对抗知识焦虑,从看懂这条开始
App 下载
AI读懂跨物种大脑语言,揭秘集体编码密码
大脑语法规则|跨物种神经数据|猕猴决策信号|小鼠视觉皮层|神经基础模型|神经生物学|大语言模型|生命科学|人工智能
对抗知识焦虑,从看懂这条开始
App 下载大脑语法规则|跨物种神经数据|猕猴决策信号|小鼠视觉皮层|神经基础模型|神经生物学|大语言模型|生命科学|人工智能
当一只小鼠在迷宫里找路,一只猕猴盯着屏幕做决策,你或许会觉得它们的大脑各有一套专属密码。但2025年的两项研究打破了这个直觉:科学家用神经基础模型——一种像ChatGPT读遍文本那样「读」过百万级神经元数据的AI——不仅精准预测了小鼠视觉皮层的神经活动,还能把猕猴的决策信号「翻译」成人类大脑的相似模式。更惊人的是,这个模型只需要新物种1/5的数据,就能快速适配。这意味着不同物种的大脑,可能共享着一套通用的「语法规则」。我们到底是怎么破解这套规则的?
过去我们总以为,大脑里有专门管「决策」的神经元,有负责「运动」的细胞——就像工厂里各司其职的工人。但近十年的神经科学研究推翻了这个假设:当猕猴判断两个刺激的先后顺序时,前额叶皮层里没有专门的「时间神经元」,而是所有神经元一起形成两组集体活动模式,一组标记「是什么刺激」,另一组标记「什么时候出现」;小鼠准备移动时,运动皮层里也没有「准备神经元」和「执行神经元」的分工,所有细胞都参与到同一段「神经交响乐」里。
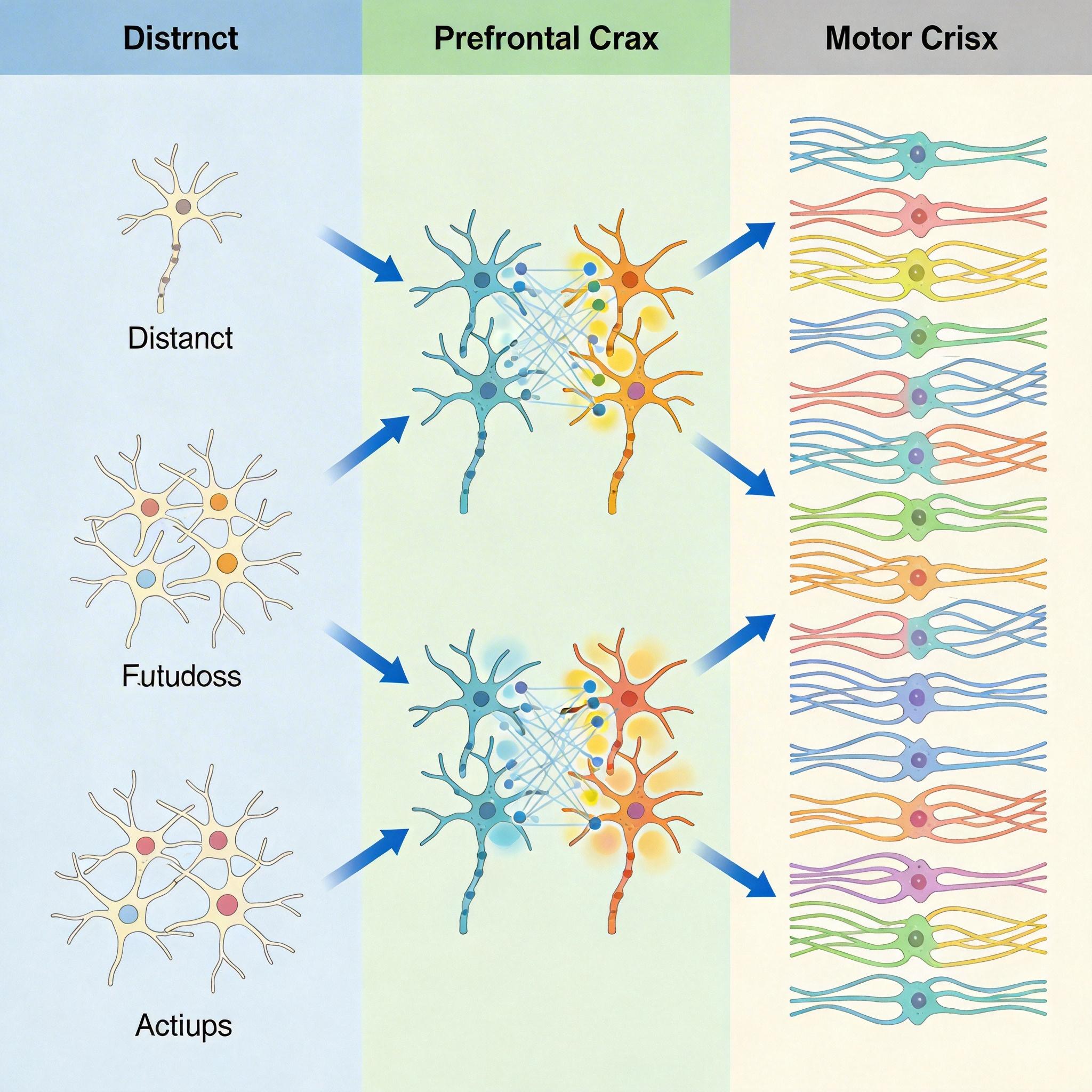
你可以把单个神经元想象成交响乐团里的乐手:单听小提琴手的演奏,你不知道整个乐团在演贝多芬还是莫扎特,但把所有乐手的声音合在一起,旋律和情绪就清晰了。神经基础模型做的,就是从百万条「单乐手录音」里,找出所有乐团通用的乐谱规则。
比如哥伦比亚大学2025年的研究,用微型显微镜同步记录了小鼠海马体数百个神经元的活动,发现集体活动模式比单个「位置细胞」更能准确反映小鼠的位置和行为——就像看整个乐团的指挥手势,比听单把大提琴更能知道乐曲的走向。
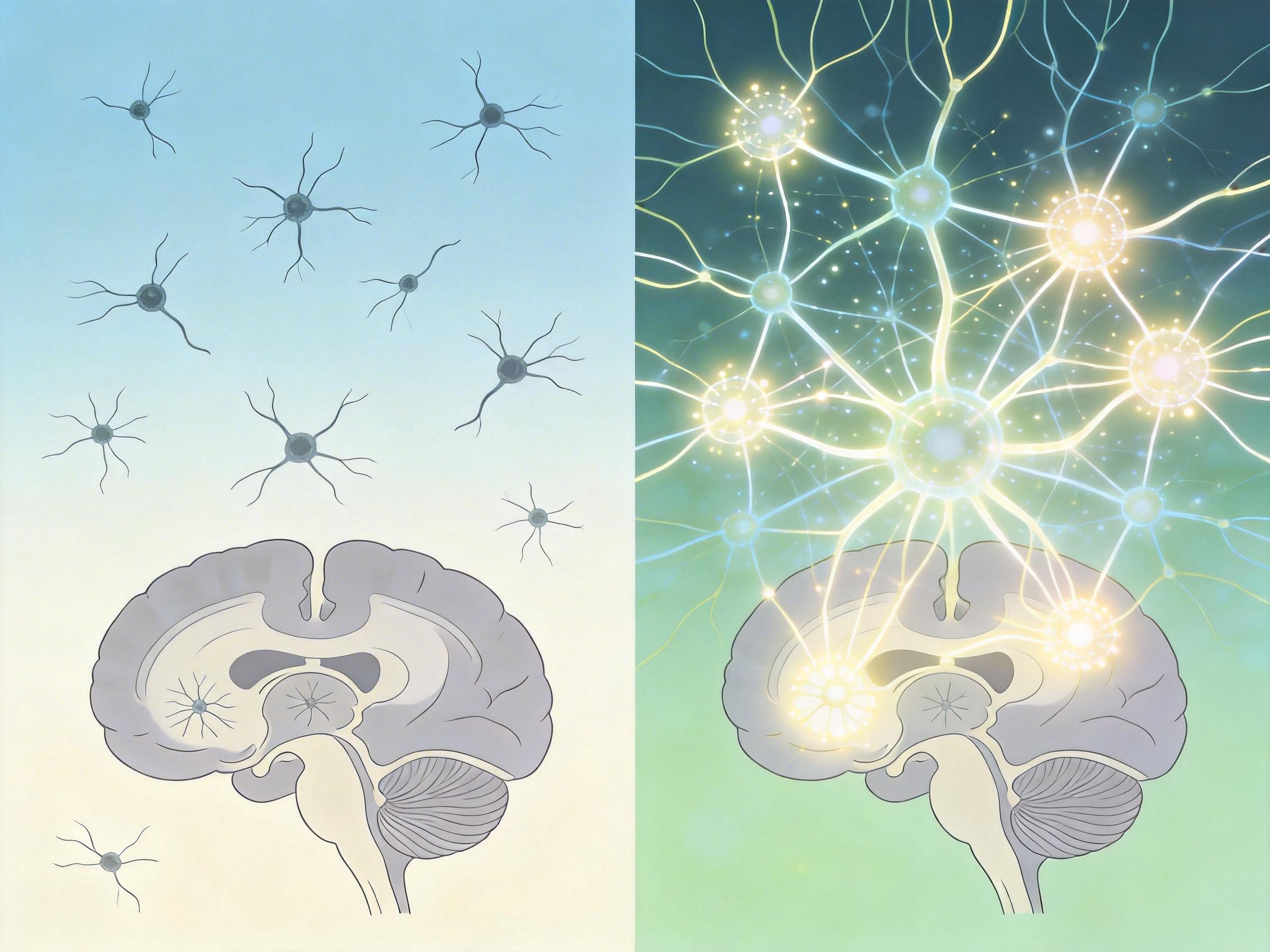
