
19 小时前
19 小时前
做胃镜时的恶心感、肠镜前喝泻药的崩溃,是很多人对胃肠病检查的第一印象——这些精准却侵入性的手段,不仅让患者望而却步,还可能错过疾病最早期的信号。2026年4月,英国伯明翰大学团队的一项研究,给这一困局带来了新的破局点:他们用AI分析肠道微生物和代谢物数据,发现胃癌的生物标志物能预测炎症性肠病,结直肠癌的模型能识别胃癌信号。这意味着,未来或许只要一份粪便样本,就能同时排查多种胃肠疾病的风险。
把肠道想象成一个热闹的社区,细菌是这里的居民,它们产生的代谢物就是社区里的各种活动产物。当社区出问题时,居民组成和活动模式会先出现异常——这就是肠道微生物与代谢物作为疾病标志物的核心逻辑。
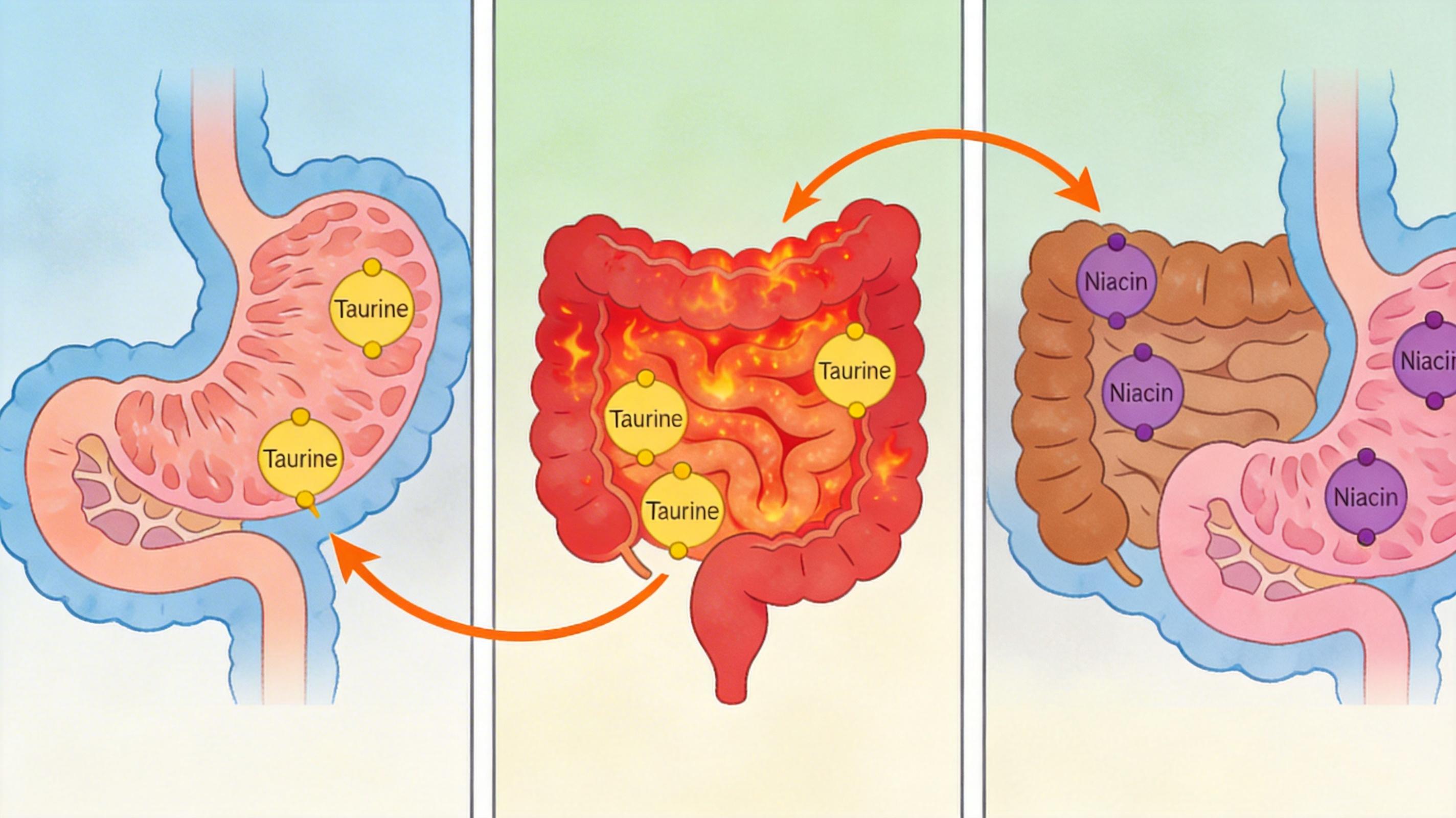
过去的研究大多盯着单一疾病:比如胃癌患者肠道里的厚壁菌门、拟杆菌门细菌会增多,结直肠癌患者则伴随 Fusobacterium(具核梭杆菌)和异亮氨酸的异常。但伯明翰大学的团队换了个思路,他们用AI模型同时分析胃癌、结直肠癌和炎症性肠病患者的微生物组与代谢组数据,结果发现了更有意思的关联:用胃癌数据训练的模型,能精准识别炎症性肠病的标志物;而结直肠癌的模型,居然能预测胃癌的风险信号。
