对抗知识焦虑,从看懂这条开始
App 下载
芯片一年一换代,数据中心刚建好就过时
数据中心建设|Oracle|OpenAI|Vera Rubin芯片|Nvidia Blackwell芯片|消费电子|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据中心建设|Oracle|OpenAI|Vera Rubin芯片|Nvidia Blackwell芯片|消费电子|AI算力|前沿科技|人工智能
当OpenAI放弃德州阿比林的Stargate数据中心扩建计划时,Oracle已经砸下了数十亿美元——买地、订硬件、招员工,就等着给OpenAI的大模型喂算力。但OpenAI嫌慢:这个要等一年才能用上Nvidia Blackwell芯片的项目,在它眼里已经过时了。毕竟等到明年,Nvidia的下一代Vera Rubin芯片就能交付,那可是能把Blackwell的推理性能拉到5倍的狠角色。没人愿意为‘去年的旗舰’买单,哪怕它还没拆封。为什么芯片的迭代速度,能快到把耗资数十亿的数据中心变成‘昨日黄花’?
Nvidia CEO黄仁勋把芯片迭代的油门踩到底了。过去这家公司每两年才推一代数据中心芯片,现在是一年一款,每代都是性能跳级。2026年刚量产的Vera Rubin,比2024年的Blackwell强5倍;而Blackwell本身,又比前一代Hopper的推理能效高25倍。
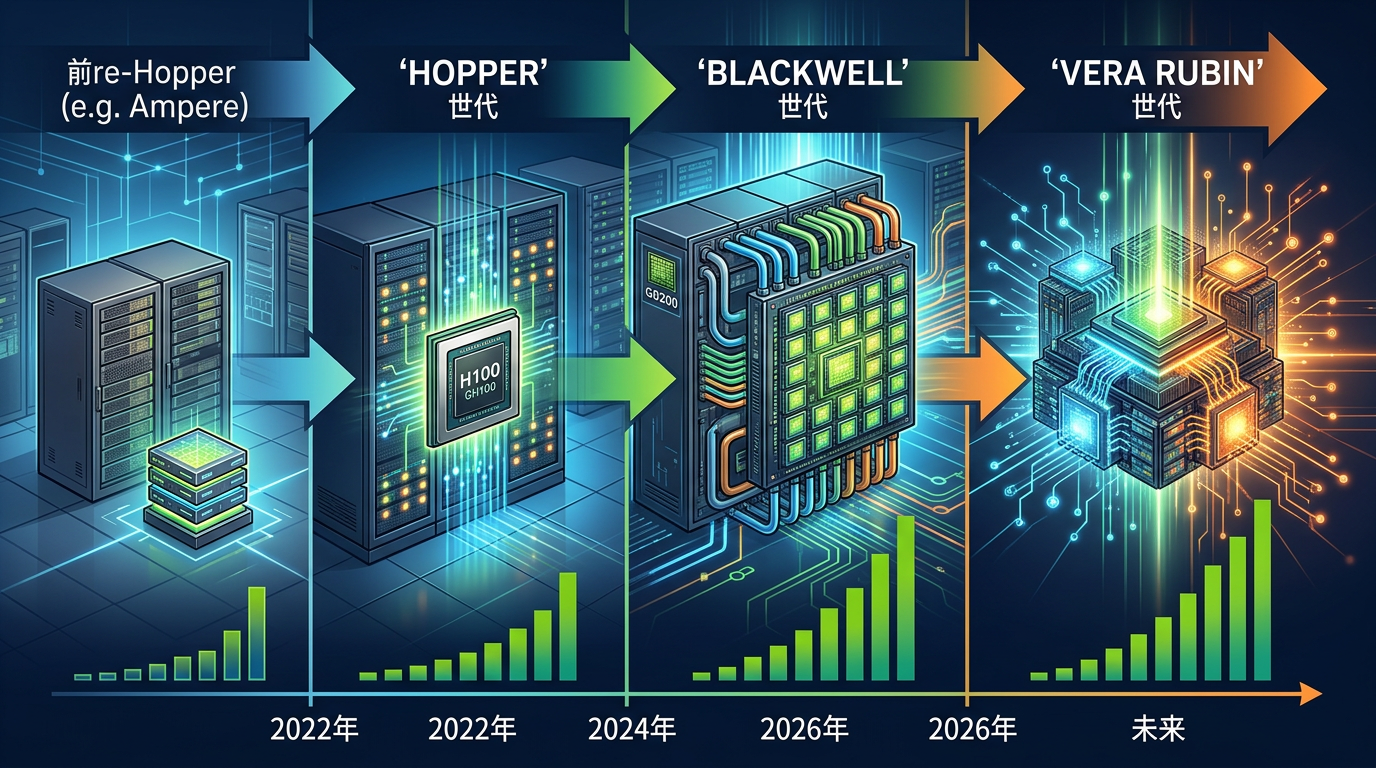