神经基础模型的神奇之处,在于它能跨物种「泛化」——就像ChatGPT学会了中文语法,就能看懂不同作者的文章。2025年Wang团队的模型,用14只小鼠的13.5万神经元数据训练后,不仅把神经活动预测准确率提升了近50%,还能准确判断神经元的解剖类型、树突形状,甚至神经连接方式。更关键的是,当给它新小鼠的数据时,只需要微调少量参数,就能达到和专门训练的模型一样的精度。
这种跨物种的适配能力,背后是大脑的「保守性」:从小鼠到人类,海马体的位置细胞都用相似的模式编码空间信息;大脑皮层的浅层都产生处理感知的伽马波,深层都产生调控信息的阿尔法波。就像不同的语言都有主谓宾的基本结构,不同物种的大脑也共享着神经活动的「字符」和「语法」。
Zhang团队2025年的BrainBeacon模型更夸张:它用人类、猕猴、绒猴和小鼠的1.33亿个单细胞数据训练,能直接把小鼠的脑细胞类型「翻译」成人类的对应细胞,甚至能模拟基因敲除对不同物种细胞的影响——相当于用一套通用词典,读懂了四种不同语言的医学论文。
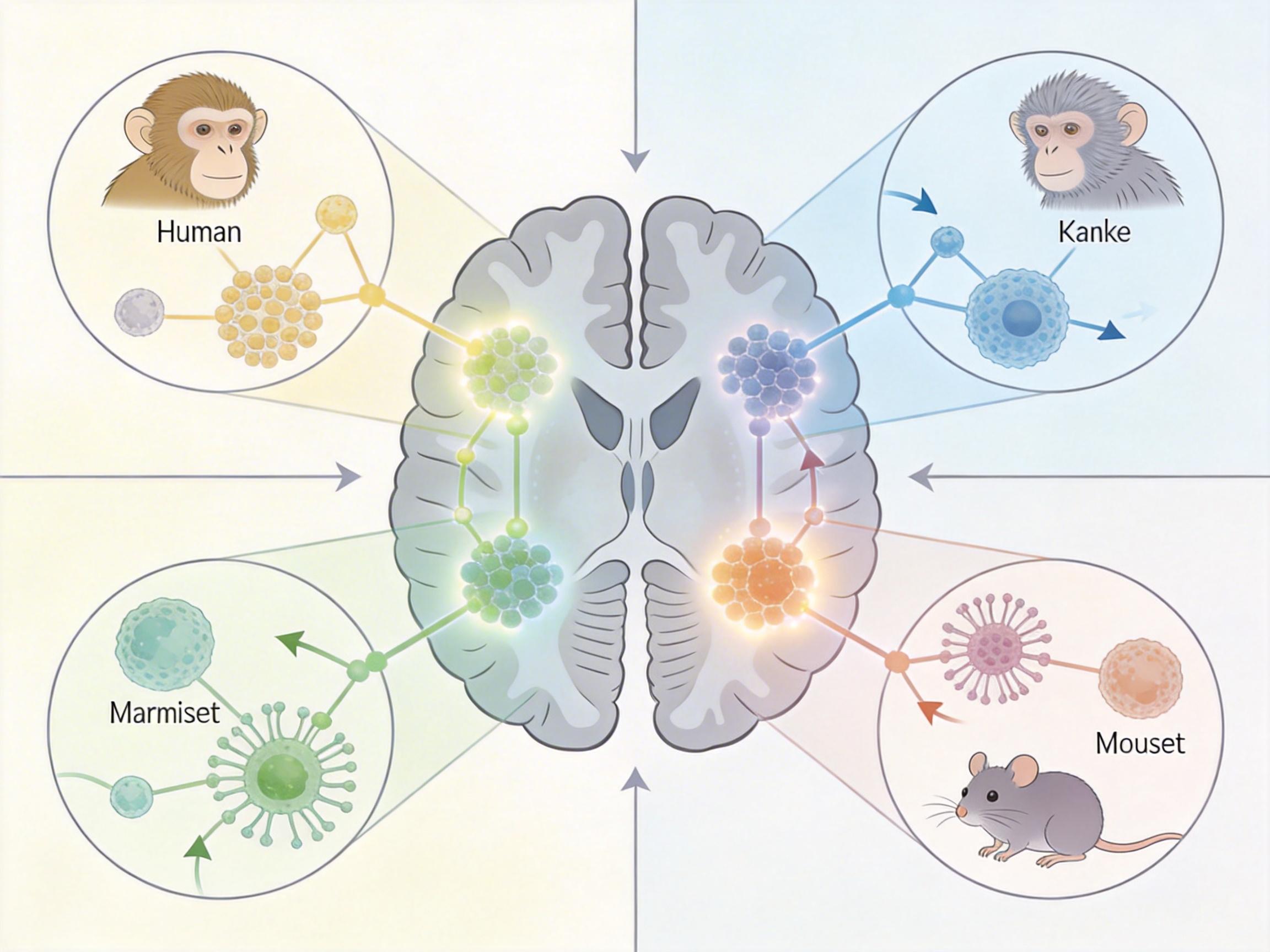
但神经基础模型不是完美的。它最大的问题,是「黑盒」属性:模型能准确预测神经活动,但我们不知道它到底抓住了哪条「语法规则」。就像ChatGPT能写出通顺的句子,但你问它为什么用这个词,它只能给你一堆模糊的解释。
比如现在的模型能预测帕金森病患者的大脑异常活动,但我们不知道它是通过检测beta波的振幅,还是通过更复杂的集体模式判断的。这种不可解释性,让它很难直接转化为临床治疗方案——你总不能让医生照着AI的提示,随便给患者做神经刺激。
还有数据的问题:训练一个神经基础模型需要百万级的神经元数据,而现在我们能记录的神经元数量,还不到人类大脑的亿分之一。就像你只读了一页书,就想总结出整个语言的语法,难免会有偏差。更不用说不同物种的大脑大小差异巨大——人类大脑有860亿神经元,小鼠只有7500万,模型能不能真正跨越这种量级的鸿沟,还是个未知数。
当我们用AI破解大脑的通用语法时,其实也是在重新理解「智能」本身:不管是小鼠的迷宫导航,还是人类的哲学思考,本质上都是神经元集体活动的产物。就像所有的文学作品都逃不开26个字母的组合,所有的大脑活动,或许也逃不开那套共享的神经规则。
「大脑的秘密,藏在集体的韵律里。」未来的神经科学,或许不再是寻找单个神经元的英雄,而是倾听整个大脑的交响乐——而AI,就是我们的首席指挥家。