
12 小时前
12 小时前
2026年初,一位运营协调员在论坛发帖吐槽:测试了8款OCR工具处理200份多语种发票,结果把整齐的表格拆成了字母汤——Adobe、Google的工具全军覆没,号称专业的ABBYY也显得力不从心。而另一家公司用混合管道处理6000份贷款文档,却把耗时从2天压缩到30分钟。同样是文档自动化,为何一边是地狱,一边是天堂?这背后藏着当前智能文档处理最核心的破局逻辑。
你可以把混合管道理解成一家分工明确的文档加工厂:第一步,由OCR(光学字符识别)或布局模型负责「拆包」——把扫描件、照片里的文字、表格、图片位置精准识别出来,转换成结构化的Markdown格式,就像把混乱的仓库整理成货架上的商品;第二步,大语言模型(LLM)负责「拣货」——根据业务需求从结构化文本里提取关键信息,比如发票的金额、合同的条款,还能做逻辑推理,比如核对发票金额和税率是否匹配。
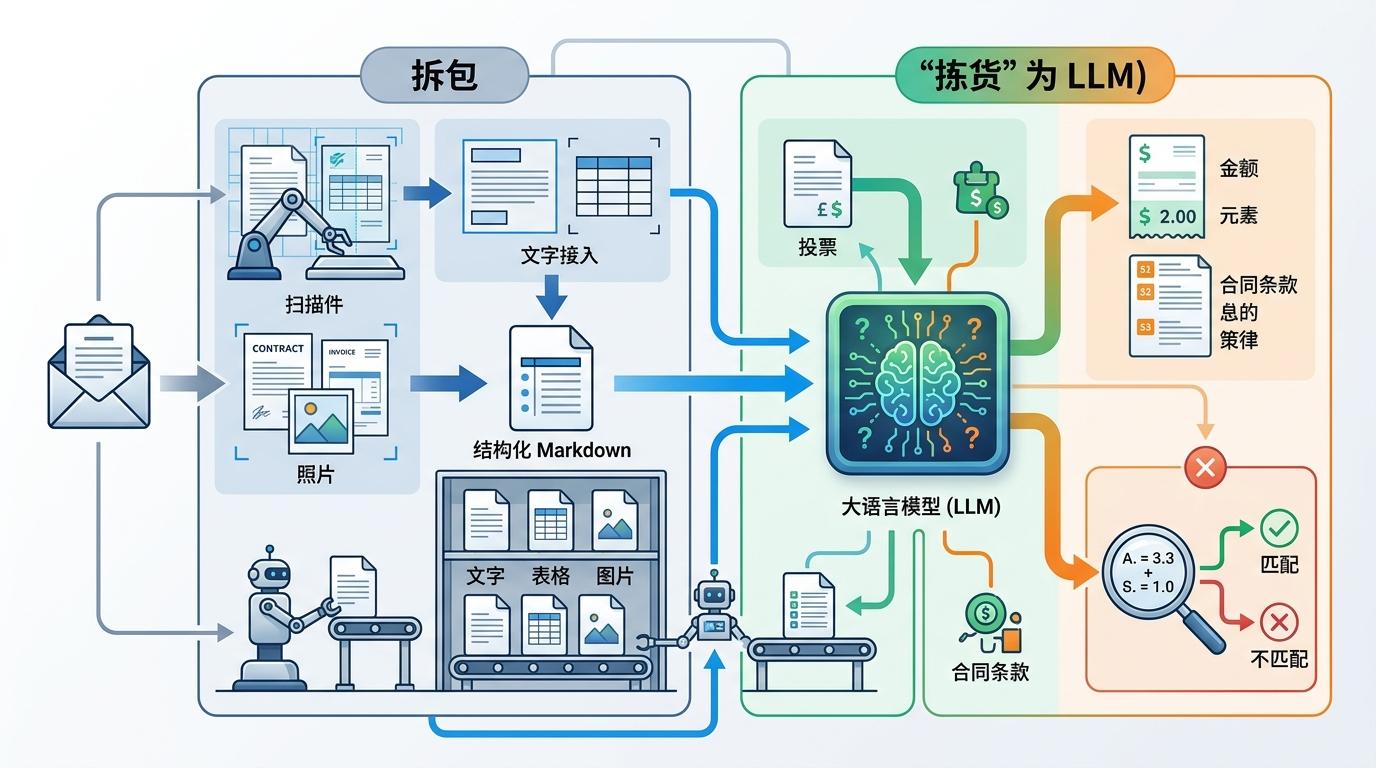
但真实的机制比这更精确:传统OCR擅长处理清晰的印刷体,却搞不定手写、复杂表格或模糊的扫描件;视觉语言模型能理解语义,却容易「 hallucinate(幻觉)」——编造文档里没有的信息。混合管道就是让OCR做它擅长的字符识别,把语义理解和复杂推理交给LLM,再用多层验证机制给结果「把关」。
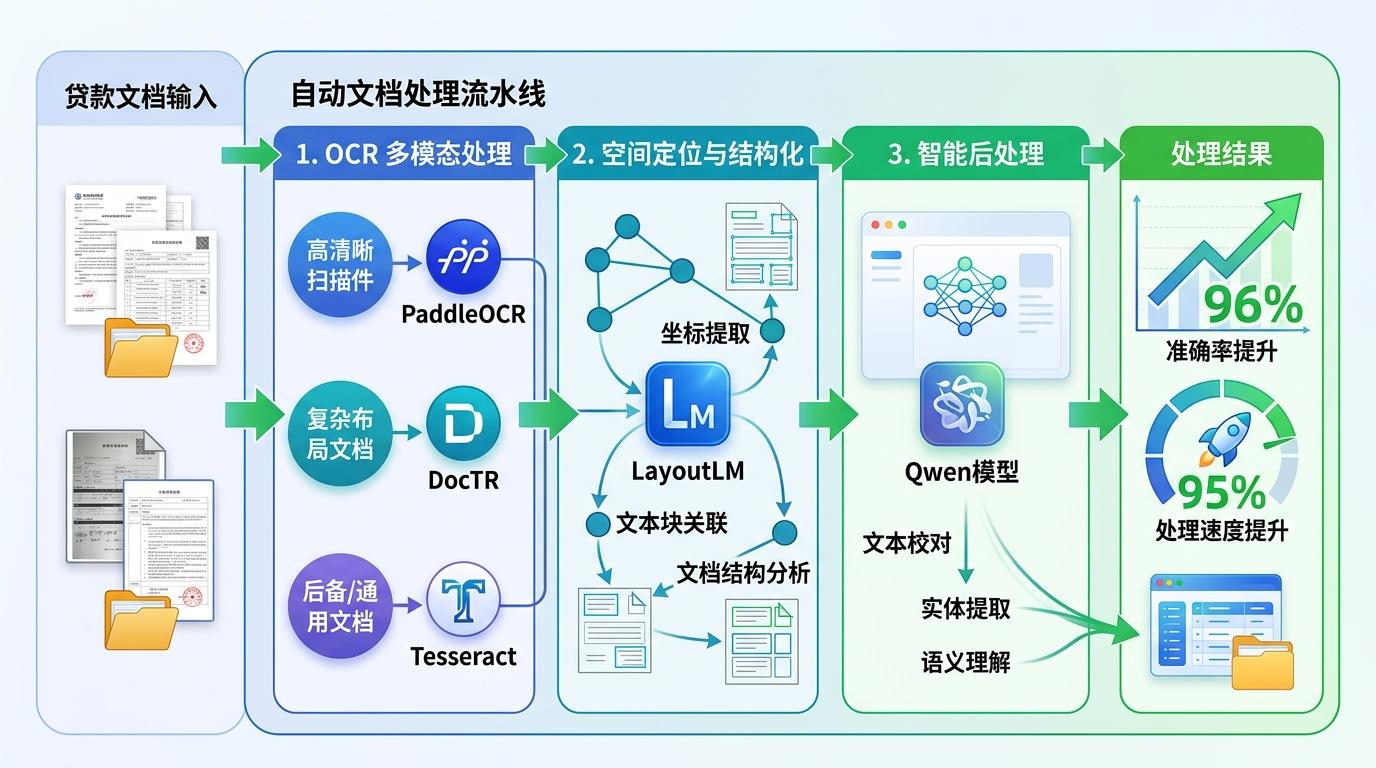
