
20 天前
20 天前
2020年1月的一个清晨,底特律居民罗伯特·威廉姆斯刚送完女儿去 daycare,就被突然冲来的警察按倒在地。他被指控盗窃了一家手表店的商品,证据是警方人脸识别系统的匹配结果——监控里的模糊人影,和他驾照上的照片“对上了”。
但威廉姆斯有完美的不在场证明:案发时他正在上班,同事和公司监控都能作证。30小时的拘留后,警方才承认系统认错了人。这场无妄之灾,让他的女儿留下了心理阴影,自己也患上了PTSD。
你可能觉得这是极端个案,但实际上,人脸识别的误差正潜伏在我们生活的各个角落。为什么技术明明越来越准,却还会把无辜者送进警局?
要理解威廉姆斯的遭遇,得先搞懂人脸识别最核心的两个误差:假阳性和假阴性。你可以把算法比作一个守门的保安:
这两种误差就像天平的两端,没法同时降到最低。调高标准减少假阳性,就会增加假阴性;放宽标准减少假阴性,假阳性又会飙升。在边境检查这种理想场景下,假阳性率低于百万分之一,假阴性率也只有千分之二——就算被拦下来,人工复核就能解决。
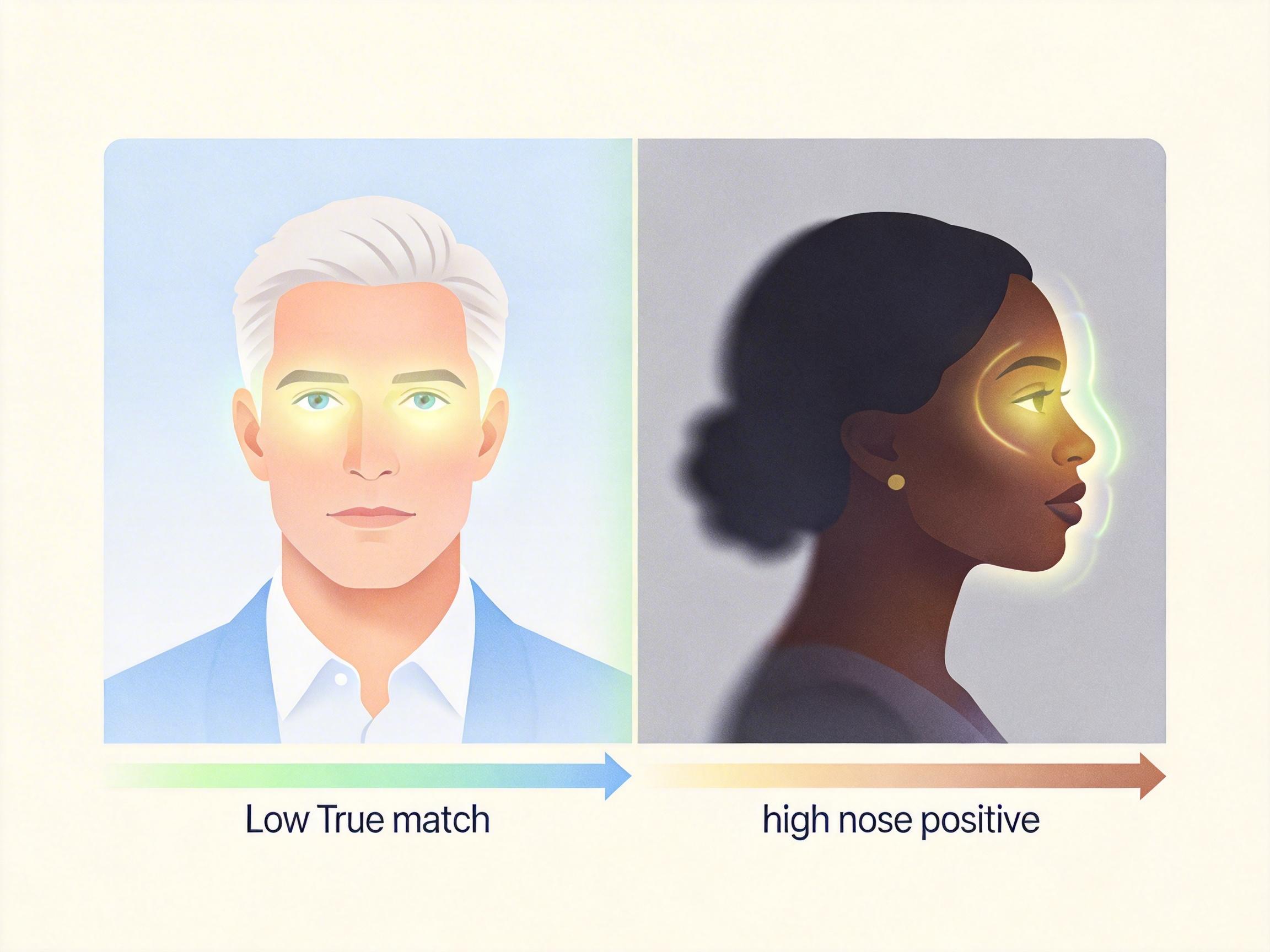
但到了真实世界的安防场景,一切都变了。监控画面可能是低光照、侧脸、模糊的,数据库里的照片可能是几年前的旧照。美国国家标准与技术研究院(NIST)2019年的测试显示,当用监控图比对旧 mug shot 时,部分算法对黑人女性的假阳性率,比对白人男性高了100倍。
