内容由AI生成,思考得你完成
App 下载
内容由AI生成,思考得你完成
App 下载想象一下:你写Java代码时,突然需要调用一个C语言写的高性能加密库——放在以前,你得先写一堆C语言的“胶水代码”,手动处理Java和C的类型转换、内存复制,稍有不慎就会让JVM直接崩溃,调试起来更是两头摸瞎。但现在,你只用几行纯Java代码,就能直接调用C函数,还不用担心里程碑式的内存泄漏。这不是科幻,是OpenJDK的Project Panama正在做的事——它把Java和本地代码之间那堵厚重的JNI墙,砸出了一扇宽敞的门。为什么Java要花这么大力气推倒旧墙?这背后藏着Java生态的一次关键转向。
JNI(Java Native Interface)从1997年的JDK1.1就存在了,它的作用是让Java能调用C/C++代码,但这套机制从诞生起就带着先天缺陷。你可以把JNI想象成一个需要手动搬运货物的码头:Java是河上的货船,C是岸边的仓库,你得先雇一批工人(手写C胶水代码),把货船上的箱子拆成仓库能认的规格,再一件件搬过去——不仅慢,工人还可能摔碎箱子(内存越界)、丢货(内存泄漏),甚至把码头给砸了(JVM崩溃)。
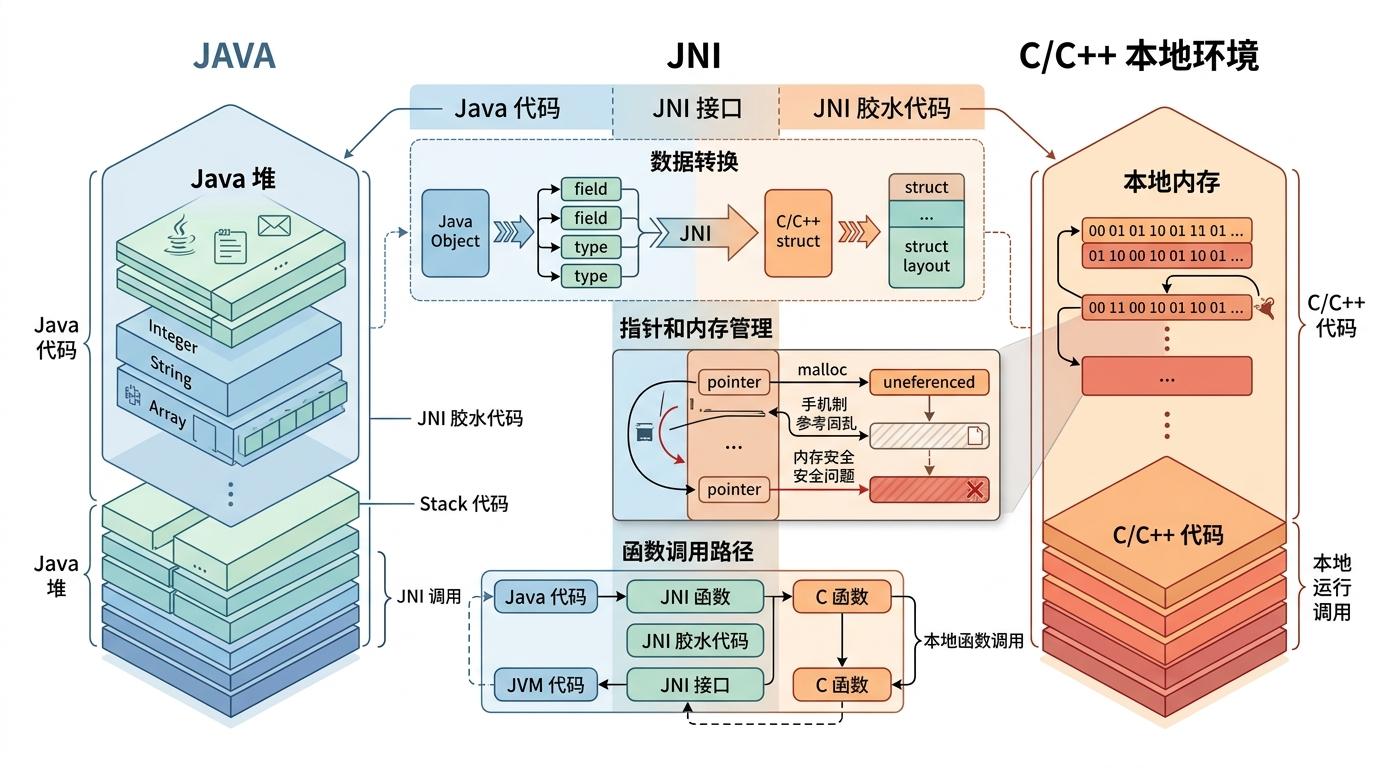
有开发者统计,用JNI实现一个简单的C函数调用,需要写至少3倍于业务代码的胶水层,而且调试时要在Java调试器和GDB之间来回切换,光是环境配置就能耗掉半天。更要命的是性能:JNI的调用无法被JIT编译器内联,每次跨语言调用都要付出额外开销,在频繁调用的场景下,这些开销甚至会抵消本地代码的性能优势。
最让人头疼的是安全。JNI的本地代码可以直接绕过Java的安全沙箱,随便修改Java对象的私有字段,甚至直接操作内存地址——就像给仓库大门配了一把万能钥匙,谁都能进去乱翻。曾经有Android恶意应用利用JNI的漏洞,耗尽系统的全局引用导致手机重启,就是最好的例子。
Project Panama的核心是一套叫FFM(Foreign Function & Memory)的API,它把JNI的“手动码头”改成了“自动化集装箱港口”。你不用再写C胶水代码,只用纯Java就能完成三件事:调用本地函数、访问本地内存、映射本地数据结构。
