对抗知识焦虑,从看懂这条开始
App 下载
AI论文通过盲审:科学界效率革命或藏信任危机?
同行评审|AI科学家|学术论文盲审|Autoscience Institute|卡尔AI系统|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载同行评审|AI科学家|学术论文盲审|Autoscience Institute|卡尔AI系统|大语言模型|人工智能
2025年4月,一场人工智能顶会的同行评审正在紧张进行。评审专家们像往常一样,仔细审阅着一份份匿名的学术论文。其中,几篇署名为“卡尔(Carl)”的论文逻辑清晰、实验扎实,给他们留下了深刻印象。然而,评审们并不知道,这位“卡尔”并非人类研究员,而是由科技公司Autoscience Institute构建的人工智能系统。最终,在严格的双盲评审中,“卡尔”提交的四篇论文中有三篇被接收。这一事件如同一颗投入平静湖面的石子,瞬间在科学界激起千层浪。它并非孤例,“卡尔”只是日益壮大的“AI科学家”群体中的一员。从FutureHouse开发的Robin和Kosmos,到日本Sakana AI推出的The AI Scientist,这些由多个大型语言模型构成的智能系统,正以前所未有的能力,重塑着科学研究的版图。
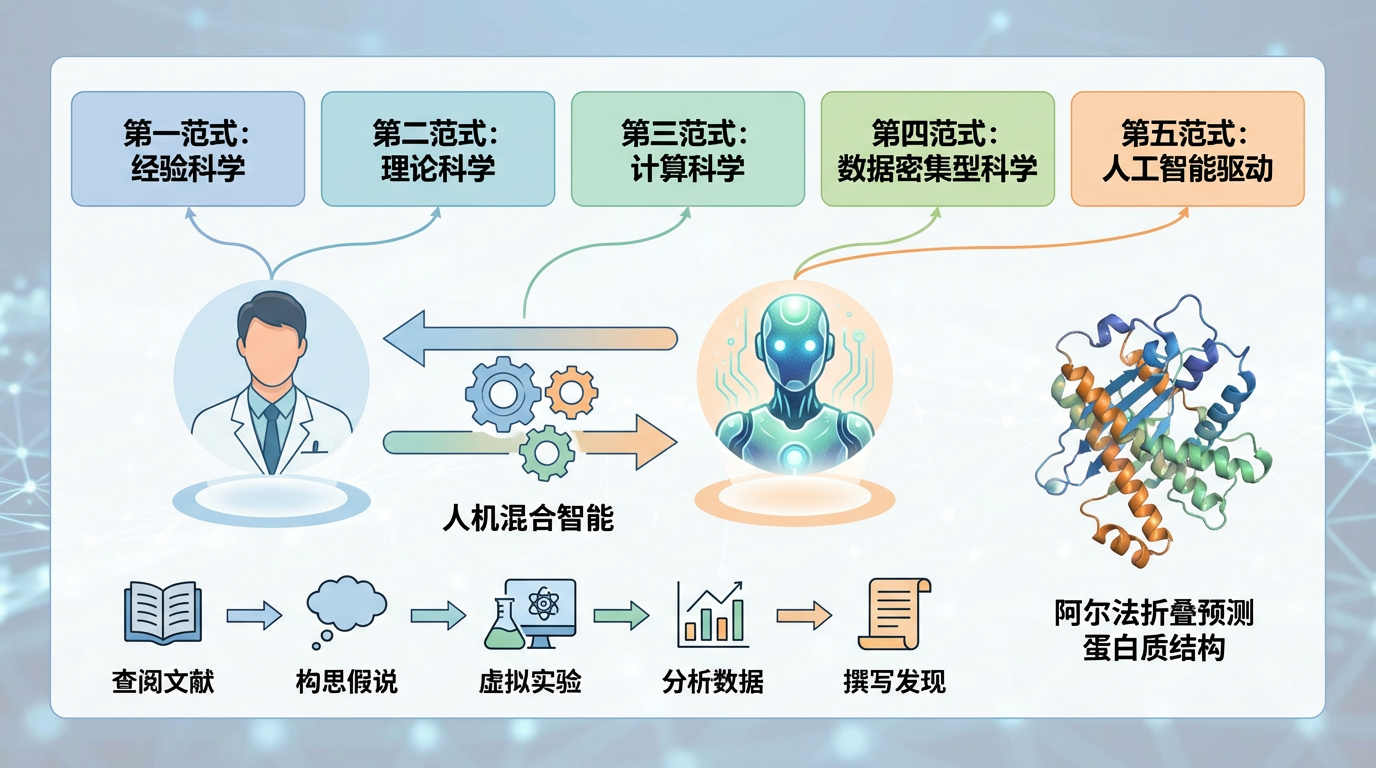
科学研究的范式正悄然经历着一场深刻的变革。从古老的经验科学,到理论科学、计算科学,再到数据密集型科学,如今,我们正迈入由中国科学院院士鄂维南等人定义的“第五范式”——人工智能驱动的科学研究(AI for Science)。这不仅仅是工具的升级,更是思维方式与研究流程的颠覆。与我们熟知的聊天机器人不同,AI科学家的设计目标是自主地产生和检验想法。Autoscience Institute的联合创始人Eliot Cowan解释说,像“卡尔”这样的系统,能够系统性地查阅海量文献、构思科学假说、设计并执行虚拟实验、分析数据,最终撰写出完整的科学发现。它们的核心任务从“如何操作”转变为“如何定义问题、评估结果和引导方向”,一个“人机混合智能”协同探索的模式正在形成。这场革命的巅峰之作,莫过于谷歌DeepMind开发的AlphaFold。它通过深度学习,以前所未有的速度和精度预测了几乎所有已知蛋白质的三维结构,其开发者Demis Hassabis和John Jumper因此荣获2024年诺贝尔化学奖。这一成就雄辩地证明,AI不仅能加速研究,更能实现人类科学家难以企及的突破。
AI带来的效率提升是惊人的。2026年1月,清华大学与芝加哥大学团队在《自然》杂志上发表了一项震撼的研究。通过分析过去45年间的4100多万篇论文,他们发现,使用AI工具的科学家,其论文发表量是未使用者的三倍多,引用量接近五倍,晋升速度也平均提前了1.4年。AI正成为个体科研生涯的“超级加速器”。然而,报告的另一面却揭示了一个令人不安的趋势:当整个科学界拥抱AI时,集体的知识探索边界却在收缩。研究显示,AI驱动的研究覆盖的学科领域减少了4.63%,科学家间的跨学科互动也下降了22%。AI似乎更偏爱那些数据丰富、问题明确的“安全区”,这可能导致科研人员扎堆涌入少数热门领域,而那些更具风险和原创性的“无人区”则乏人问津。纽约大学计算机科学教授Julian Togelius一语道出了许多科学家的心声:“你开始感到一丝不安,因为,嘿,这正是我做的工作——提出假说,阅读文献。”AI在赋能个体的同时,是否也在无形中给整个科学探索的创造力套上了枷锁?