算法的偏见,本质上是训练数据的偏见。目前主流的人脸识别数据集,比如Labeled Faces in the Wild,83.5%都是白人面孔,男性占比更是远超女性。就像让一个只见过白人的保安去认黑人,出错是必然的。
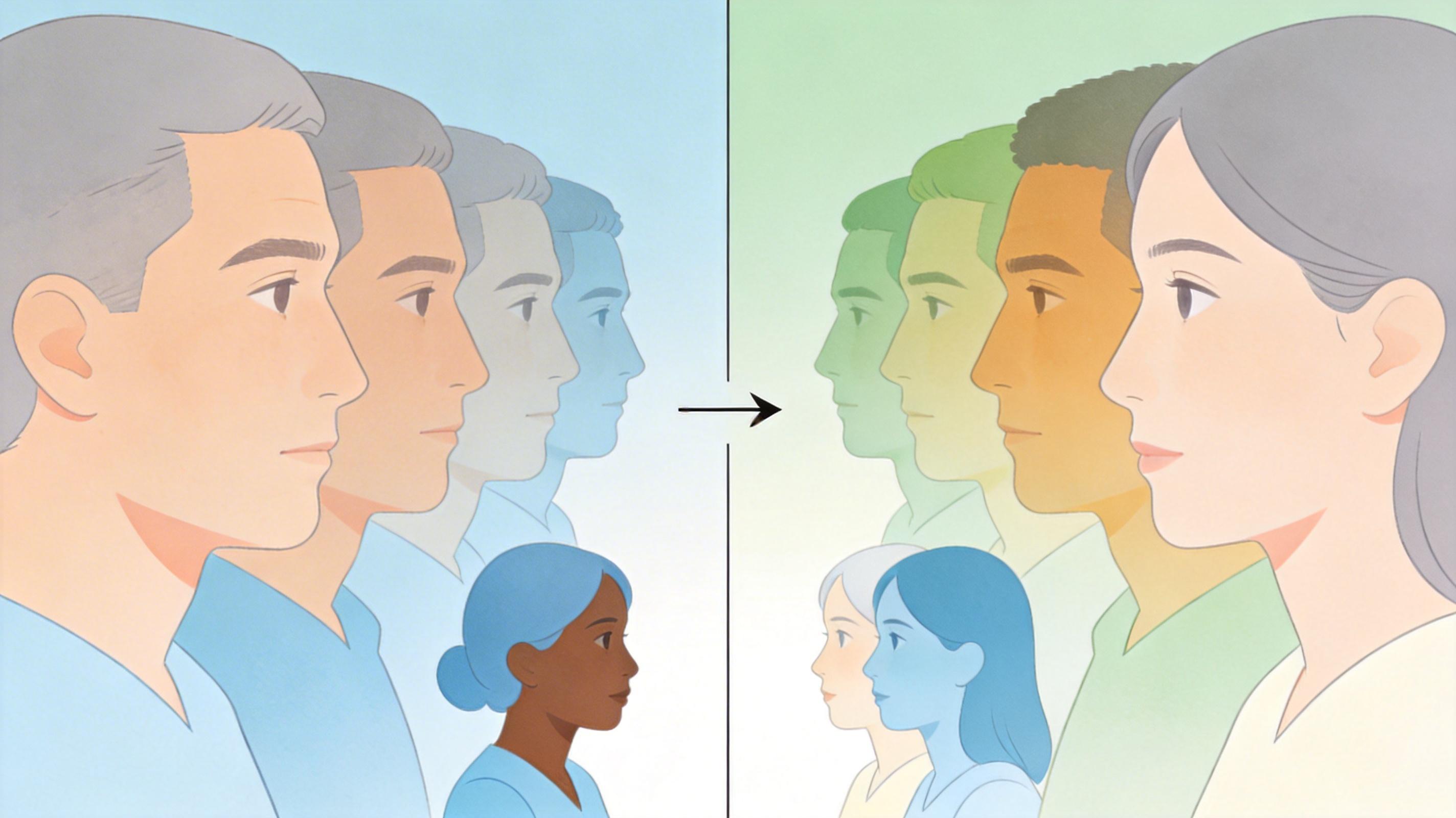
这种数据偏差不是无心之失,而是社会权力结构的投射——训练数据多来自公众人物和警方数据库,而这些领域长期由白人男性主导。加拿大法学助理教授吉迪恩·克里斯蒂安指出,白人男性的识别准确率能超过99%,但黑人女性的错误率可能高达35%。
更隐蔽的是,硬件也在放大偏见。普通摄像头的传感器是针对浅色皮肤优化的,深色皮肤在低光照下的特征会被“吃掉”,算法自然没法准确识别。当警方过度依赖这种有偏见的系统,就会形成恶性循环:数据库里黑人的记录越多,算法越容易把黑人错认成嫌疑人,进而导致更多黑人被错误逮捕,数据库里的偏见又被进一步强化。

2023年,美国连锁药店Rite Aid就因为使用有种族偏见的人脸识别系统,被法院禁止使用该技术五年——系统多次把黑人顾客错认成小偷,导致无辜者被当众拦下搜身。