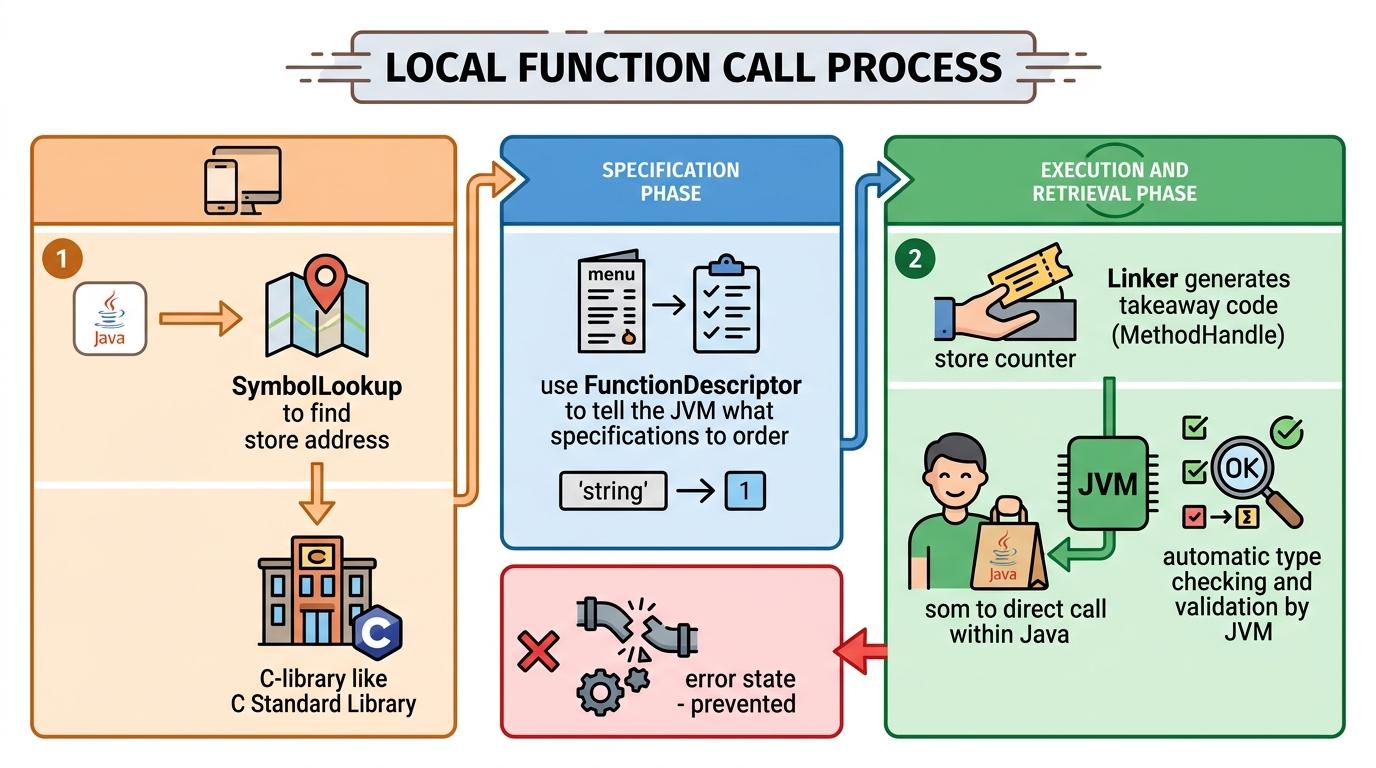
先看最核心的本地函数调用。你可以把FFM的调用流程想象成“叫外卖”:首先用SymbolLookup找到本地库的“店铺地址”,比如C标准库的strlen函数;然后用FunctionDescriptor告诉JVM“我要订的餐是什么规格”——比如输入一个字符串地址,返回一个长整数;最后通过Linker生成一个“取餐码”(MethodHandle),直接在Java里调用就行。整个过程没有一行C代码,JVM还会自动做类型检查,避免传错参数。
为了彻底消灭胶水代码,Panama还配套了一个叫jextract的工具——它就像一个自动翻译机,能直接把C语言的头文件转换成Java代码。比如你要调用一个叫libfoo的C库,只要运行jextract -t com.example.foo libfoo.h,它就能自动生成对应的Java接口,包括函数签名、结构体映射,甚至连枚举类型都能完美转换。有开发者测试,用jextract生成绑定代码的时间,比手写JNI快了至少10倍,而且出错率几乎为0。
再看内存管理。FFM用MemorySegment封装了本地内存,就像给每个集装箱都装了定位器和锁:你可以通过Arena机制设定内存的生命周期,比如用try-with-resources语法,代码块结束后自动释放内存,彻底避免内存泄漏;JVM还会自动做边界检查,如果你敢访问超出范围的内存,它会直接抛出异常,而不是让JVM崩溃。有测试显示,FFM的内存访问安全性比JNI高了90%以上,性能却和JNI不相上下——甚至在某些场景下,因为JIT能内联FFM调用,性能还能反超JNI。
举个真实的例子:RocksDB是一个用C++写的高性能键值存储,以前的Java客户端全靠JNI调用,不仅要处理复杂的内存复制,还经常因为JNI的bug导致崩溃。后来他们用Panana重构了Java客户端,直接用MemorySegment访问RocksDB的内存结构,结合PinnableSlice机制减少数据复制,结果显示,读取10KB大小的值时,性能提升了34%,代码量还减少了一半。