你可以把这想象成手机行业的‘年年旗舰’,但AI芯片的性能差距直接关联真金白银。对OpenAI这种做前沿模型的公司来说,哪怕是10%的性能提升,都能在模型排行榜上拉开差距——而排行榜的名次,直接挂钩开发者的选择、用户量和估值。就像手机厂商抢首发骁龙芯片,AI公司也得攥着最新的GPU才能在赛道上站住脚。
但数据中心不是手机,建一个要12到24个月:找地、接电网、搭机房、装设备,每一步都要走流程。等你把Blackwell芯片的机架摆满机房,黄仁勋的下一代芯片已经在台积电的产线上了。
更棘手的是账本上的数字。
传统数据中心的服务器折旧周期是5到6年,但AI芯片的‘技术寿命’只有1到3年——在前沿训练任务里,旧芯片很快就会被新芯片的性能碾压。但云厂商们又舍不得直接淘汰,于是搞出了‘价值级联’:先让GPU干最累的模型训练,1到2年后转去做实时推理,再后来降格处理批量分析。这么一套操作下来,芯片的‘经济寿命’能拉长到5到7年。
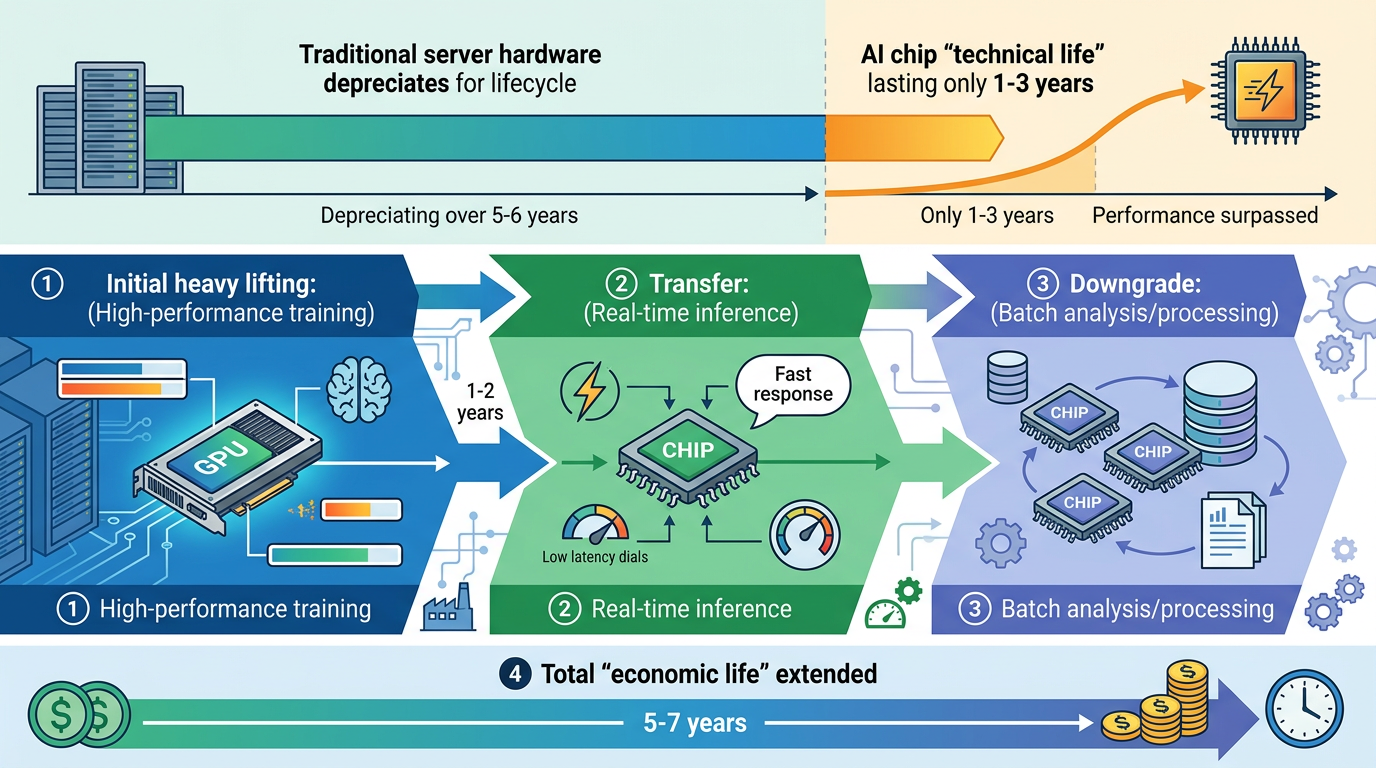
但这中间的矛盾藏着风险。著名投资人Michael Burry算过一笔账:如果科技公司还抱着5到6年的折旧周期,到2028年可能会低估1760亿美元的折旧费用,相当于把泡沫捂在了账本里。亚马逊已经开始慌了,2025年把部分服务器的折旧周期从6年砍回5年,直接多提了7亿美元的折旧;而Meta反其道而行之,把周期拉长到5.5年,一下少了23亿的折旧支出——两家公司的操作,把折旧政策的‘弹性’暴露得明明白白。