这不是偶然。研究人员对比了三类疾病的微生物和代谢物特征,发现它们共享着部分“异常信号”:比如胃癌中出现的牛磺酸代谢变化,在炎症性肠病患者体内也能找到;结直肠癌患者肠道里的烟酰胺异常,同样会出现在胃癌患者身上。这些共享信号,揭开了胃肠疾病之间隐藏的关联——它们可能并非独立发生,而是共享着某些炎症或代谢紊乱的通路。
要从海量的微生物和代谢物数据里找出共享信号,靠人工分析几乎不可能。伯明翰团队用的是机器学习里的迁移学习思路:先让模型在一种疾病的数据集里“学会”识别异常特征,再把这种能力迁移到另一种疾病的分析中。
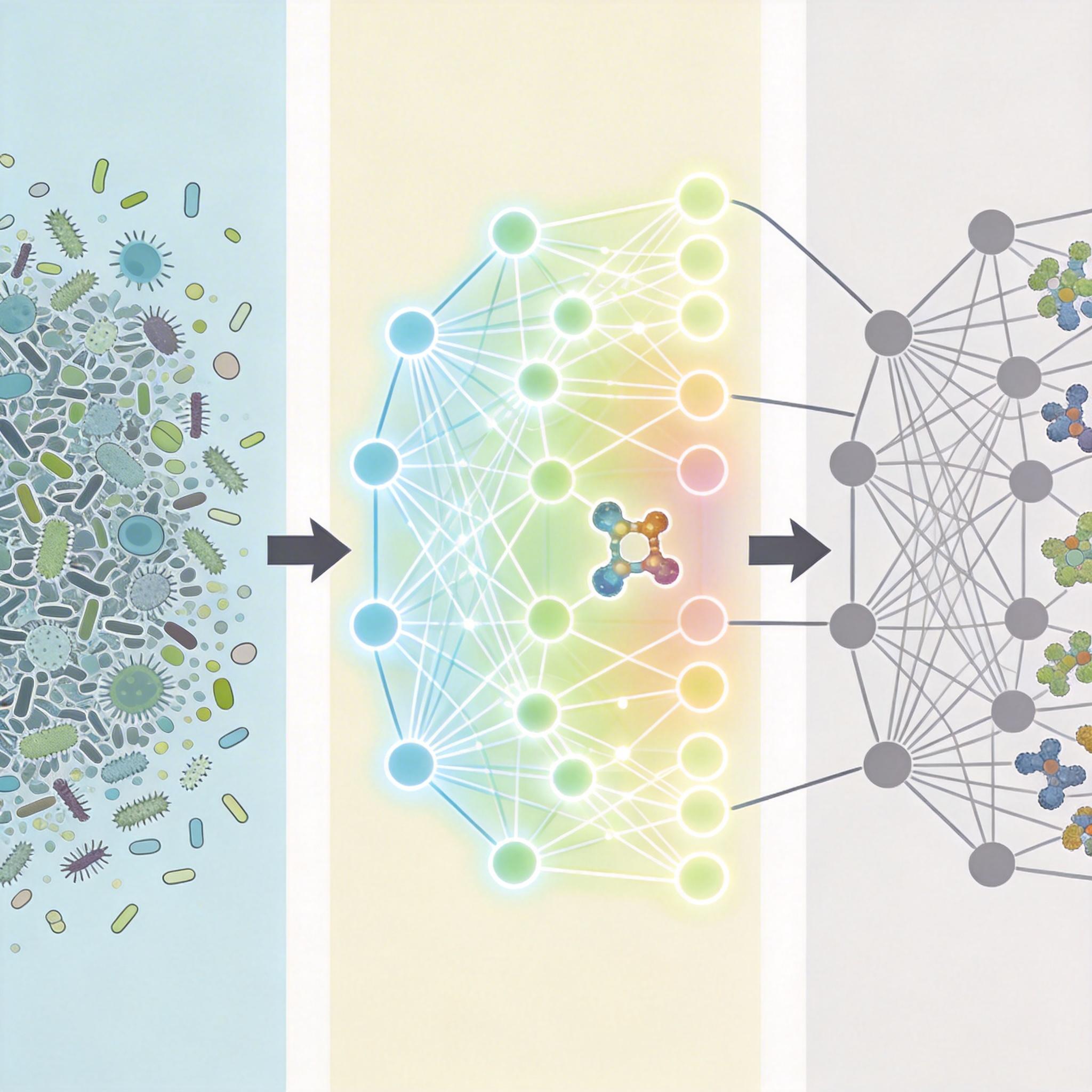
举个简单的类比:就像一个见过很多肺癌X光片的医生,突然拿到一张肺炎的片子,也能快速发现肺部的异常区域——不是因为两种病完全一样,而是医生已经学会了识别“肺部病变”的共性特征。AI模型在这里做的是同样的事:它不会纠结于“这是胃癌还是肠癌”,而是先学会识别“肠道生态异常”的普遍模式,再用这种模式去匹配不同疾病的特征。
