对抗知识焦虑,从看懂这条开始
App 下载
AI写代码快3倍,半年后团队反而变慢了
静态分析警告|代码复杂度|开源项目|AI编码工具|Cursor|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载静态分析警告|代码复杂度|开源项目|AI编码工具|Cursor|AI产业应用|人工智能
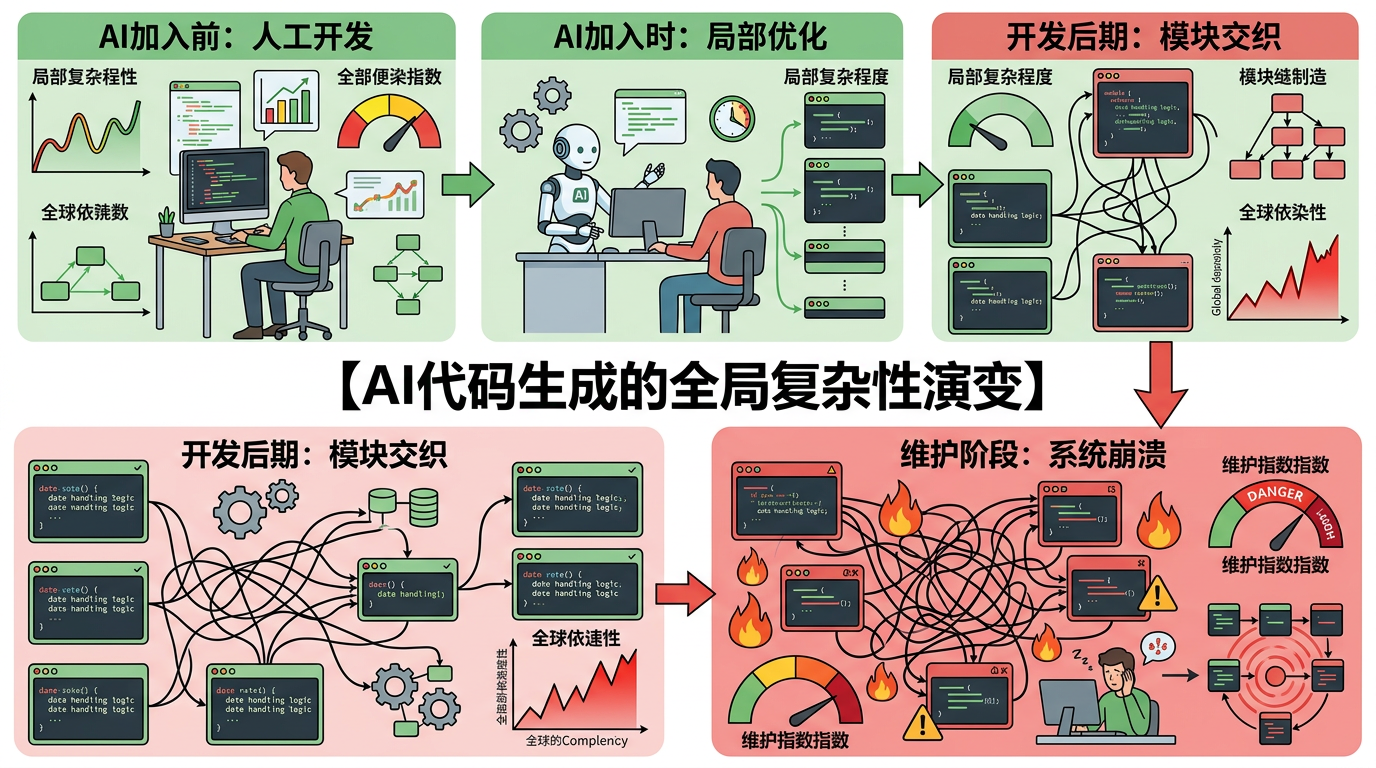
2024年初,一批开源项目兴冲冲用上了AI编码工具Cursor,首月新增代码行数直接翻了3倍,PR合并数暴涨39%——整个团队像按下了加速键。开发者们甚至开始畅想:以后写代码是不是只要动动嘴就行?但没人料到,仅仅三个月后,这些项目的开发速度就悄悄回落到了之前的水平。更糟的是,代码里的静态分析警告多了30%,复杂度飙升40%,每次改个小功能都要牵一发而动全身。为什么AI给的短期红利,最终变成了长期的技术包袱?