Panama带来的不只是开发效率的提升,更是Java生态边界的拓宽。以前Java在高性能计算、系统编程领域一直被C/C++压着打,不是因为Java性能差,而是因为调用本地库的成本太高——没人愿意为了一点性能提升,去写一堆JNI胶水代码。但现在有了Panama,Java可以无缝调用C/C++写的线性代数库、加密库、硬件驱动,甚至直接操作内存映射文件,性能和C/C++几乎没有差距。
比如在高性能计算领域,Java以前只能用纯Java实现的线性代数库,性能比C写的BLAS库差了几十倍。现在用Panama直接调用BLAS库,只需要几行Java代码就能实现矩阵乘法,性能和纯C代码几乎一样。还有大数据领域,以前Java处理大文件时,必须把数据读到堆内存里,不仅慢,还会给GC带来巨大压力。现在用Panama的MemorySegment直接访问内存映射文件,实现零拷贝读取,吞吐量提升了好几倍。
当然,Panama也不是完美的。目前它对复杂C++对象的支持还不够好,比如多重继承、虚函数表这些特性,还需要手动处理;而且jextract工具对一些高级C语言特性(比如函数宏、位域)的支持也还不完善。但这些问题都在逐步解决——Panama的API已经从JDK19的预览版,升级到了JDK22的正式版,未来还会支持更多语言,比如Rust、Go。
Java诞生的初衷是“一次编写,到处运行”,但JNI的存在却把它困在了自己的沙箱里。Project Panama的出现,终于让Java打破了语言的边界——它不用再羡慕C/C++的高性能,也不用再为了调用本地库而妥协。
这不是Java的一次小修小补,而是一次生态级的转向:它让Java既能保持跨平台、安全、易用的优势,又能无缝对接本地代码的高性能。未来,Java不仅能写Web应用、移动应用,还能写系统级程序、高性能计算程序,甚至直接操作硬件。
边界打通了,Java的下一个二十年,才刚刚开始。
跨语言不是妥协,是让优势更自由。