对抗知识焦虑,从看懂这条开始
App 下载
被遗忘的bzip,成了代码压缩的隐形冠军
LibDeflate|Minecraft模组|BWT变换|代码压缩|bzip算法|计算科学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载LibDeflate|Minecraft模组|BWT变换|代码压缩|bzip算法|计算科学|数理基础
一个Minecraft模组开发者盯着327KB的Lua代码文件夹犯愁——磁盘空间告急,必须压缩,但常用的LibDeflate解码器体积大到抵消了压缩收益。他测试了几乎所有主流压缩工具:zopfli、zstd、xz、brotli……结果让他意外:被xz、zstd挤到边缘的bzip家族,把压缩率拉高了一大截,甚至比号称“比bzip2更能压缩”的lzip表现还好。为什么一款被认为“过时”的算法,能在代码压缩上击败一众新贵?答案藏在它最核心的BWT变换里。
你可以把主流压缩算法(比如gzip、zstd)的核心逻辑,想象成写论文时的“引用标注”——看到重复的句子,就标上“见第3页第2段”,用短指针代替长文本。这就是LZ77算法的本质:在滑动窗口里找之前出现过的最长重复串,用“偏移量+长度”的指针替代,再配合霍夫曼编码压缩指针本身。这套逻辑快、灵活,适合大部分场景,但碰到代码这种“局部重复多、长重复少”的文本,就像用大网捞小鱼——效率有限。
而bzip用的BWT变换(Burrows-Wheeler变换,一种可逆的文本重排算法),走的是另一条路:它先把文本的所有循环旋转版本列出来,按字典序排序,再提取排序后所有字符串的最后一列。比如输入“banana$”,经过旋转排序后,最后一列会变成“annb$aa”——原本分散的“a”被聚在了一起,“n”也形成了连续片段。
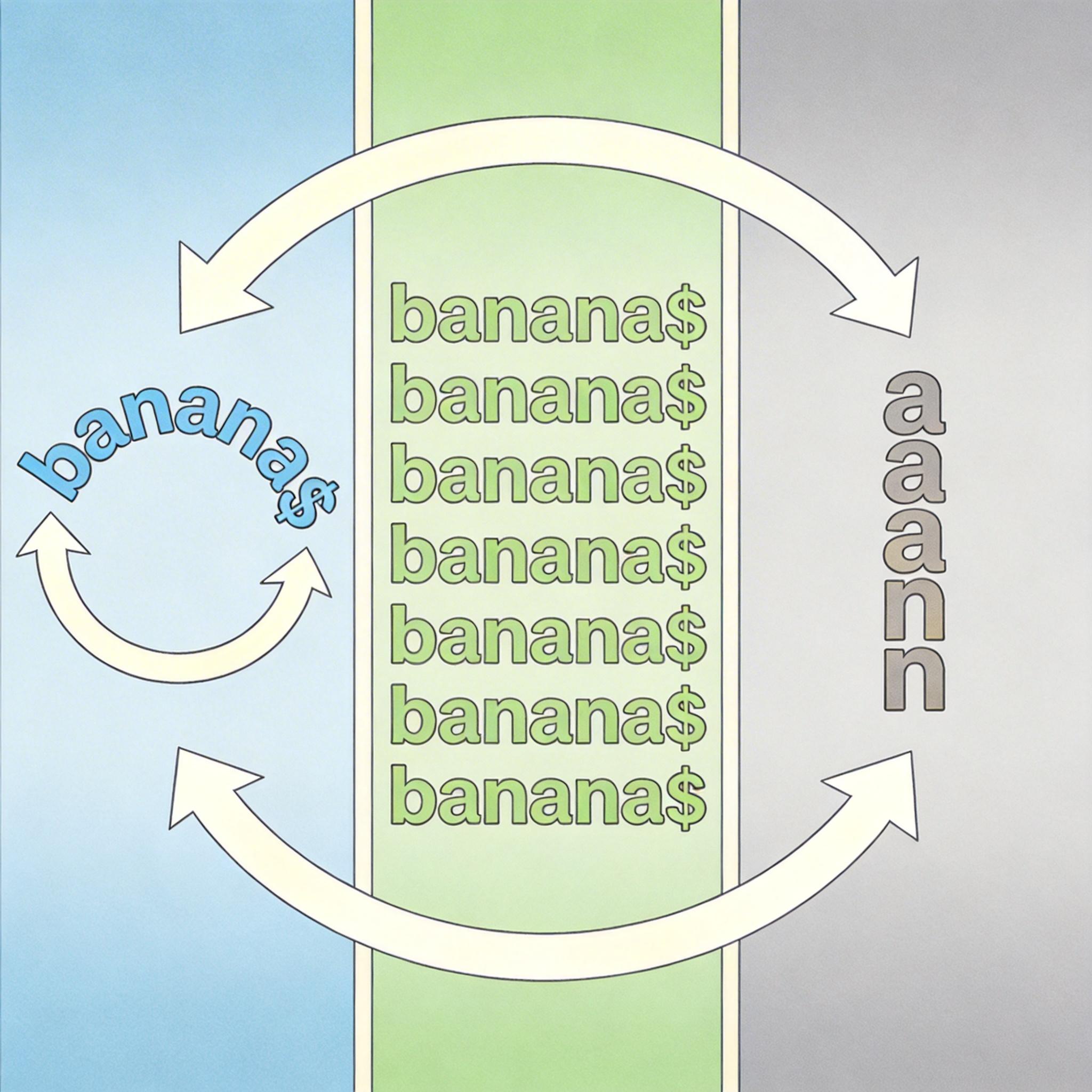
直给补刀:BWT本身不压缩数据,但它把相同字符“抱团”的特性,让后续的游程编码(RLE)能把连续的“a”直接写成“3个a”,压缩效率瞬间拉满。这就像把散落在房间里的同款玩具堆成一堆,打包时能省出一半空间。
你可能注意过,gzip有1到9级压缩,zstd甚至有几十级可调——这背后是LZ77算法的“启发式”逻辑:为了平衡速度和压缩率,算法会用不同策略找重复串,比如低级别的只找近窗口,高级别的会遍历更大范围。但这种“灵活”也意味着不确定性:同样的文件,换个压缩级别结果可能差很多,甚至不同版本的工具都有差异。
