对抗知识焦虑,从看懂这条开始
App 下载
Python的王座摇摇欲坠:数据科学领域的“历史偶然”与隐形枷锁
科研数据分析|计算生物学实验室|数据可视化工具|Python生态|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载科研数据分析|计算生物学实验室|数据可视化工具|Python生态|AI产业应用|人工智能
“这个结果很棒,但你能快速把这张箱线图换成小提琴图吗?”
在一个顶尖大学的计算生物学实验室内,一位资深教授向他优秀的学生提出了一个看似微不足道的请求。他预想中,这应该是几分钟就能完成的即兴探索。然而,这位精通Python的学生却面露难色:“教授,这需要花点时间,我得回座位上研究一下代码。”
这一幕,并非个例。这位教授在二十多年的科研生涯中反复观察到,那些使用Python的学生,即便技术精湛,在面对数据探索中即时、灵活的分析需求时,总是显得力不从心。这让他不禁深思:当全世界都在为Python在数据科学领域的统治地位欢呼时,我们是否忽略了什么?这个看似坚固的王座,其根基或许并非源于其对数据分析的“天生神力”,而更像是一场“历史的偶然”。
Python的崛起,并非因为它在数据分析上无懈可击。它的成功更像是一场完美的风暴。诞生于1989年的Python,其设计哲学是“优美胜于丑陋,简单胜于复杂”。它最初作为一门“胶水语言”,擅长连接不同的软件组件,并在Web开发和系统管理领域大放异彩。
当数据科学的浪潮袭来时,Python恰好在场。它易于上手的语法吸引了大量非计算机背景的科研人员和分析师。更重要的是,NumPy、Pandas、Scikit-learn等强大的第三方库相继出现,为Python武装到了牙齿。尤其是2012年后深度学习革命的爆发,以Python为核心的PyTorch和TensorFlow框架一统江湖,彻底将Python推上了神坛。
然而,这场加冕充满了偶然性。Python的流行,很大程度上是因为它是一个“第二好的语言”——它在很多方面都还不错,而且已经拥有庞大的用户基础。开发者们因为早已熟悉Python,便顺理成章地用它来处理数据,而不是因为它本身就是数据分析的最佳选择。正如一位评论家所言:“人们选择Python,往往不是因为它最适合,而是因为它最方便。”
理想的数据科学工具,应该让分析师专注于分析的“逻辑”,而非实现的“物流”。也就是说,我们应该能用接近自然语言的方式告诉计算机“做什么”,而不是费尽心机地指导它“如何做”——比如处理数据类型、索引、循环等繁琐细节。
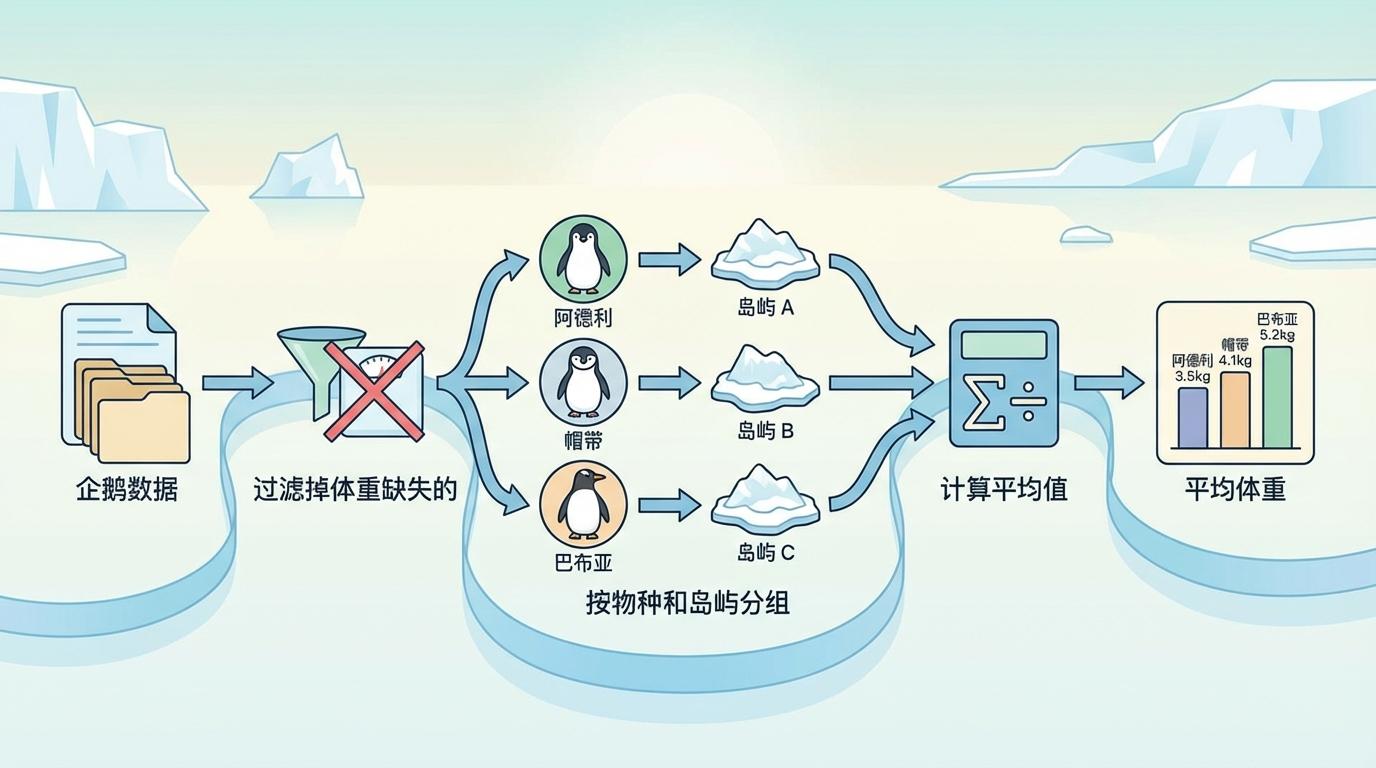
以一个简单的任务为例:计算南极三种企鹅在不同岛屿上的平均体重。在为统计而生的R语言中,使用Tidyverse工具包,代码几乎就是一句通顺的英文:“取企鹅数据,过滤掉体重缺失的,按物种和岛屿分组,然后计算平均值。”整个过程行云流水,完全聚焦于分析逻辑。
