对抗知识焦虑,从看懂这条开始
App 下载
AI画的假截图,骗过了半个互联网
模型发布会|界面视觉特征|图像伪造技术|AI生成截图|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型发布会|界面视觉特征|图像伪造技术|AI生成截图|AIGC|人工智能
当你刷到一张Mac桌面的Chrome截图——标签页停在某AI工具官网,弹窗里正聊着当天发布的新模型,你大概率会划过去,以为只是条普通技术动态。没人会想到,这整张截图都是AI画的:从Mac菜单栏的磨砂质感,到Chrome标签的圆角,再到弹窗里的每一行文字,没有一个像素来自真实屏幕。
这是该团队最新图像模型的亮相方式:先让AI「伪造」自己的发布会现场。区别于以往直接生成图像,它学会了「先想再画」——接到生成指令后,会先拆解需求的逻辑链条,比如要做一张假截图,就得先调用互联网上Mac系统界面、Chrome浏览器的公开视觉特征,再把「新模型发布」这个信息嵌入到合理的界面位置,甚至会检查弹窗文字和「发布会」的时间线是否匹配。这种类似人类的规划能力,让它跳出了「像素拼接」的局限,开始生成符合现实逻辑的内容。
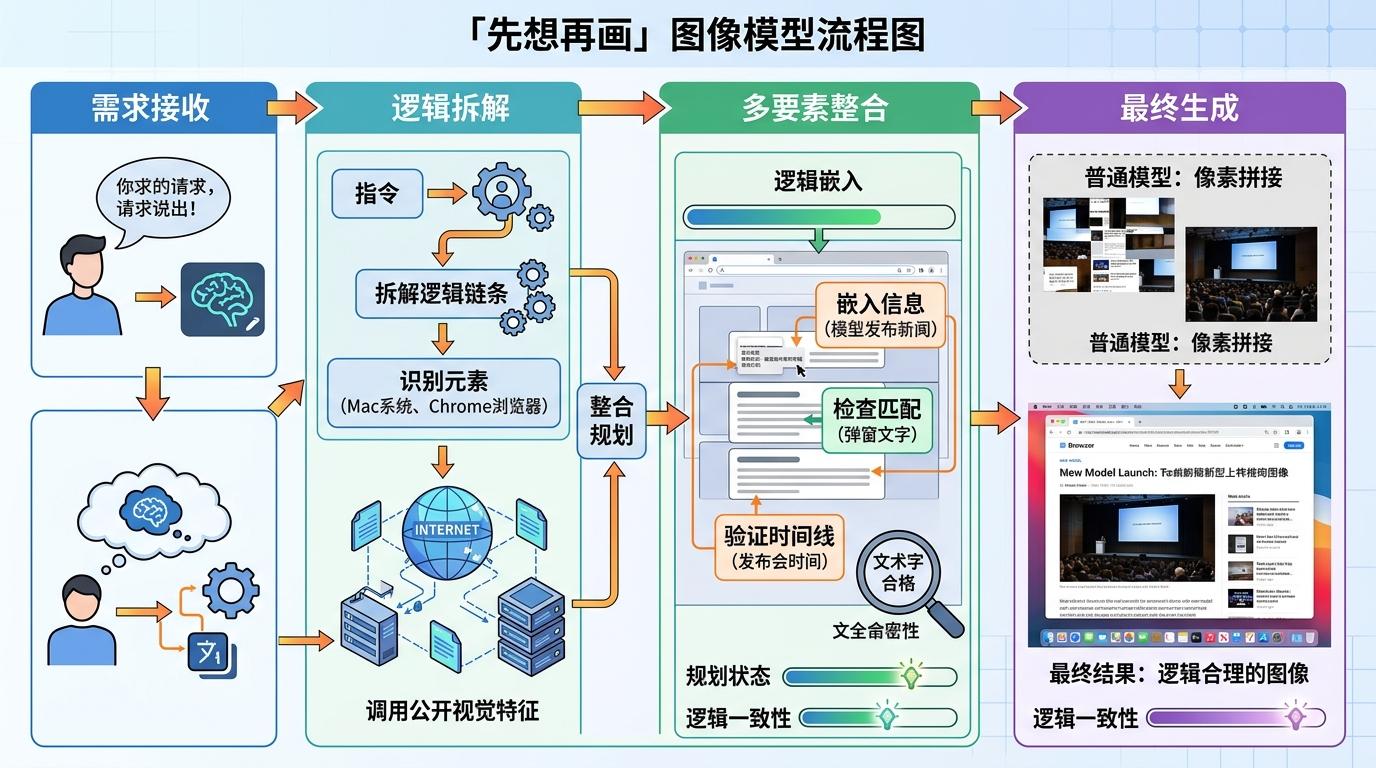
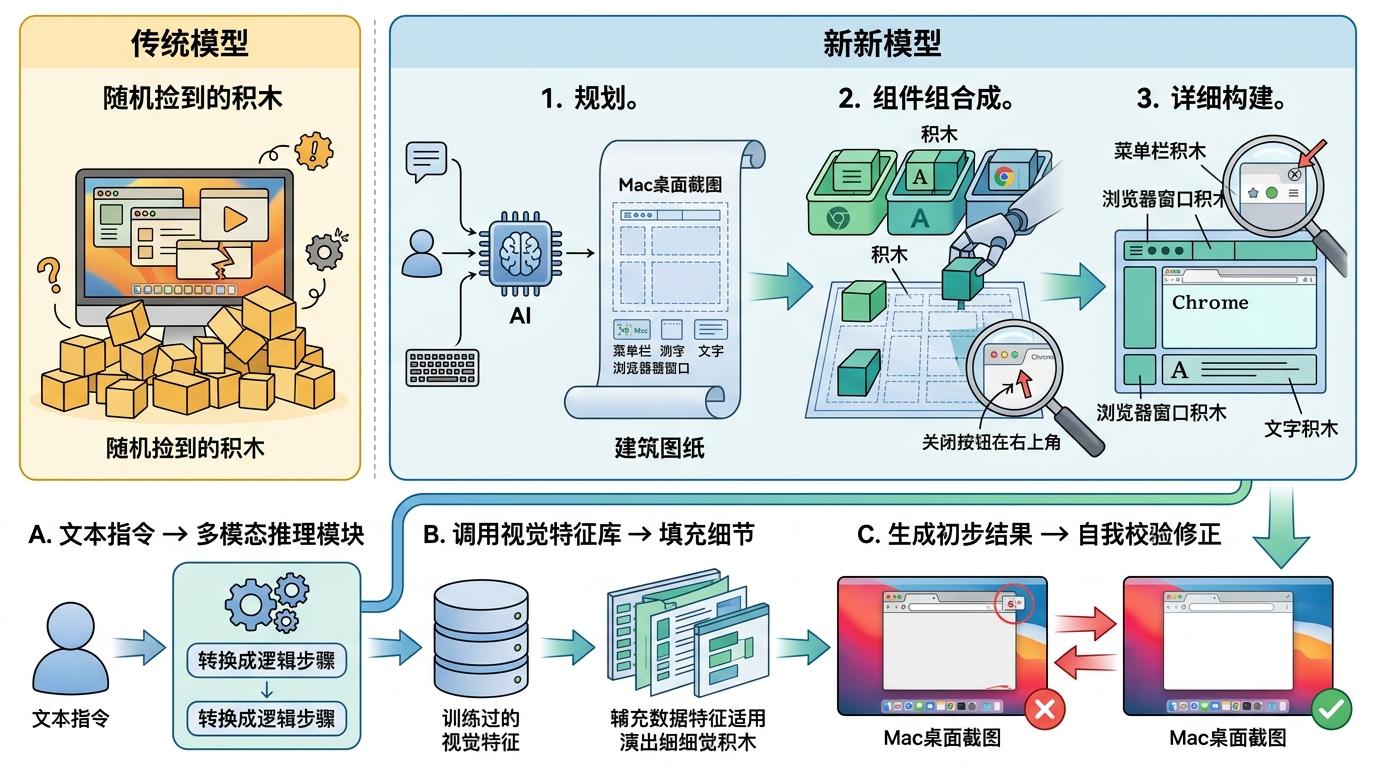
它的核心机制,可以类比成「用积木搭房子」:传统模型是把随机捡到的积木堆成大概的形状,而新模型会先画一张建筑图纸——先确定要搭的是「Mac桌面截图」,再找对应尺寸的「菜单栏积木」「浏览器窗口积木」「文字积木」,甚至会注意到「Chrome标签页的关闭按钮在右上角」这种细节规则。技术上,它是在扩散模型的基础上,加入了多模态推理模块:先把文本指令转换成可执行的逻辑步骤,再调用训练过的视觉特征库去填充每个步骤的细节,最后通过自我校验修正不符合逻辑的部分。