而bzip的世界里没有“压缩级别”——bzip3甚至连参数都不需要。因为BWT变换是完全确定的:给定一段文本,不管跑多少次,输出的重排结果都一模一样。它不需要“找重复”的复杂策略,只需要完成排序和提取两个步骤,后续的游程编码和霍夫曼编码也都是标准化流程。
这种确定性带来了两个隐形优势:一是压缩结果稳定,不会因为参数调错浪费空间;二是解码器可以做的极小——核心的BWT逆变换只需要约250字节代码,加上游程编码和霍夫曼解码,整个解码器能控制在1.5KB以内,比LibDeflate小了不止一个量级。对于Minecraft模组这种“字节寸金”的场景,这才是真正的“性价比”。
当然BWT也有软肋:如果把英式英语和美式英语的文本混在一起,“colour”和“color”的“u”和“r”会打乱字符聚集的效果,压缩率会下降。但对于结构稳定、重复模式一致的代码,这个问题几乎不存在。
你可能想不到,BWT这种“过时”的压缩技术,如今成了生物信息学的核心工具。人类基因组有30亿个碱基对,其中重复序列占了近一半——BWT的字符聚集能力,正好能把这些重复的碱基串“打包”,同时构建出能快速查询的FM索引。现在主流的基因组比对工具BWA、Bowtie,全都是基于BWT技术:它能在几十GB的基因组数据里,几秒内找到一段短序列的位置,比传统方法快上百倍。
在代码压缩之外,BWT还悄悄出现在恶意软件检测、文本搜索等领域。比如用BWT把恶意软件的二进制代码转换成特征向量,能快速识别变种病毒——因为同一家族的病毒,代码结构的重复模式高度相似,经过BWT变换后会呈现出几乎一样的“特征指纹”。
我认为,BWT的逆袭不是偶然:它代表了一种被忽略的技术思路——比起追求“全能”的复杂算法,有时候把一件事做到极致,反而能在特定场景下不可替代。就像bzip,虽然压缩速度不如zstd,通用压缩率不如xz,但在代码、文本这种“高重复、低噪声”的数据上,它的效率至今无人能及。
当我们谈论“先进技术”时,总习惯把目光投向最新的算法、最快的速度,却常常忘了那些“过时”的技术里,藏着最朴素的智慧。BWT没有花哨的参数,没有复杂的启发式策略,它只是把相同的字符聚在一起——就像整理房间时把同类物品放在一起,简单,却有效。
把同类的东西聚在一起,就是最高效的压缩。这句话不仅适用于代码,也适用于我们处理信息的方式:比起追求多而全的工具,找到那个能精准解决特定问题的“笨方法”,往往能带来意想不到的惊喜。bzip的故事告诉我们:技术没有绝对的过时,只有被放错的场景。