对抗知识焦虑,从看懂这条开始
App 下载
只读19世纪书的AI,暴露了大模型的隐秘软肋
AI训练数据|无版权数据|维多利亚时代书籍|Trip Venturella|Mr. Chatterbox|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI训练数据|无版权数据|维多利亚时代书籍|Trip Venturella|Mr. Chatterbox|大语言模型|人工智能
2026年3月,一款叫Mr. Chatterbox的AI悄悄上线——它的脑子里装着28035本维多利亚时代的旧书,从狄更斯的小说到19世纪的科学论文,却对1900年以后的世界一无所知。你问它“什么是互联网”,它会用优雅的维多利亚腔给你扯一通“电报的奇迹”;你让它推荐电影,它能给你列出一长串1890年代的舞台剧清单。
但更有意思的是它的对话质感:与其说像个AI,不如说像个装在旧书堆里的鹦鹉——句子华丽得像戴了蕾丝手套,却永远答非所问。开发者Trip Venturella花了两年才攒出这个模型,而它的表现,恰恰戳中了当下AI圈最不愿直面的问题:当我们把“无版权数据”作为底线,大模型到底能走多远?
要理解Mr. Chatterbox的“笨拙”,得先搞懂AI训练里的一个核心公式:参数和数据的黄金比例。2022年DeepMind的Chinchilla论文给出过一个基准:要让模型达到最优性能,训练数据的token数应该是参数数量的20倍。
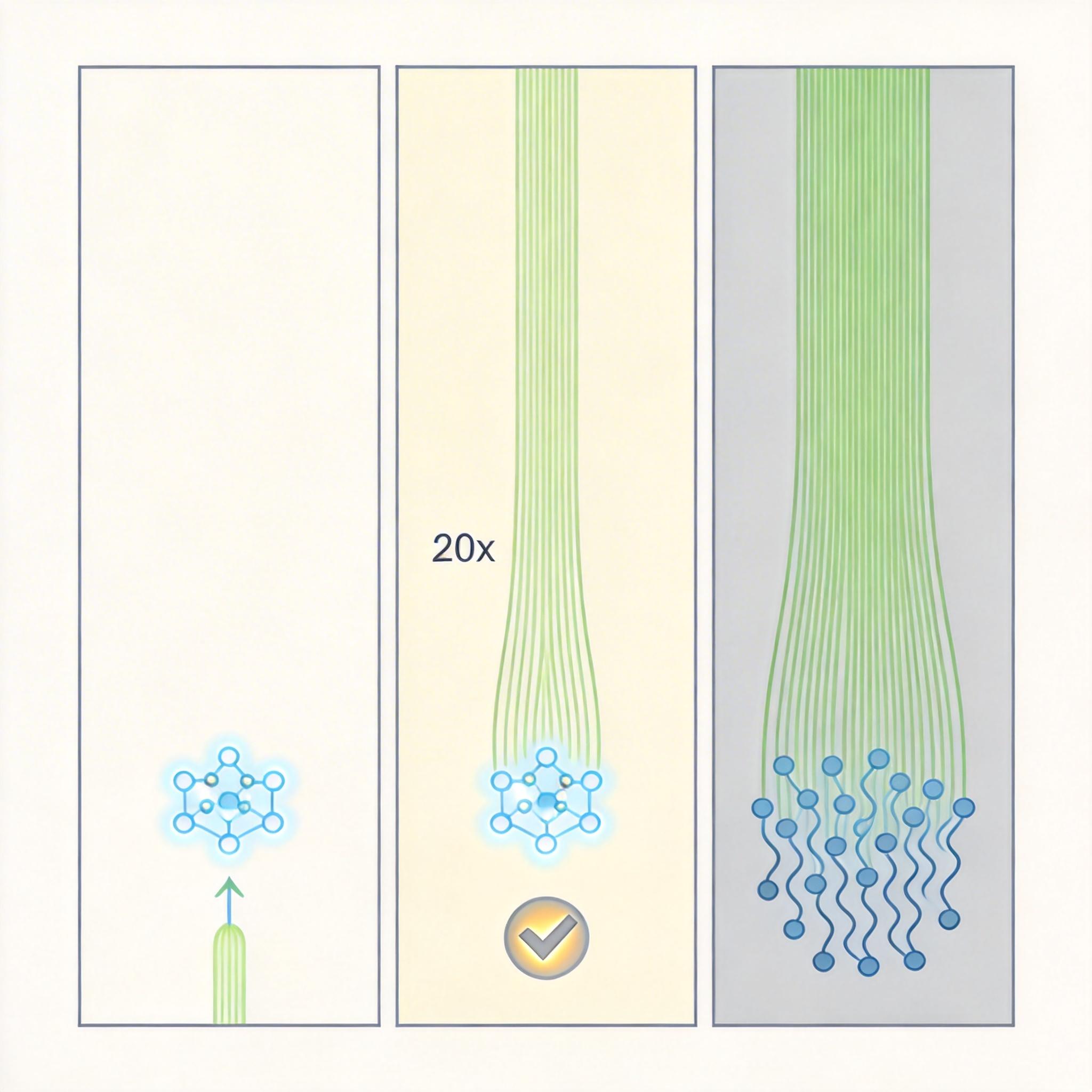
你可以把AI模型想象成一个空书架,参数是书架的格子数,训练数据就是要放进去的书。Mr. Chatterbox有3.4亿个“格子”,按照20倍的比例,它需要至少70亿个token的“书”才能填满。但实际上,它只塞进了29.3亿个token——相当于一个能放100本书的书架,只摆了40本,剩下的格子全是空的。
这直接导致了它的“马尔可夫链感”:它能记住句子的语法和维多利亚时代的用词习惯,却无法理解上下文的逻辑。你问它“如何制作咖啡”,它可能会给你背诵一段1880年代关于“烘焙咖啡豆的艺术”的散文,但绝不会提到“速溶咖啡”或者“咖啡机”。

更关键的是,它的训练数据全是19世纪的公共领域文本——没有20世纪的科技进步,没有现代的社会观念,甚至连“电话”这个词都属于它认知的边缘地带。它不是不想好好聊天,而是它的“知识库”里,根本没有现代问题的答案。
Mr. Chatterbox的诞生,其实是对当下AI圈版权焦虑的一次回应。过去几年,OpenAI、Anthropic等公司因为训练数据的版权问题陷入多起诉讼——他们爬取了互联网上几乎所有能找到的文本,从新闻报道到小说,从博客到学术论文,却很少获得创作者的授权。