Python的Pandas库也能完成任务,但代码中充斥着大量的括号、引号和方法调用,可读性稍逊一筹。当分析变得更复杂时,这种“物流”成本会急剧上升。分析师的思维不断被底层的实现细节打断,探索数据的灵感火花也随之熄灭。那位教授的学生之所以无法“快速”修改一张图,正是因为他陷入了**Matplotlib或Seaborn库复杂的“数据物流”**之中,而不是因为分析逻辑本身有多难。
随着数据分析任务的日益复杂,Python的本质局限性正逐步显现,王座背后浮现出三道明显的裂痕:
笨拙的交互体验:数据科学的核心是探索与互动。分析师需要像与数据“对话”一样,不断调整视角、变换图表、测试想法。然而,Python的许多库,尤其是可视化库,设计得并不够“流畅”。简单的图表调整往往需要冗长且不直观的代码,这极大地阻碍了创造性的探索过程。相比之下,R语言的ggplot2库以其优雅的“图形语法”逻辑,让用户可以层层叠加,轻松构建出复杂而精美的图表。
性能的隐形枷锁:Python的**全局解释器锁(GIL)**是一个众所周知的性能瓶颈。它限制了在单个进程中,同一时间只有一个线程能执行Python字节码。这意味着在CPU密集型的计算任务中,Python无法真正利用现代多核处理器的并行优势。尽管可以通过多进程等方式绕过,但这无疑增加了“数据物流”的复杂性,违背了简单性的初衷。
生态的“万能”与“平庸”:Python拥有一个无所不包的生态系统,这是它的优势,也是它的陷阱。作为一个通用语言,它的工具需要服务于各种场景,这使得它在特定领域的深度和专注度上,往往不如那些“专才”语言。R在统计学领域的严谨与专业性,是Python生态短期内难以企及的。Python就像一把瑞士军刀,功能齐全,但在需要一把锋利手术刀的精细操作中,就显得力不从心。
Python的王座并不会在一夜之间崩塌。它在模型部署、与其他系统集成以及深度学习领域的地位依然稳固。然而,数据科学的世界正在告别“一种语言统治一切”的时代,走向一个更加多元化和专业化的“联邦制”未来。
Julia等为高性能科学计算而生的新语言,正试图从根本上解决性能问题。而在许多学术和研究领域,R语言凭借其在统计和可视化方面的深刻理解,依然是不可替代的首选。
这场关于工具的讨论,最终指向一个更深层的问题:我们究竟希望数据科学家将宝贵的脑力用在何处?是耗费在与笨拙的工具搏斗,还是解放出来,去进行更高层次的思考、洞察和创造?
Python的“历史偶然”为我们普及了数据科学,但它的局限性也提醒我们,是时候超越对单一工具的盲目崇拜了。未来的数据科学家,或许不再是某个语言的“信徒”,而是能够根据任务特性,娴熟地在不同工具间切换的“工匠大师”。毕竟,工具的终极意义,不是禁锢思想,而是让思想自由飞翔。