对抗知识焦虑,从看懂这条开始
App 下载
谷歌把时间拆成补丁,预测准确率提30%
极端场景数据|补丁机制|时间序列预测|谷歌TimesFM模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载极端场景数据|补丁机制|时间序列预测|谷歌TimesFM模型|大语言模型|人工智能
当电商新品只有3个月销售数据,当供应链突然遭遇疫情冲击,当电网要预判极端天气下的负荷波动——传统预测模型往往束手无策,要么缺数据,要么跟不上突变。谷歌团队的TimesFM模型,却能在没见过这类数据的情况下,给出比传统方法准30%的预测结果。它不用针对每个场景重新训练,甚至能一次性预判未来1000个时间点的波动区间。这背后,是一种把时间序列「拆成补丁」的全新思路。
你可以把时间序列想象成一篇没有标点的长文,传统模型是逐字逐句读,遇到长句子就容易忘前面的内容。而TimesFM做了一件关键的事:把连续的时间点切成固定长度的「补丁」——就像把长文分成段落,每个补丁包含32个时间点的信息。
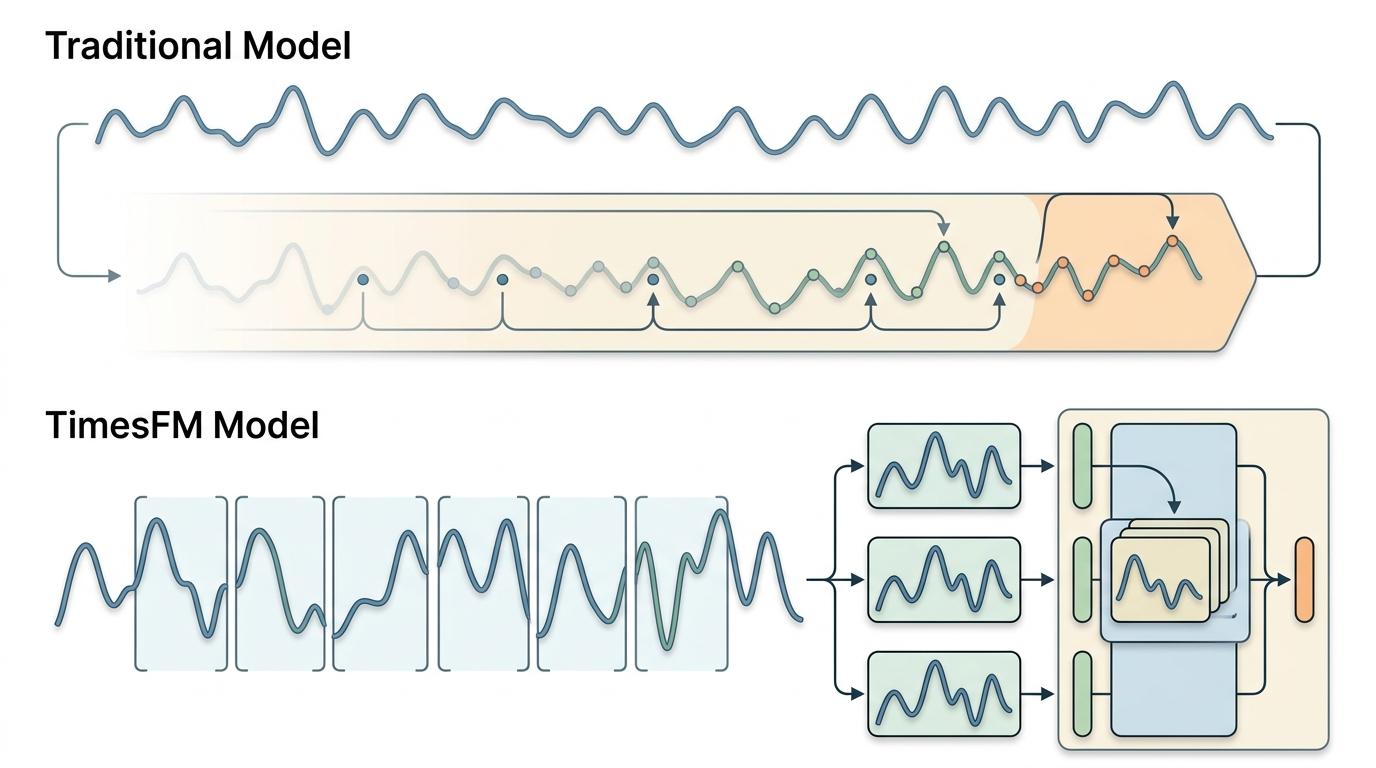
这些补丁会被编码成向量,再送入类似GPT的解码器架构。和语言模型学习词语间的关联一样,它在1000亿个真实时间点的预训练数据里,学习不同补丁之间的时序规律:比如销售数据里「618大促」补丁后通常跟着「订单暴涨」补丁,电网数据里「高温预警」补丁后是「负荷峰值」补丁。