研究中用到的XGBoost和随机森林模型,能从数千个微生物和代谢物指标里,筛选出最具诊断价值的特征。比如针对炎症性肠病,模型最终锁定了Lachnospiraceae家族细菌和甘油酸代谢物;而胃癌的核心特征,则集中在二氢尿嘧啶和厚壁菌门的变化上。更关键的是,这些模型的准确率相当可观:用结直肠癌数据训练的模型,识别胃癌的准确率能达到80%以上。
当然,这项研究也有局限。目前的模型还只在小样本队列中验证过,不同人群的饮食、生活习惯差异,可能会影响模型的泛化能力。而且,这些共享信号背后的具体机制,比如为什么牛磺酸代谢异常会同时关联胃癌和炎症性肠病,还需要更深入的基础研究来解释。
现在的胃肠病诊断,大多依赖内镜、活检这些侵入性手段。以胃癌为例,胃镜的准确率虽高,但早期胃癌的漏诊率仍能达到10%左右,而且很多人因为恐惧检查,拖到出现明显症状才就医——此时往往已经到了中晚期。
肠道微生物和代谢物检测的最大优势,就是非侵入性:只要一份粪便或血液样本,就能完成检测。伯明翰团队的研究,让这种检测的价值又上了一个台阶——它不仅能诊断单一疾病,还能同时提示多种疾病的风险。比如一个被检测出牛磺酸代谢异常的人,医生不仅会排查他的胃癌风险,还会关注他是否有炎症性肠病的潜在可能。
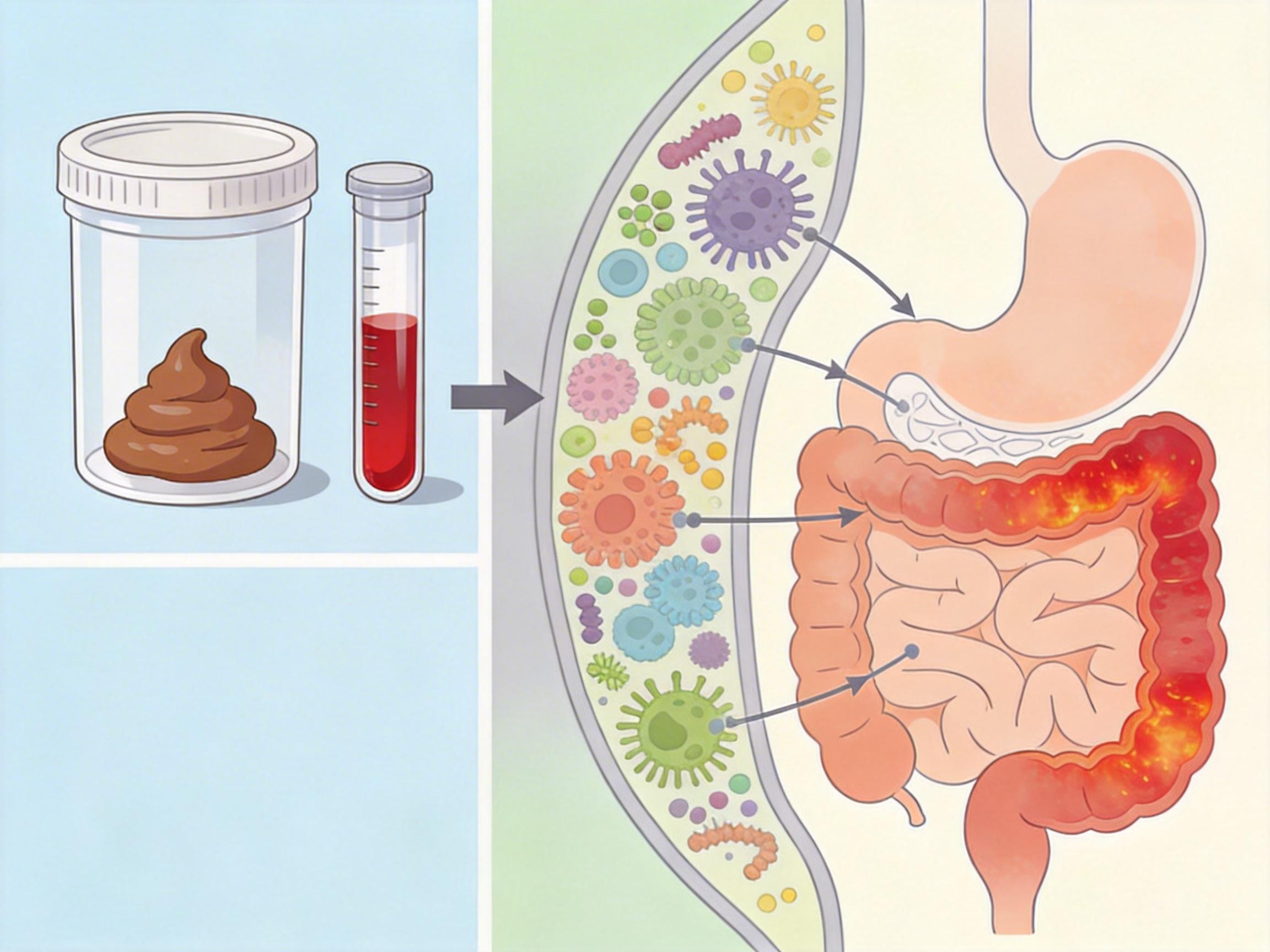