有团队用这套思路搭建了贷款文档处理流水线:用PaddleOCR处理清晰扫描件,DocTR应对复杂布局,Tesseract当后备,LayoutLM做空间定位,最后用Qwen模型做后处理,准确率直接冲到96%,处理速度提升了95%。
如果说文档自动化有什么「不可能完成的任务」,表格绝对算一个。企业里40%-60%的关键信息都藏在表格里——财务报表的合并单元格、医疗记录的跨页表格、科研论文的多层表头,这些结构让传统OCR直接罢工:要么把单元格拆得七零八落,要么把表头和内容搞混。就算是先进的视觉语言模型,处理跨页表格的成功率也只有70%左右,剩下的30%还得靠人工补漏。
另一个更隐蔽的坑是LLM的「幻觉」。有团队用GPT-4处理15万手写文档,第一页准确率能到85%,到第三页就掉到65%,模型还会偷偷把第一页的检查员名字,硬塞到第三页的签名栏里。这种「悄无声息的错误」最可怕——你以为系统跑通了,其实错误数据已经流进了下游的财务、生产系统,等发现时可能已经造成了几十万的损失。
现在行业里的应对方案,一是用「多模型投票」——让几个不同的OCR和LLM分别处理,结果一致才通过;二是加「人工复核闸门」——把低置信度的文档自动推给人工审核,像银行的风控系统一样,把风险拦在门外。