但真实的机制比这更精确:它采用因果自注意力机制,确保预测时只看「过去的补丁」,不会提前泄露未来信息;还能让输出补丁的长度远大于输入补丁,比如用32个时间点的历史,一次性预测128个时间点的未来,直接解决了传统逐步预测的误差累积问题。
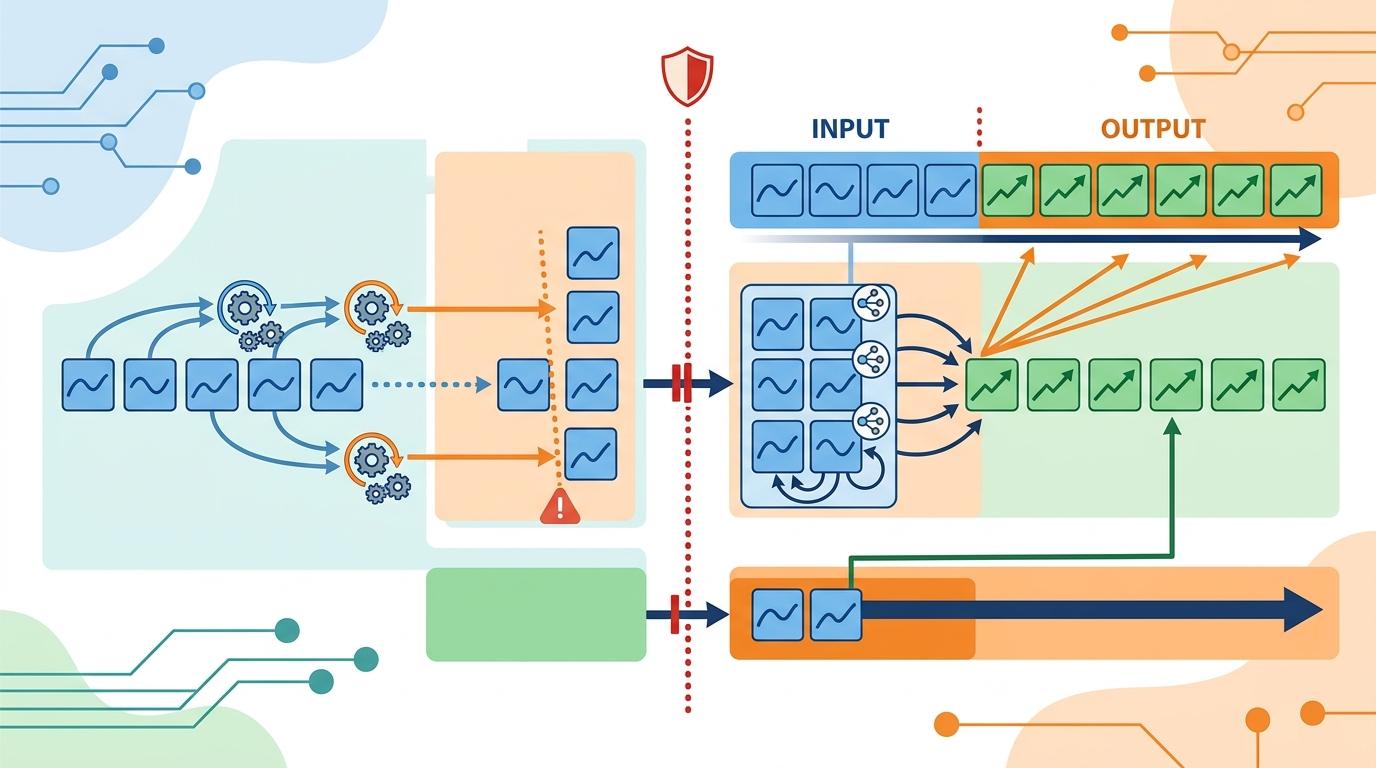
传统时间序列模型的死穴是「冷启动」:新产品、新业务没有足够历史数据,模型根本无法训练。TimesFM的核心突破,就是靠大规模预训练获得了「零样本预测」能力——不用针对新场景微调,直接就能给出靠谱结果。
它的预训练数据覆盖了搜索趋势、零售销售、交通流量、电力负荷等10多个领域,从分钟级到年级的时间频率都有,甚至还加入了合成数据模拟极端场景。这让它学会了通用的时序「语法」:不管是销售数据的季节性,还是电网数据的周期性,它都能快速识别。
2025年谷歌又推出了「上下文微调」技术:推理时输入几个类似的时间序列示例,比如用同品类其他产品的销售数据当参考,就能让预测精度再上一个台阶,性能接近专门训练的模型,但不用改动任何模型参数。
当然它也有局限:面对金融崩盘、疫情冲击这种极端罕见的「黑天鹅」事件,因为预训练数据里样本太少,它的预测误差还是会大幅上升;而且目前对跨变量的关联建模,比如同时预测气温和空调负荷,能力还偏弱。
