对抗知识焦虑,从看懂这条开始
App 下载
代码的炼金术:编译器如何看穿万象,化繁为简
循环消除|Matt Godbolt|机器指令|编译器优化|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载循环消除|Matt Godbolt|机器指令|编译器优化|软件工程|前沿科技
想象一个场景:一位程序员正在调试一段看似复杂的循环代码,他屏息凝神,准备逐行追踪变量的变化。然而,当他按下“下一步”时,整个循环竟瞬间“蒸发”,在底层直接化为一条简单的机器指令。代码去哪了?这并非魔术,而是现代软件工程中最伟大的“炼金术”之一——编译器优化。
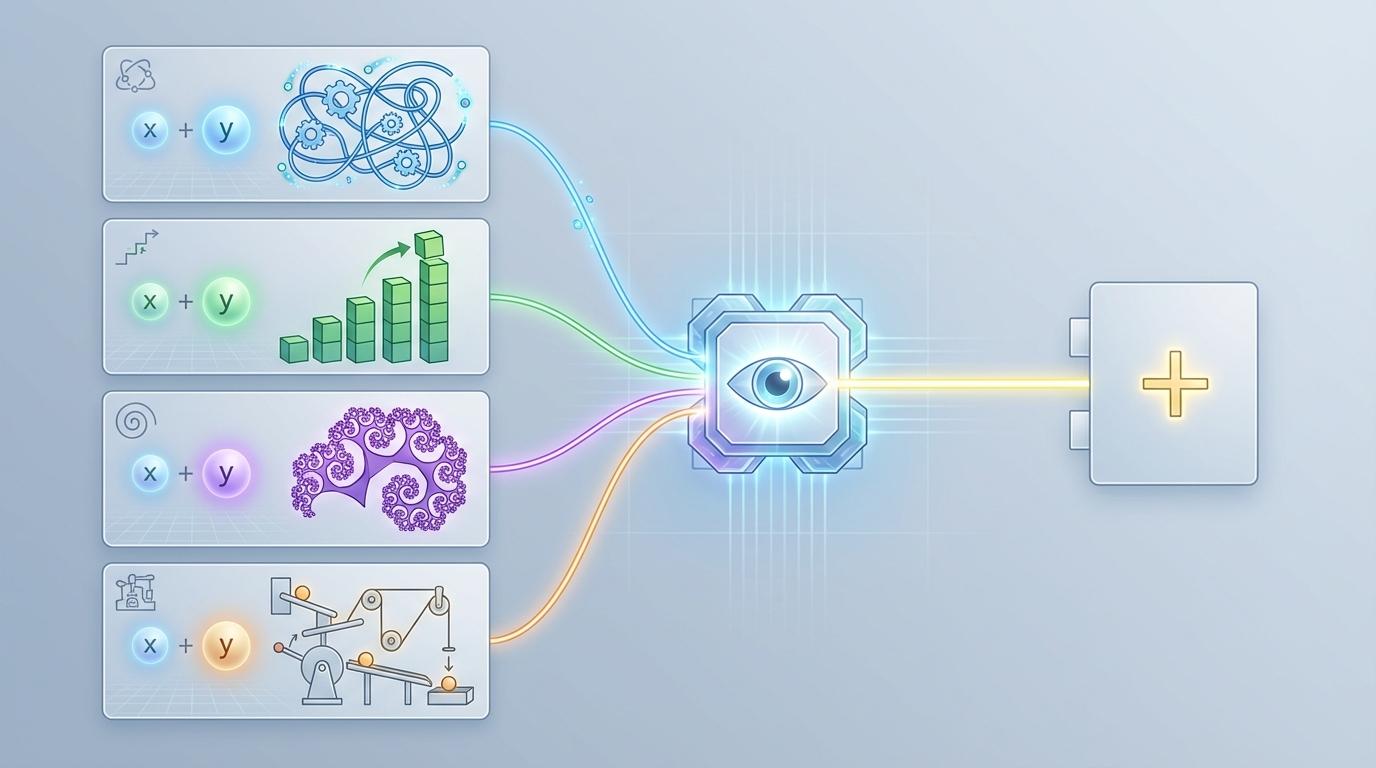
最近,一则由编译器专家Matt Godbolt分享的趣闻揭示了这一现象的冰山一角。他展示了四种截然不同的代码实现,包括循环、递增,甚至是看似会无限递归的函数,它们的目标都仅仅是计算x + y。尽管这些代码在人类眼中千差万别、晦涩难懂,但编译器却像一位洞悉本质的智者,看穿了所有伪装,最终将它们全部编译成了同一条、也是最高效的汇编指令:add。这引出了一个核心问题:编译器是如何拥有这种“慧眼”,识别出万千变化代码背后那个不变的数学本质的?
