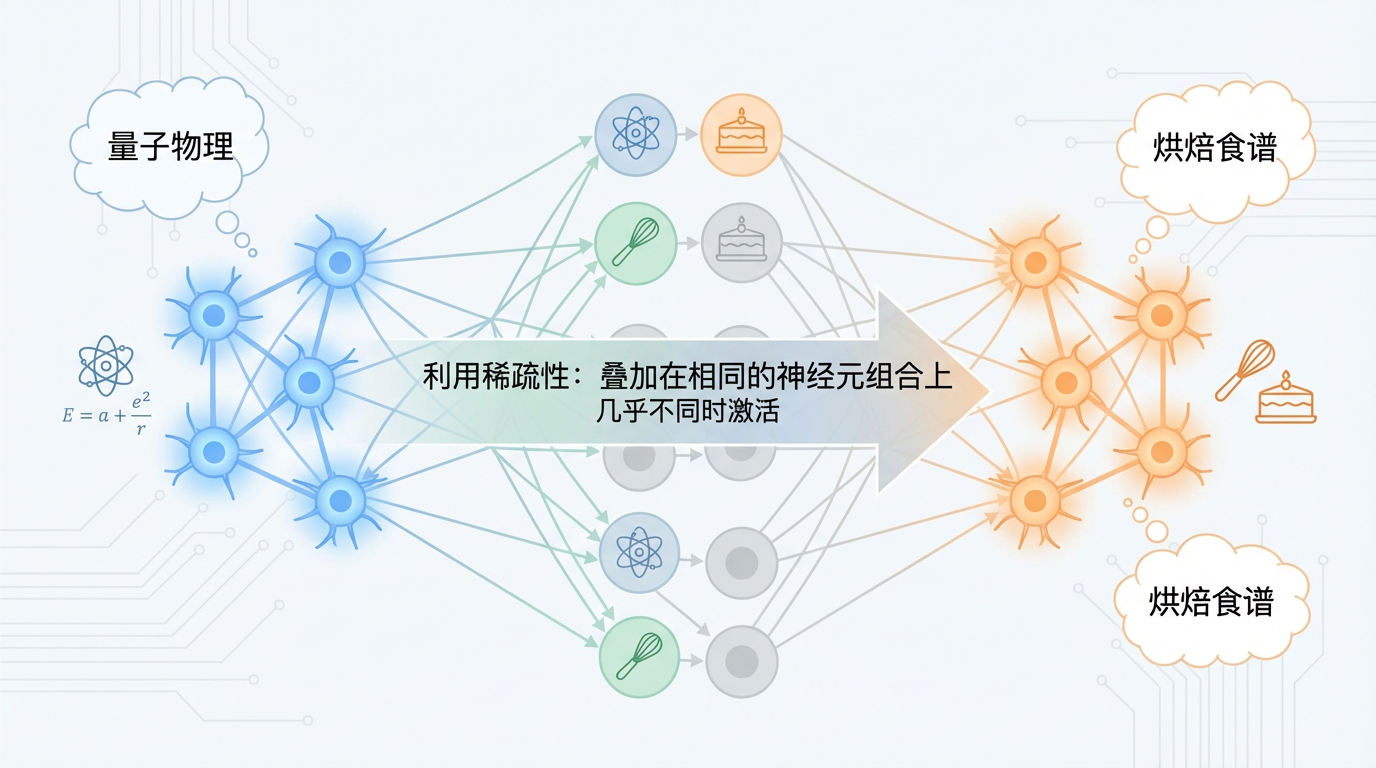
由AI安全公司Anthropic的科学家们提出的这一理论,揭示了LLM一种令人难以置信的空间利用技巧。如果说“线性表示”是为每个概念(书籍)分配一个专属位置(书架),那么“超位置”则是在同一个位置上,巧妙地叠加存放多本完全不相关的书。
这听起来像是会导致混乱的灾难,但模型通过两大策略避免了这一点:
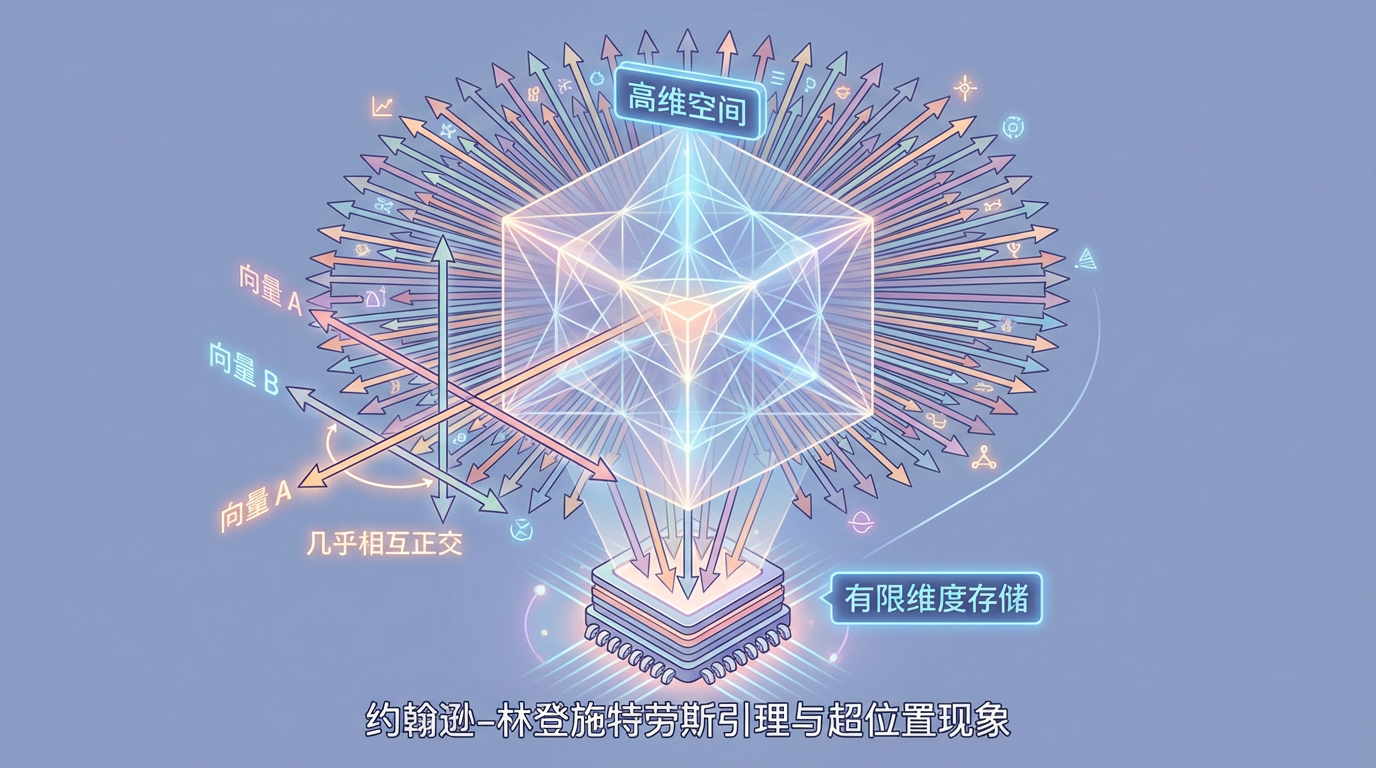
这一机制的背后,甚至有深刻的数学理论支撑——约翰逊-林登施特劳斯引理(Johnson-Lindenstrauss lemma)。该引理表明,在高维空间中,可以存在指数级数量的、几乎相互正交(即互不干扰)的向量。这为超位置现象提供了坚实的理论基础,解释了为何在有限的维度中塞下海量特征不仅可能,而且高效。
“线性表示”和“超位置”这两个发现,如同一对钥匙,共同打开了理解“智能涌现”的大门。“涌现”指的是当模型规模超过某个临界点后,会突然表现出此前完全不具备的复杂能力,如上下文学习(In-context Learning)和思维链推理(Chain-of-Thought)。