最尴尬的是Oracle。它靠1000多亿美元的债务砸数据中心,结果OpenAI的扩建计划黄了,股价今年跌了23%,从高点腰斩。那些砸在德州的钱,可能要变成账面上的‘闲置资产’。
有人在这场竞速里找到了新玩法。
CoreWeave这种AI专用云服务商,干脆放弃了‘长期持有’的思路。他们用高密度液冷机房堆最新的GPU,靠短租模式快速周转——客户要的就是当下最强的算力,谁也不想租过时的芯片。而微软则在另一端搞循环经济:全球的Circular Centers每年能让90%以上的服务器组件重新利用,旧GPU哪怕不能训练大模型,还能去做推理或者给小公司用。2024年他们光重新部署的组件就有320万个,相当于省了几十亿的硬件成本。
监管层也盯上了这个问题。SEC已经在考虑加强折旧政策的披露要求,逼着公司说清楚:你的芯片到底能用几年?残值还剩多少?毕竟当整个行业都在往AI里砸钱的时候,账本上的泡沫一旦破了,可不是几家公司的事。
当芯片的迭代速度跑赢了基建的节奏,整个AI算力行业都在被迫调整姿势。过去那种‘建个机房吃十年’的逻辑,在黄仁勋的‘年度更新’面前彻底失效了。
算力的战争,拼的不只是性能,更是周转速度。
未来的数据中心可能不再是‘百年工程’,而是像快消品一样快速迭代;或者像微软那样,把每一块GPU的价值榨干到最后一秒。但无论哪种选择,都绕不开一个核心:在技术飞速狂奔的时代,最昂贵的不是硬件,是跟不上节奏的执念。