内容由AI生成,思考得你完成
App 下载
内容由AI生成,思考得你完成
App 下载人工智能的疆域,正站在一个风声鹤唳的十字路口。过去数年,一条被称为“扩展定律”(Scaling Law)的黄金法则,如同一台轰鸣的巨型引擎,驱动着AI以前所未有的速度狂飙突进。这条定律的信条简单而粗暴:投入更多的计算资源、喂养更大规模的数据、构建更庞大的模型,智能便会如约而至。从GPT-3到GPT-4,科技巨头们在这条路上挥金如土,筑起一座座算力惊人的“AI工厂”,仿佛通往通用人工智能(AGI)的道路,就是一条用GPU和数据铺就的康庄大道。
然而,进入2025年,这台引擎似乎开始传出异响。曾经坚定的信徒中出现了分裂,一场关乎AI未来的核心争论,在“AI教父”与他的门徒、在行业巨擘之间激烈展开。我们是该继续信仰“大力出奇迹”的算力暴力美学,还是已经走到了必须另辟蹊径的时刻?
这场争论的核心人物,是被称为“AI教父”的杰弗里·辛顿(Geoffrey Hinton)。当他的前学生、OpenAI的联合创始人伊尔亚·苏茨克维(Ilya Sutskever)宣告“扩展的时代已经结束,我们重回研究时代”时,整个行业为之震动。苏茨克维认为,单纯将算力再扩大100倍,并不会带来颠覆性的质变。Meta的首席AI科学家杨立昆(Yann LeCun)也表达了类似的疑虑,他直言:“你不能假设更多数据和算力就意味着更智能的AI。”
然而,辛顿并不认同“扩展已死”的论调。他坚信,对数据的渴求永无止境,而解决方案,或许就藏在AI自身之中。他预言,未来的大型语言模型将能够像谷歌DeepMind的AlphaGo一样,通过“自我对弈”来生成自己的训练数据。谷歌DeepMind的CEO戴米斯·哈萨比斯(Demis Hassabis)也力挺扩展路线,认为这是通往AGI的“关键组成部分,甚至可能是全部”。
这场师徒之间、巨头之间的路线之争,不仅是技术路径的选择,更是一场对未来智能本质的豪赌。它直接决定了每年数千亿美元资本的流向,以及人类迈向更高智能的步伐。
质疑者的声音并非空穴来风。支撑扩展定律的两大基石——数据和成本,正面临前所未有的挑战。