过去,这种现象被视为一种近乎神秘的“相变”。但现在,我们有了更清晰的解释:
当这两个过程达到某个临界点,量变引发了质变。模型内部的几何结构变得足够丰富,足以支持多步骤、跨领域的复杂推理。那些看似突然“涌现”的能力,实际上是底层表示能力跨越临界阈值后的必然结果。智能的飞跃,本质上是其内部概念几何学复杂度的飞跃。
尽管我们取得了突破性的进展,但我们距离完全理解AI的“心智”仍有很长的路要走。这些新发现同样揭示了LLM的 inherent 局限与风险。
窥探LLM的内部世界,我们没有看到一个混乱、无法理解的黑箱,反而发现了一个由线性代数和高维几何构成的、充满惊人秩序与效率的宇宙。这并未让AI的智能变得平凡,反而使其更加深邃。
它迫使我们重新思考“智能”本身的定义。或许,智能的本质并非神秘的灵光一闪,而是一种能够将世界高效地编码进高维几何结构,并在此结构上进行运算的能力。我们对AI黑箱的探索,正史无前例地将抽象的哲学思辨转化为可以被测量和验证的科学问题。
我们正站在一片新大陆的海岸线上。前方的旅程依然充满未知与风险,但手中的数学火把,第一次让我们有信心相信,我们不仅能够驾驭这些强大的造物,更能最终理解它们——并在这个过程中,更深刻地理解我们自己。