目前,已经有一些基于肠道微生物的检测产品进入临床,比如结直肠癌的粪便微生物筛查,准确率已经接近肠镜。但这些产品大多只针对单一疾病,伯明翰团队的研究,为开发“一管样本查多病”的通用检测工具奠定了基础。未来,这种检测可能会像血常规一样普及,成为胃肠病早期筛查的常规手段。
不过,要实现这一步还有不少障碍。首先是标准化问题:不同实验室的样本处理、测序方法不同,可能会导致结果差异;其次是成本,目前的宏基因组测序价格还比较高,难以大规模推广;最后是临床认知,医生需要时间来理解和接受这些“看不见摸不着”的微生物标志物。
我们总把肠道当成一个“消化器官”,却忽略了它是人体最大的微生物栖息地,也是一个隐藏的“健康传感器”。伯明翰团队的研究,不仅给胃肠病的早期诊断带来了新希望,更让我们重新认识到:人体的疾病从来不是孤立的,它们像一张大网,通过肠道微生物这样的“节点”相互关联。
肠道藏着疾病的共性密码,这或许是这项研究最有价值的启示——未来的医学,可能不再是“头痛医头脚痛医脚”,而是通过解码这些共性信号,实现更早的预警、更精准的干预。而我们每个人的肠道里,都藏着属于自己的健康答案,等待着被读懂。
点击催更,成为大圆镜下一个视频选题!