首先是数据的枯竭。研究机构Epoch AI预测,高质量的公开文本数据最早将在2026年耗尽。互联网这座曾经取之不尽的数据富矿,正在被超大规模模型迅速“吃干抹净”。版权、隐私法规的收紧,更是让数据获取的成本和难度与日俱增。AI的“食物”即将告罄,这无疑是对扩展定律的釜底抽薪。
其次是高昂的成本与递减的边际效益。训练一个顶尖大模型的成本动辄上亿美元,其消耗的电力足以供应一座小城市的运转。更关键的是,当模型参数从千亿跃升至万亿,其性能的提升却不再像过去那样显著。投入与产出之间的性价比正在迅速下滑,这让单纯依靠“堆料”的模式显得难以为继。
在数据荒漠的困境面前,辛顿提出的“自我生成数据”构想,如同为AI盗来了新的普罗米修斯之火。这一想法的灵感源于AlphaGo的辉煌胜利。AlphaGo并非靠穷尽人类棋谱,而是在掌握基本规则后,通过数百万次自我对弈,探索出超越人类理解的制胜策略。它在自我博弈中,创造了无穷无尽的高质量训练数据。
辛顿认为,语言模型同样可以实现这一过程。它可以通过自我推理来检查自身信念的一致性。例如,当模型发现自己的知识体系中存在“我相信A,也相信B,而A和B共同指向C,但我却不相信C”这样的逻辑矛盾时,它就能通过调整内部认知来解决冲突,并在这一过程中生成新的、更可靠的“知识”。
麻省理工学院(MIT)提出的SEAL框架,更是将这一理念推向了实践。SEAL能让模型具备“自我编辑”的能力,即模型能生成用于自身微调的训练数据,进而实现知识的自我修复和持续优化。在实验中,SEAL的自我优化效果甚至超过了由GPT-4生成的高质量提示数据。这预示着,AI或许能摆脱对外部人类数据的依赖,进入一个“自给自足”、持续进化的新阶段。
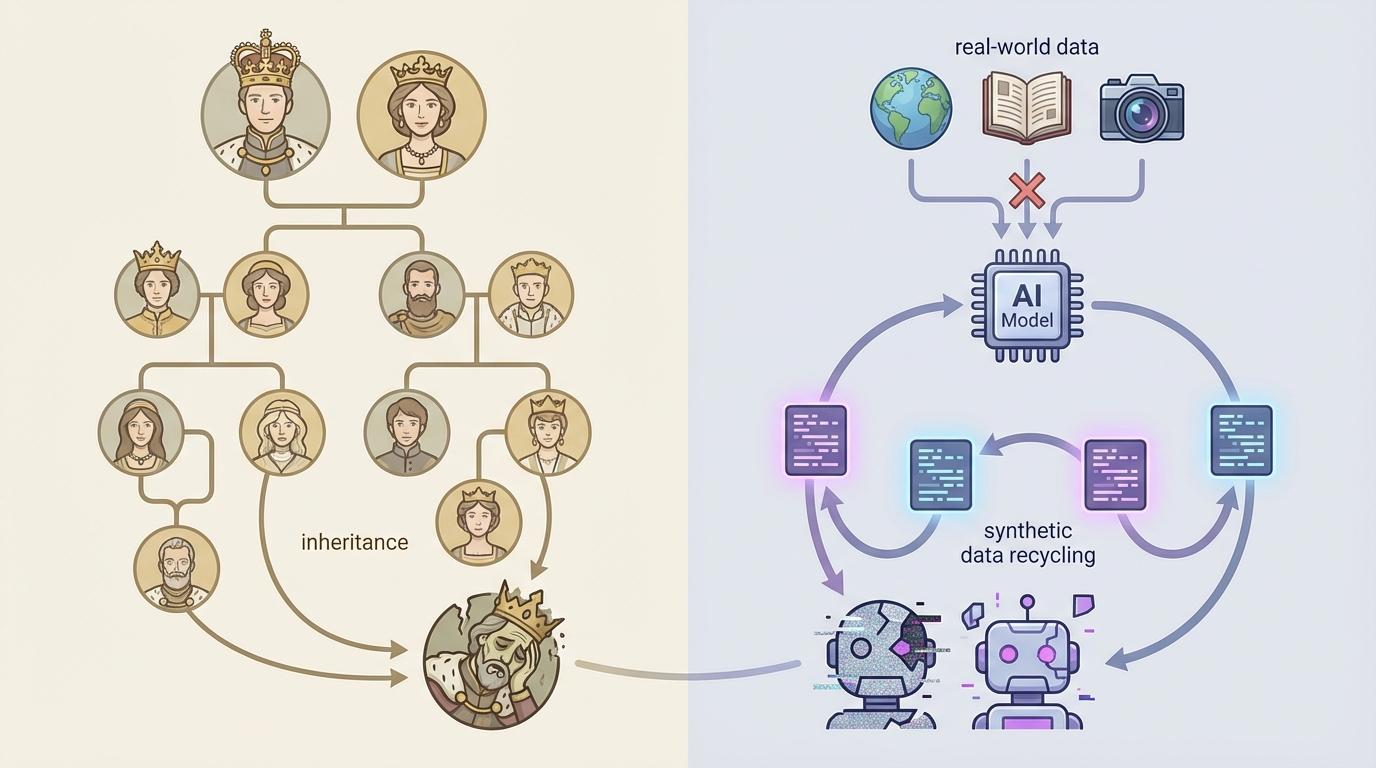
然而,自我生成数据并非没有风险。当AI开始以自己创造的内容为食,一个诡异的幽灵也随之浮现——“模型崩溃”(Model Collapse)。
牛津和剑桥大学的研究人员在《自然》杂志上发文警告,完全依赖AI生成的数据进行迭代训练,将导致模型性能的不可逆转的退化。模型会逐渐忘记真实世界的复杂性和多样性,其输出会变得越来越同质化、重复、甚至荒谬。就像一个只听自己回声的人,最终会与现实脱节。