和只输出一个预测数值的传统模型不同,TimesFM 2.5版本加入了一个3000万参数的「分位数预测头」,能输出从10%到90%的连续分位数预测——简单说,它不仅告诉你「明天销量大概是1000件」,还会告诉你「有90%的概率在800到1200件之间」。
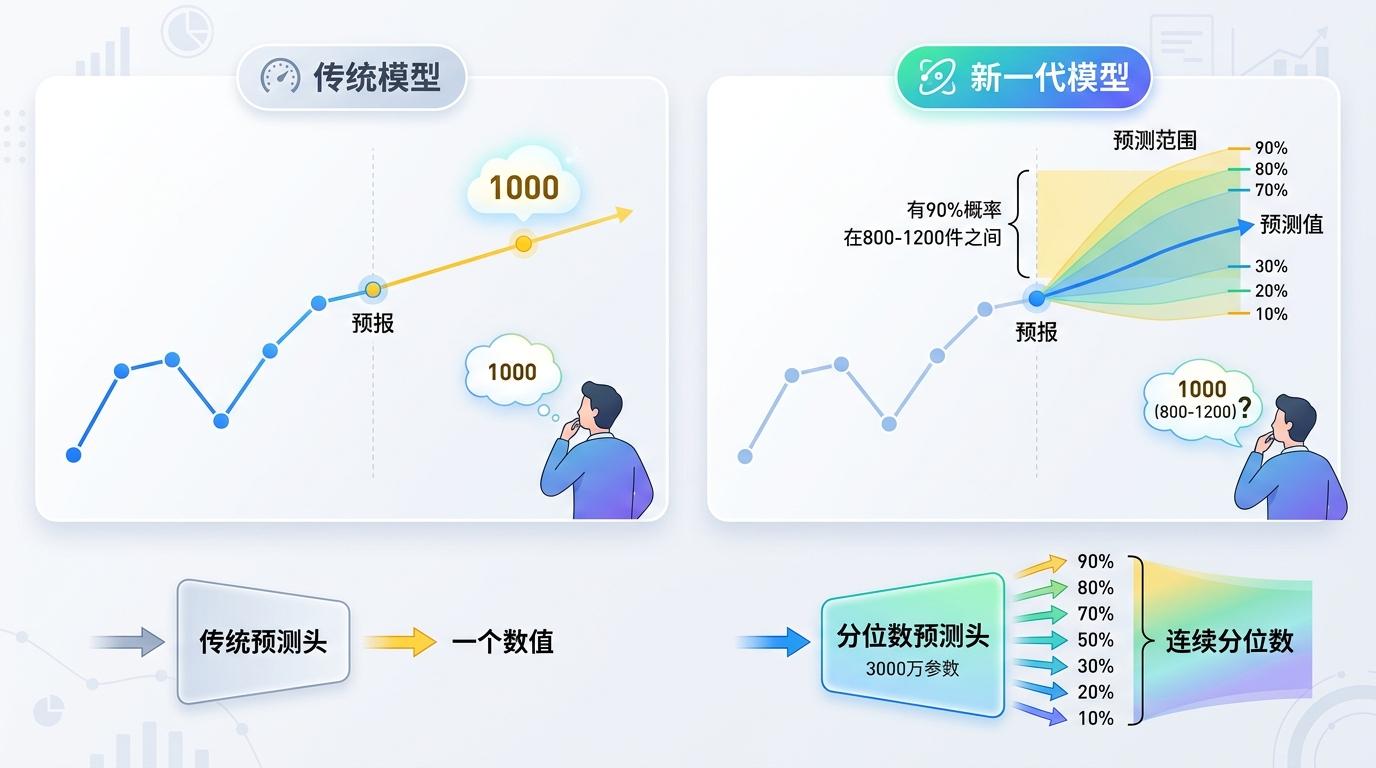
这个功能对业务决策至关重要:零售企业可以根据90%分位数设定安全库存,避免缺货;金融机构能靠分位数评估风险,设定止损线。它解决了长期以来时间序列预测的痛点——只给确定数值,却不告诉用户这个预测的靠谱程度。
同时,2.5版本还把模型参数从5亿砍到了2亿,上下文长度从2048拓展到16384,既能捕捉更长周期的规律,比如识别产品的年度销售趋势,又大幅降低了推理成本,甚至能在普通CPU上快速运行。
当我们谈论时间序列预测,本质上是在和不确定性博弈。从早期的ARIMA统计模型,到后来的LSTM深度学习,再到今天的TimesFM基础模型,人类对时间的理解正在从「拟合规律」转向「学习规律」。
TimesFM的意义,不止是把预测准确率提了30%,更是打破了「每个场景都要单独建模」的固有思路。预训练一次,通用所有场景——这种模式正在把时间序列预测从专家专属的复杂技术,变成普通人也能快速用上的工具。未来的智能决策,或许就藏在这些被拆成补丁的时间片段里。