编译器并非拥有一本记录了“一万种愚蠢加法写法”的秘籍。它的超能力源于一个核心机制:模式识别与中间表示(Intermediate Representation, IR)。
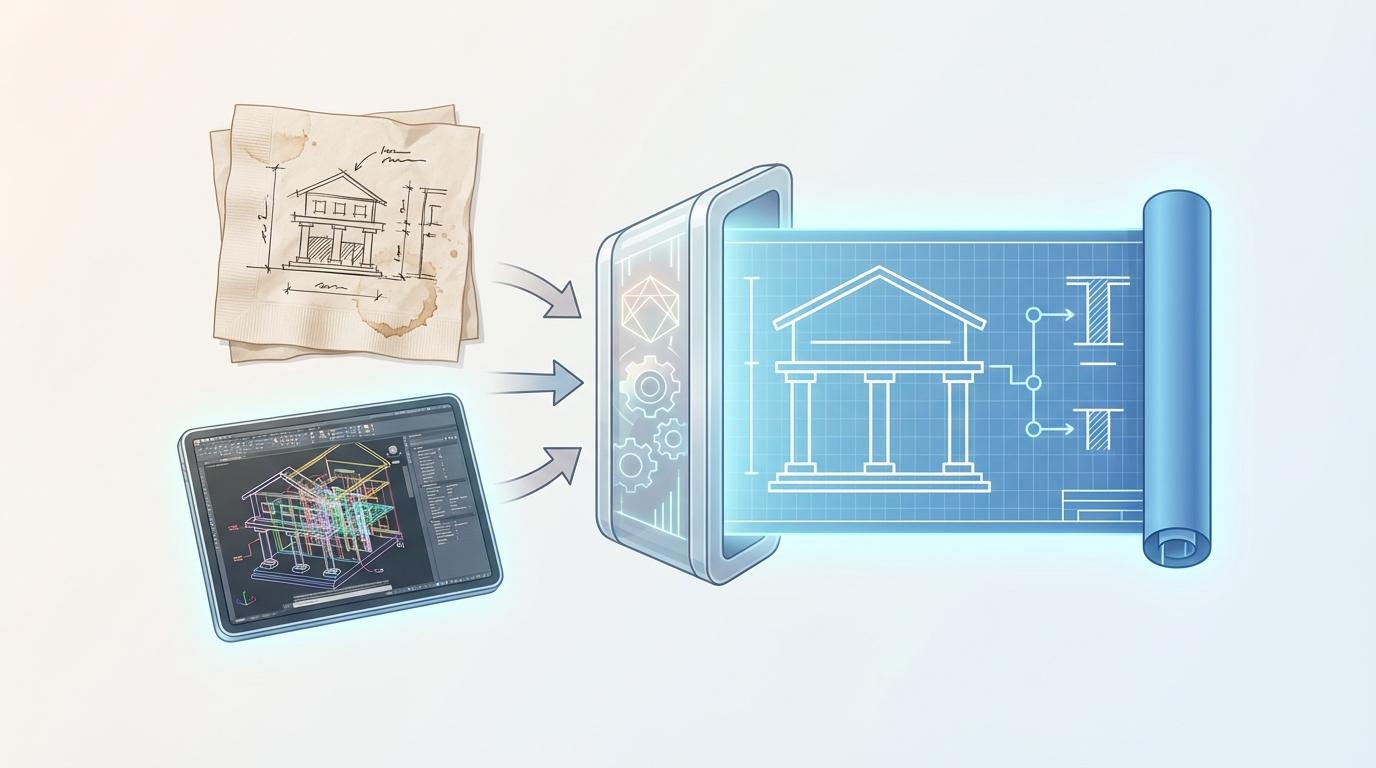
当编译器接收到我们编写的源代码时,它做的第一件事不是直接翻译成机器码,而是将其转换成一种更为抽象、纯粹的内部语言——中间表示(IR)。你可以将IR想象成一张建筑蓝图。无论最初的设计草图是画在餐巾纸上,还是用复杂的CAD软件绘制,最终都会被转化为一张标准化的、只包含核心结构与逻辑的工程蓝图。对于编译器而言,IR就是这张蓝图。
在这个IR世界里,所有语言层面的“语法糖”和程序员的“个人风格”都被剥离,只剩下最核心的计算逻辑。那段复杂的while循环,在IR中可能被转换为“将Y增加X次,然后返回Y”的逻辑。紧接着,编译器的优化模块会分析这个IR,并识别出其数学等价形式——“返回X+Y”。这个过程,就是规范化(Canonicalization)。
通过这套流程,无论代码最初是循环、递归还是简单的+号,在IR层面都会被“打回原形”,统一成最简洁的规范形态。到了最终生成机器码的阶段,在优化器眼中,这四段风格迥异的代码早已变得别无二致。这套基于IR的模式识别和规范化流程异常强大,甚至能优化那些你永远不会故意去写的、逻辑混乱的代码。
编译器的这套“内功心法”也在不断进化。早期的编译器,其IR是封闭在内部的“独门秘籍”。但随着开源运动的兴起,特别是LLVM项目的出现,IR开始走向开放和模块化。LLVM IR像一种“通用语”,让不同的编程语言(前端)和不同的硬件(后端)可以顺畅沟通,极大地促进了编译技术生态的繁荣。
