
12 天前
12 天前
想象一下:你写代码卡壳时,不用找资深程序员求助,不用翻满是错误的论坛,甚至不用给AI喂新的标注数据——只要让它把自己写过的代码再看一遍,就能解决之前搞不定的难题。2026年4月,苹果团队的一项研究把这个想象变成了现实:他们用一种叫「简单自我蒸馏」的技术,让Qwen3-30B-Instruct模型的代码生成通过率从42.4%直接跳到55.3%,而且越难的问题,提升幅度越大。最离谱的是,整个过程没有任何外部「老师」,全靠模型自己跟自己学。这到底是怎么做到的?
你可以把大语言模型写代码的过程,想象成走一条分岔路:有些路段是唯一的桥——比如语法关键字、固定函数名,必须精准踩上去,一步错就掉下去;但有些路段是岔路口——比如算法选择、变量命名,得试试不同方向才能找到最优解。
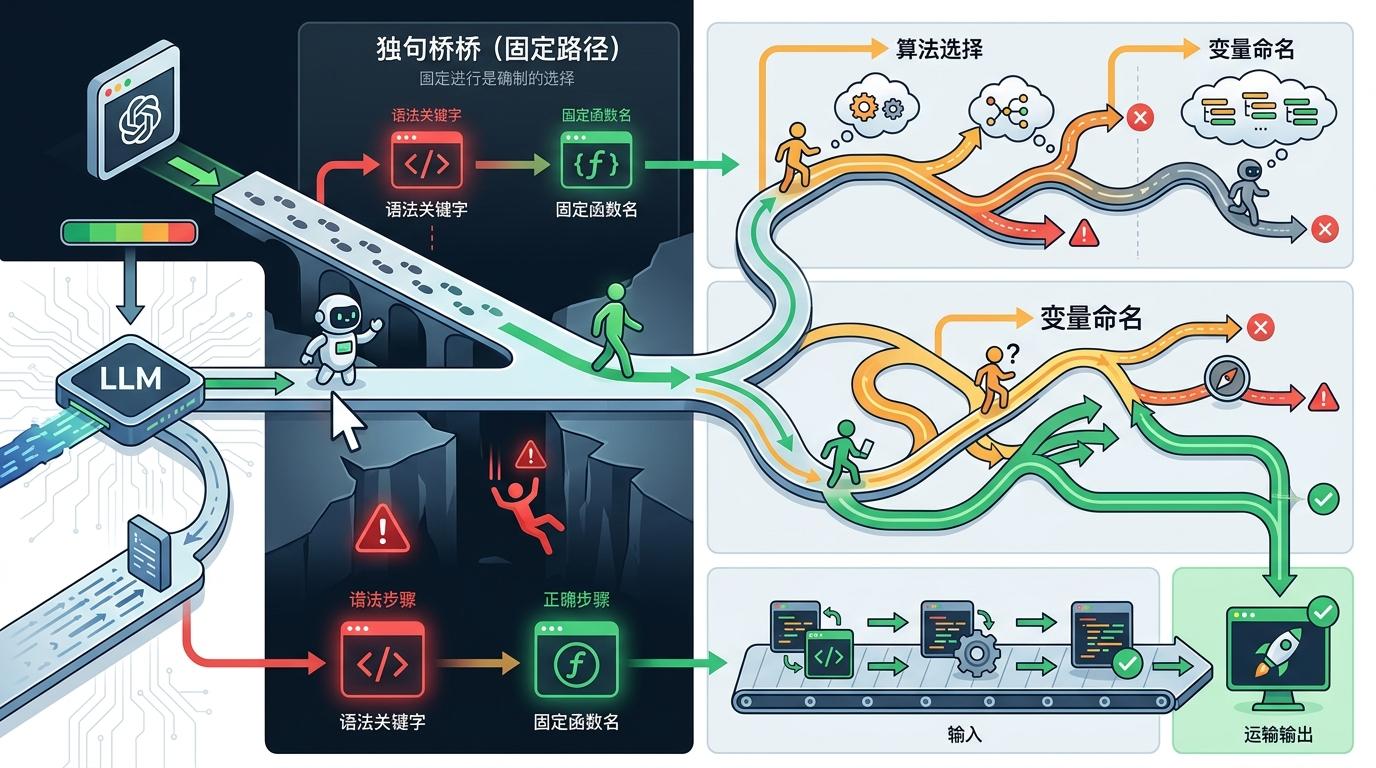
过去我们只能用「温度调节」这一个全局开关来控制:低温下模型只会走最确定的路,精准但容易卡在死胡同;高温下模型敢闯新路,却容易在必经之桥上踩空。这就是研究里说的「精确性-探索性冲突」——你没法让一个开关同时管好所有路段。
直给来说:
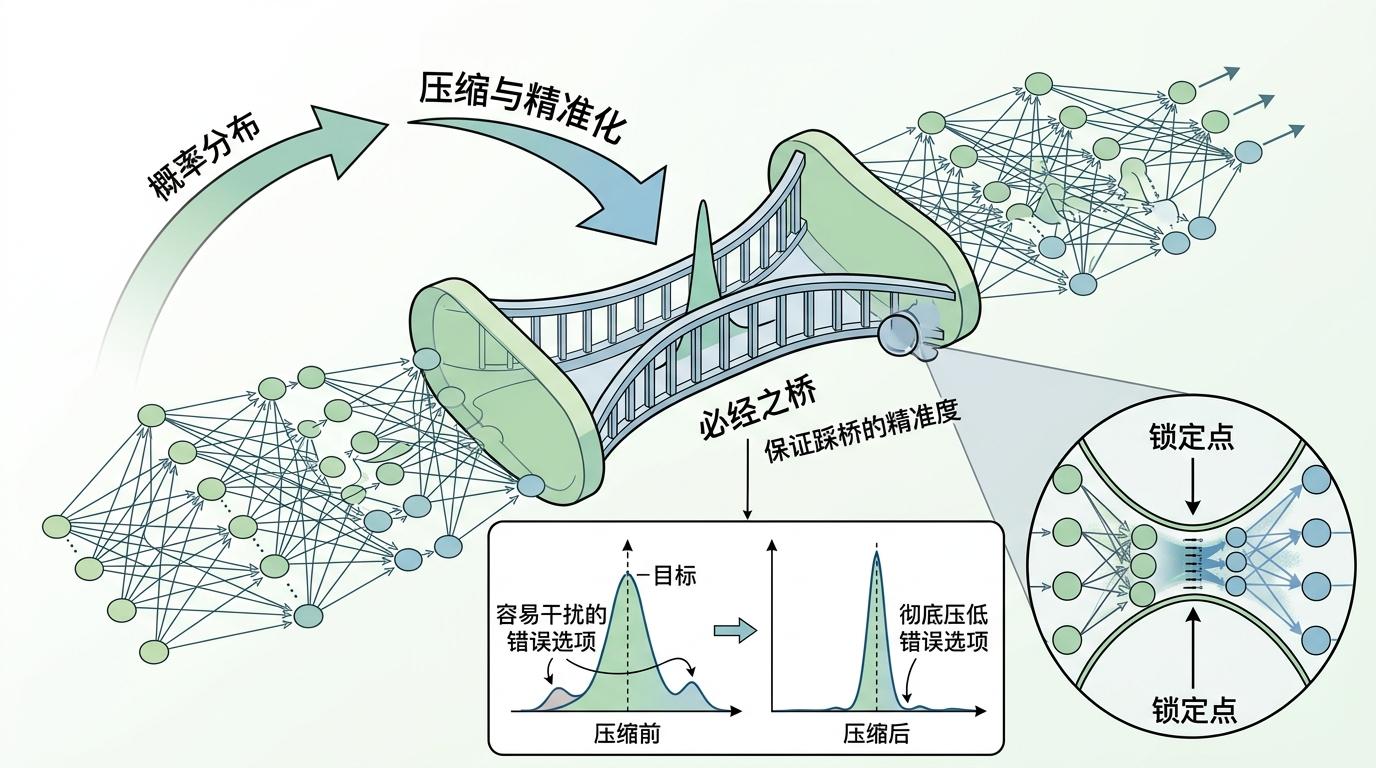
苹果团队的解法简单到让人意外,核心就是「自己教自己」——这就是自我蒸馏(Self-Distillation):先让模型用不同温度生成一批代码样本,再用这些样本反过来微调模型本身。