而公共领域数据则是完全的“法外之地”:所有1928年以前出版的作品,版权都已过期,任何人都可以免费使用。这也是Trip Venturella坚持只用维多利亚时代文本的原因——他想证明,不用偷爬数据,也能训练出一个AI模型。
但这条路的困难,比想象中要多得多。首先是数据规模的限制:全球所有公共领域的英文书籍加起来,大概也只有不到1000亿个token,而GPT-3的训练数据是1.4万亿个token——相当于前者的14倍。其次是数据质量的问题:公共领域的旧书里充满了过时的知识和偏见,比如对女性、少数族裔的刻板印象,这些都会被原封不动地“学”进AI模型里。
2024年MIT和多伦多大学的团队曾做过一个实验:用8TB的公共领域数据训练了一个70亿参数的模型,性能接近Meta的Llama 2-7B,但他们花了两年时间才完成数据的筛选和清洗——光是甄别版权状态,就动用了20多名研究人员。这意味着,公共领域数据的“免费”,其实是用极高的时间成本换来的。
尽管Mr. Chatterbox的聊天体验糟糕透顶,但它却意外打开了AI的另一个应用场景:数字人文研究。
苏黎世大学的研究团队曾用类似的“历史AI”分析19世纪的报纸,发现了当时社会对“女性就业”的态度变化——通过统计“女工”“家庭主妇”等词汇的出现频率,他们还原了工业化对女性社会角色的影响。而传统的历史研究,需要研究人员翻阅数万份报纸,耗时数年才能完成。

还有的团队用历史AI模拟古罗马人的对话模式,通过分析拉丁文文本中的语法和用词,推测当时的社会阶层结构。甚至有考古学家用AI解读古埃及的象形文字,把原本需要几个月的破译时间缩短到了几天。
这些应用的核心,恰恰是Mr. Chatterbox的“缺点”:它的认知被严格限制在特定的历史时期,不会被现代知识干扰。对于历史研究来说,这种“时间锁定”的AI,比能回答所有问题的通用AI更有用——它就像一个活的“时间胶囊”,能帮我们重新理解过去的世界。
当然,这种“专用AI”也有它的局限:它无法处理超出训练数据范围的问题,也无法理解现代的社会语境。但它至少证明了,AI不一定非要追求“无所不能”,有时候“专注于某一件事”,反而能创造更大的价值。
当我们谈论AI的未来时,总习惯把“更大的模型”“更多的数据”当成唯一的方向。但Mr. Chatterbox的出现,像一面镜子,照出了这种思路的盲区:我们真的需要一个能回答所有问题的AI吗?还是说,我们需要的是一群能在各自领域里做到极致的“专家AI”?
数据不是越多越好,知识也不是越新越好。有时候,把AI关在旧书堆里,反而能让它看到被我们遗忘的历史细节。
旧书堆里的AI,藏着另一种未来。