当企业终于解决了准确率和稳定性的问题,又撞上了隐私和成本的墙。欧盟GDPR、美国HIPAA这些法规要求,敏感数据不能随便传到云端——金融机构的客户资料、医院的病历,要是传到美国云服务商那里,可能会被当地政府调取。于是很多企业开始转向「本地部署」:有人花2000欧元在eBay买了台二手Mac Studio,把所有模型都跑在本地,每月100美元的云API费用直接省了,还完全不用担心数据泄露。
但本地部署也不是免费午餐:你得自己维护硬件、更新模型、处理故障,对技术团队的要求很高。中小企业往往陷入两难:用云服务怕隐私问题,自己搭又没技术能力。现在行业里的折中方案是「混合云」——敏感数据在本地处理,非敏感数据用云服务,既合规又能享受到云的算力优势。
有意思的是,开源工具成了这场本地化战争的主角。PaddleOCR、Docling、Marker这些开源工具,性能已经能追上商用软件,而且完全免费。有开发者说,用开源工具搭建的流水线,性能比某商用IDP平台还强,成本却只有后者的1/10。
现在再回头看开头的那个问题:为什么同样是文档自动化,有的团队在地狱,有的在天堂?答案很简单:那些跑通了的团队,都放弃了「用一个工具解决所有问题」的幻想,转而拥抱混合管道——让专业的模型做专业的事,用人的智慧补AI的漏洞,用本地化解决隐私焦虑。
自动化的本质,不是取代人,而是让人做更有价值的事。 未来的文档处理系统,会更像一个「人机协作的伙伴」:AI负责处理重复、机械的工作,人负责判断复杂、高风险的情况,两者配合,把准确率拉到接近100%,把成本降到最低。毕竟,在企业里,数据的准确性永远比自动化的速度更重要。
点击催更,成为大圆镜下一个视频选题!