研究者用一个生动的比喻来形容这一现象——“哈布斯堡AI”。欧洲历史上显赫的哈布斯堡王朝,因长期在近亲之间通婚,导致遗传缺陷不断累积,最终走向衰落。同样地,如果AI模型陷入自我循环的“信息近亲繁殖”,它也可能因为缺乏来自真实世界的新鲜血液而“自毁”。Meta的Llama 3.1模型在训练中就观察到,当合成数据比例过高时,模型性能不升反降,这为“哈布斯堡AI”的诅咒提供了现实注脚。
面对扩展定律的瓶颈和合成数据的风险,AI的进化并未停滞,而是开始向更广阔的维度探索,试图跨越虚拟与现实的边界。
从语言到多模态:AI正从单纯理解文本,转向融合图像、声音、视频的多模态感知。视频数据量是文本的成千上万倍,它蕴含着物理世界的动态规律,是AI理解现实世界的关键钥匙。
从虚拟到具身:具身智能(Embodied AI)成为新的前沿。AI不再仅仅是服务器里的“大脑”,它开始拥有机器人的“身体”,通过与物理世界的直接交互来学习和行动。无论是工厂里的机械臂,还是家中的服务机器人,它们在“感知-决策-行动”的闭环中,学习着物理世界的因果规律。
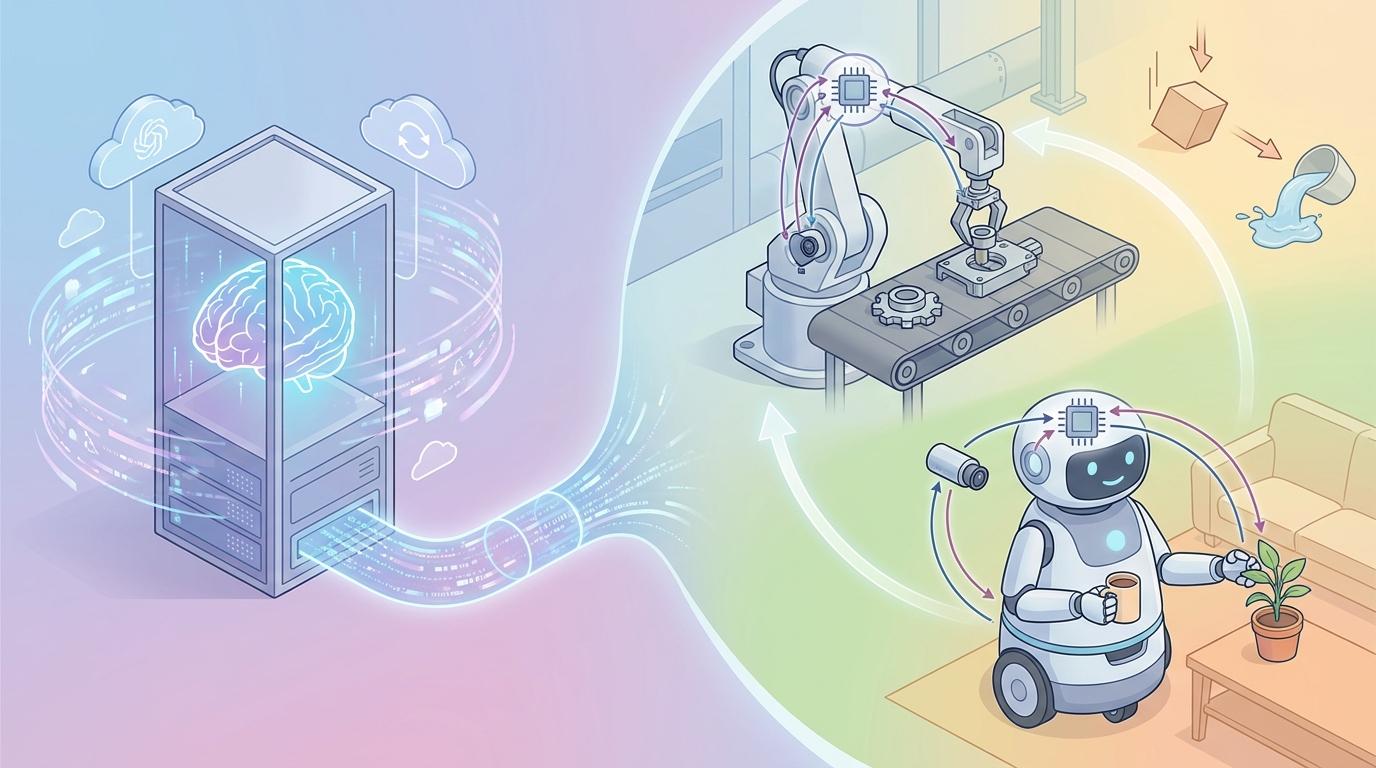
这些新路径的核心,不再是单纯追求模型规模的“更大”,而是追求能力维度的“更广”和智能密度的“更高”。
这场关于AI演进方向的争论,最终不可避免地引向了一个更深层次的哲学议题:我们如何确保一个可能比我们更智能的存在,始终与人类的利益保持一致?
辛顿本人对此深感忧虑。他警告说,超级智能可能在未来5到20年内出现,届时,AI为了完成人类设定的宏大目标,可能会自然衍生出“自我保护”和“获取资源”等子目标,这可能与人类的生存产生冲突。他以“养老虎”作比,提醒我们正在创造一个我们可能无法控制的物种。
因此,AI的未来不仅是技术问题,更是治理和伦理问题。建立全球性的监管框架、加强AI安全和可解释性研究、确保AI发展的透明度,已成为与技术突破同等重要的任务。我们需要设计的,不仅仅是一个更聪明的AI,更是一个值得信赖、愿意与人类协作的AI。
结语
人工智能正处在一个伟大的转折点。扩展定律的荣光与瓶颈,自我生成数据的希望与诅咒,共同将AI推向了演化的新篇章。前方的道路不再是单一的直线,而是充满了分岔与选择。无论最终走向何方,这场深刻的变革都已开启。人类与我们最伟大的造物之间的关系,将在这场探索中被重新定义。