你可以把AI生成代码比作新手厨师炒菜:照着菜谱炒出来的菜样子不差,但调料比例全凭感觉,锅气火候更是无从谈起——单看一盘菜没问题,凑成一桌宴席就会发现口味混乱、搭配冲突。

但真实的机制比这更精确:AI是基于训练数据里的高频片段拼接代码,它能快速完成局部功能,却没能力理解整个项目的架构逻辑。比如为了实现一个小功能,它可能会复制一段相似的校验逻辑,而不是调用项目里已有的公共方法;为了兼容某个边缘场景,它会悄悄加一层嵌套判断,而不是重构现有分支。
这些问题在代码提交时很难被发现,却会像滚雪球一样积累:
到了2025年中,那些最早用Cursor的项目里,有67%的开发者花在调试AI代码上的时间,已经超过了AI帮他们节省的编码时间。
一直以来,我们用圈复杂度、Halstead指标这些传统工具衡量代码质量——就像用体重秤判断一个人的健康,只能测个大概,看不出内脏的真实状态。
当AI加入后,这些工具彻底失效了:AI生成的代码局部圈复杂度往往很低,单看一个函数甚至比人工写的更规范,但把整个项目串起来看,就会发现模块间的依赖像乱麻一样。比如一个电商项目里,AI在订单模块、支付模块、库存模块各自写了一套相似的日期处理逻辑,每个模块的圈复杂度都合格,但整个项目的维护指数直接降到了危险线以下。
这逼得研究者不得不重新定义「代码复杂度」——2025年底,MIT团队提出了LM-CC指标,专门从AI的视角衡量代码难度:它不看单个函数的分支数,而是看跨模块的语义嵌套、重复逻辑的熵值,以及AI生成时的概率发散程度。实验显示,只要把LM-CC指标降低20%,AI生成代码的正确率就能提升20%以上。
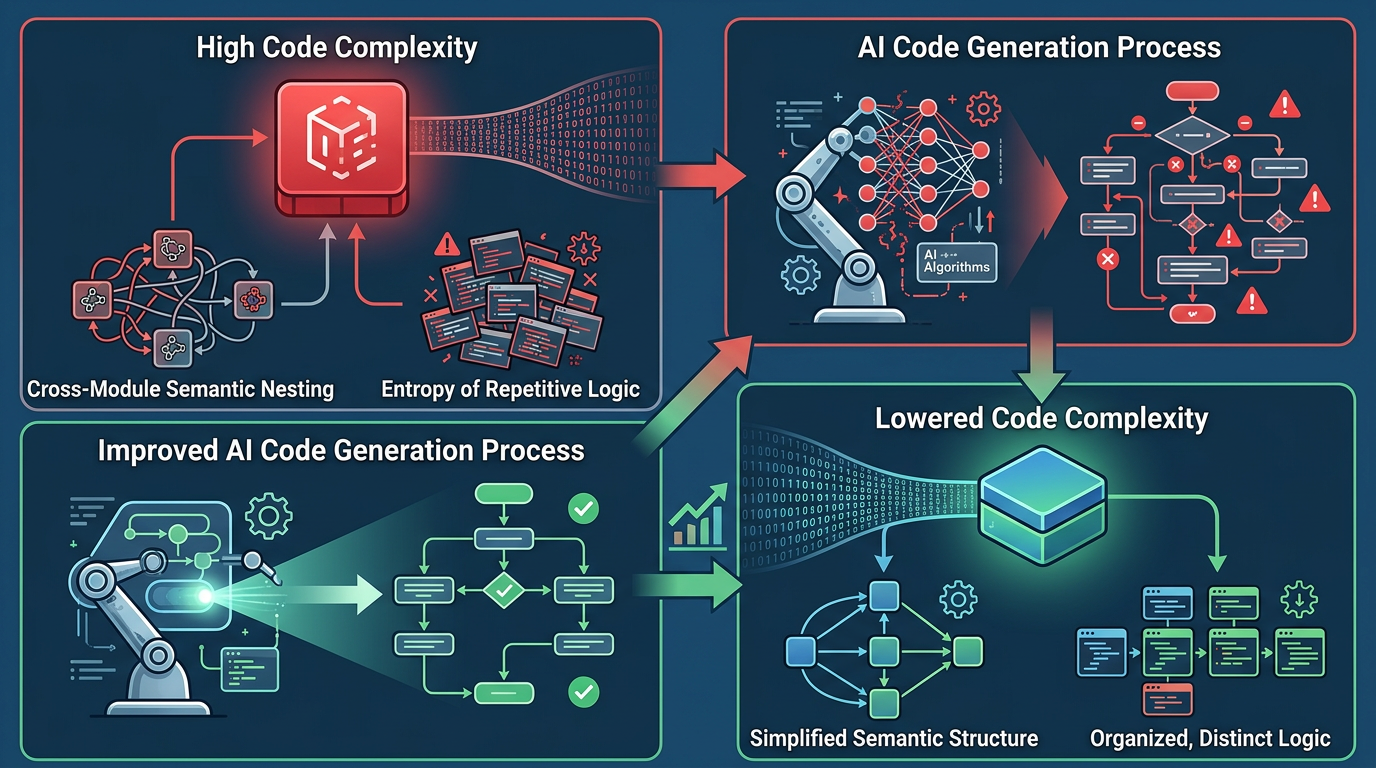
有意思的是,这个指标反过来也能帮人类开发者:当你用LM-CC扫描代码库,那些AI容易「踩坑」的地方,恰恰也是未来人类维护时的难点。
现在开发者的工作流程已经彻底变了:以前是「想清楚→写代码→测一遍」,现在是「拆任务→调AI→查漏洞→再调AI→最终审核」。AI成了代码的「初稿生成器」,而人类则要扮演「审稿人+架构师」的双重角色。
这对开发者的能力要求完全不同了:
2025年的一项随机对照试验显示,那些能高效用AI的团队,都有一个共同特点:他们会给AI设定「规则文件」,比如禁止重复造轮子、必须调用公共组件、异常处理要统一风格——就像给新手厨师制定厨房规矩,从源头减少混乱。
说句实在话,现在的AI还只是个「聪明的实习生」,能帮你干脏活累活,但拍板的还得是你。
当我们为AI带来的速度狂欢时,很容易忘记软件开发的本质:它从来不是比谁写得快,而是比谁能在复杂系统里持续交付价值。那些被AI放大的技术债务,那些传统工具看不到的架构混乱,其实都是我们对「效率」的误解——我们只看到了代码的数量,没看到代码的「质量密度」。
快是结果,稳才是前提。
未来的软件开发,会是一场人机之间的「平衡游戏」:AI负责解决「快」的问题,人类负责守住「稳」的底线。而真正的高手,会懂得在加速的同时,给系统装上「刹车」——毕竟,能走得远的团队,从来不是跑得最快的那个,而是不会在半路上翻车的那个。