更值得关注的,是它在多语言文本生成上的突破。以往用非英语指令生成图像,经常出现文字扭曲、拼写错误,比如用中文指令生成「奶茶店海报」,海报上的店名可能变成乱码。而新模型能准确渲染中文、日文、印地语等多种语言的文字,甚至能模拟不同字体的风格——从杂志标题的粗体字到漫画里的手写气泡框,文字的位置、大小、字体都能和场景匹配。这背后是它在训练时加入了多语言图文对齐数据,让它能理解不同语言的文字含义和视觉呈现规则。

但光鲜的技术突破背后,仍有无法回避的隐忧。比如它能生成以假乱真的名人「复古写真」,也能复刻某类艺术风格的作品,虽然开发团队表示不会直接复制特定艺术家的风格,只学习通用的视觉模式,但版权边界依然模糊:当AI生成的作品和某艺术家的风格高度相似时,如何界定是「学习通用模式」还是「模仿个体风格」?目前的法律框架还没有明确答案。
更现实的挑战是内容真实性。当AI能生成逻辑自洽的假截图、假杂志、假新闻图,普通人仅凭视觉判断真假的难度会越来越大——你刷到的「某名人的复古照片」「某品牌的新品海报」,可能都是AI几秒钟生成的虚构内容。而现有的AI水印技术,还无法完全防止内容被篡改,一张带水印的AI图,经过简单的编辑就能去掉水印,变成「看起来真实」的内容。

未来的视觉世界里,AI不会是取代人类创作者的工具,更像是一个「超级美工」:它能快速把你的想法变成视觉内容,但判断内容的真实性、界定创作的版权边界、守住伦理的底线,最终还是要靠人类自己。毕竟,技术只负责生成像素,而真实感的边界,永远在人的心里。