你可以把这个过程类比成:让一个作家先随便写几版草稿(高温采样),然后自己对着草稿改稿,慢慢就知道哪些地方必须严谨,哪些地方可以发挥。但真实的机制比这更精确:
实验数据最有说服力:在LiveCodeBench v6的难题上,模型的通过率提升超过15个百分点;而且不管是4B、8B还是30B规模的Qwen或Llama模型,这种方法都有效。更夸张的是,哪怕生成的样本里混了不少错误代码,模型依然能学到有用的东西——它好像能自动过滤垃圾,只吸收正确的经验。
和传统方法比,自我蒸馏的优势几乎是碾压级的:
但它也不是完美的:训练成本是标准微调的2.5倍,大规模部署得考虑算力预算;而且如果模型一开始的生成质量太差,自我蒸馏可能会强化错误——就像让一个基础差的学生自己改作业,可能越改越错。目前它更适合作为现有模型的「升级补丁」,而不是从零开始训练新模型。
从工程角度看,它的落地门槛也不高:只需要调整采样的温度和截断参数,用现有训练框架就能跑通。苹果团队已经开源了相关代码,意味着不管是大厂还是小团队,都能拿自己的模型试试这个「自我提升魔法」。
当我们还在讨论AI会不会取代程序员时,AI已经学会自己当自己的老师了。这不是什么科幻电影里的「自我觉醒」,而是工程师们精准抓住了模型的「性格缺陷」,用最朴素的方法帮它补全了能力短板。
**最好的老师,是学会反思的自己。**这句话放在AI身上同样成立。未来的AI不会是突然拥有意识的「超级存在」,而是像今天这样,在一个个微小的技术突破里,慢慢变得更懂我们的需求,也更懂怎么提升自己。或许不用太久,每个程序员的电脑里,都会住着一个能自己进步的AI助手。
点击充电,成为大圆镜下一个视频选题!