要解决人脸识别的公平性问题,首先得从数据入手。麻省理工学院的研究团队提出了一种精准去偏技术:用TRAK算法找出训练数据里那些最容易导致偏见的样本,只删除这些“坏数据点”,而不是像传统方法那样大规模删减少数群体的样本。在实验中,这种方法只用了传统方法1/10的样本删除量,就把少数群体的识别准确率提升了15%。
合成数据也成为补充多样性的新途径。IBM发布的“Diversity in Faces”数据集,包含100万张标注了年龄、性别、颅面特征的合成人脸,覆盖了不同种族和年龄段。不过斯坦福大学的研究也提醒,合成数据不能替代真实数据——如果合成的少数群体样本不符合真实特征,反而会加剧偏见。
规则层面的约束同样重要。底特律在威廉姆斯案后出台了全美最严格的人脸识别政策:仅凭算法结果不能申请逮捕令,必须辅以其他独立证据;警方还要对2017年以来所有用人脸识别的案件进行审计。欧盟的AI法案则直接把人脸识别归为“高风险AI”,要求必须经过严格的公平性测试才能使用。
当我们为人脸识别的便利欢呼时,往往忽略了它背后的代价——那些被错认的无辜者,那些被算法放大的社会偏见,都是技术发展必须承担的“隐形成本”。
技术本身没有善恶,但使用技术的人,必须为它的后果负责。算法的公平,从来不是技术问题,而是社会问题。只有当我们把每一个群体的权益都放进训练数据里,把每一次误判的代价都算进技术的成本里,人脸识别才不会成为新的歧视工具,而是真正服务于所有人的技术。
毕竟,威廉姆斯的遭遇,不应该是任何一个普通人的“万一”。
点击充电,成为大圆镜下一个视频选题!