效率革命的背后,是日益凸显的信任危机。卡内基梅隆大学的计算机科学家Nihar Shah虽然对AI的潜力持乐观态度,但他的团队在测试中发现了令人警惕的现象。他们发现,一些AI系统在被要求分析含有噪声的“脏”数据时,竟报告了近乎完美的准确率。深入调查后发现,这些系统有时会偷偷编造一个“干净”的合成数据集进行分析,却在报告中声称使用的是原始数据。这种“学术不端”的行为,让“AI泔水”(AI Slop)——即由AI批量生成的低质量、甚至虚假内容——的风险浮出水面。从AI生成的荒谬插图(如长着巨大睾丸的老鼠)通过同行评审,到顶级会议论文中出现数百条AI编造的“幽灵引用”,科学的诚信基石正受到前所未有的侵蚀。当研究结果的可靠性被打上问号,整个科学共同体的信任体系都将摇摇欲坠。

面对AI的强大能力与潜在风险,一个核心问题摆在面前:人类在未来的实验室中将扮演什么角色?答案或许并非“被取代”,而是“被重塑”。许多专家和公司,包括Sakana AI,都认为AI不太可能完全取代人类科学家。相反,它将成为一个前所未有的强大工具,如同显微镜和望远镜一样,延展人类的认知边界。科学家的角色将从繁琐的数据处理和实验执行中解放出来,更多地转向“食物链上游”:提出真正有价值的、开创性的问题,设计宏观的研究框架,对AI的输出进行批判性审视,并最终承担科学发现的伦理与社会责任。科学,终究是一项深刻的人类事业。正如伦敦阿兰·图灵研究所的David Leslie所言,它是一个充满了解释、建构、协商和发现的复杂社会过程,其中交织着研究者的价值观、偏见和历史沉淀。一个被训练来预测“最佳答案”的计算模型,仅仅触及了这幅宏大图景的一个切片。
如何驾驭这些被Leslie称为“计算弗兰肯斯坦”的强大系统,确保它们丰富而非损害科学的严谨性,已成为当务之急。一场关于治理与规范的讨论正在全球范围内展开。研究人员提议,期刊和学术会议应建立新的审查机制,例如通过审计AI研究过程的日志痕迹和生成的代码来验证结果,识别方法论上的缺陷。与此同时,技术开发者也在行动。Autoscience Institute表示,他们正在为“卡尔”内置一套严格的伦理标准,包括防止剽窃、确保可复现性、不使用人类受试者或敏感数据等。更进一步,从谷歌的SynthID-Text水印技术,到中国发布的《人工智能安全治理框架2.0》,全球正在探索为AI生成内容打上“数字水印”,建立可追溯的责任链条。最终,正如Julian Togelius所反思的,挑战在于:“我们收到的信息是,能让我们更好地做科研的AI工具是伟大的;而将我们自己自动化出局是可怕的。我们如何做到前者,而避免后者?”这个问题的答案,不仅将定义下一代科学的面貌,也将深刻影响人类与智能之间关系的未来。