如今,随着AI和异构计算(CPU、GPU、AI芯片并存)时代的到来,对编译器的要求更高。为此,**MLIR(Multi-Level Intermediate Representation)**应运而生。它不再是单一的IR,而是一个可以构建“编译器的编译器”的框架,允许在不同抽象层次上定义“方言”(Dialect),让从高级AI模型到底层硬件指令的转换和优化变得前所未有的灵活。IR的演进,正从一个封闭的内部工具,走向一个构建未来软件与硬件桥梁的统一生态系统。
编译器的强大优化能力极大地解放了程序员。开发者可以专注于编写意图清晰、可读性高的代码,将性能优化的重任放心地交给编译器。这是一种人与机器的高效协作,让人类专注于创造性思维,机器负责极致的效率执行。
然而,这把锋利的“优化之刃”也有其另一面。首先,高度优化的代码往往会成为调试的噩梦。因为最终执行的机器码与你编写的源代码在结构和顺序上可能大相径庭,这使得追踪程序错误变得异常困难。其次,编译器优化基于一个严格的假设:你的代码中不存在“未定义行为”(Undefined Behavior, UB)。例如,有符号整数溢出在C++中就是一种UB。编译器会假设它永远不会发生,并基于此进行激进的优化,这可能导致在特定条件下,看似正常的代码会产生完全意想不到的错误结果。这就像与一位聪明但毫无变通余地的“魔鬼”签订的契约,你必须严格遵守规则,否则就会被其无情的逻辑反噬。
在代码从人类智慧转化为机器动力的漫长旅程中,编译器扮演着沉默而关键的英雄角色。它不仅是翻译官,更是炼金术士,通过中间表示这块“贤者之石”,洞悉千变万化的代码表象,提炼出计算的纯粹本质,并将其锻造为高效的机器指令。理解编译器的“读心术”,不仅让我们惊叹于计算机科学的精妙,也让我们更深刻地认识到,在软件世界中,优雅的表达与极致的效率,最终可以殊途同归。