
1 个月前
1 个月前
你有没有过这种经历:想训练一个专属自己的AI模型,要么得掏几千块租云端GPU,要么看着自己电脑里的RTX显卡叹气——显存不够,速度慢到离谱,折腾三天还没跑出个像样的结果。
现在有人把这个门槛给拆了。Unsloth团队推出的Studio平台,能让单张消费级GPU的训练速度翻2倍,显存占用砍去70%,而且全程不用写一行代码,上传份PDF就能开始训模型。更关键的是,所有数据都在你本地电脑跑,不用怕隐私泄露。
这到底是怎么做到的?不是说大模型训练非得靠数据中心吗?
你可以把AI模型训练想象成一场大型流水线生产:GPU就是工厂车间,每个计算任务是待加工的零件,而内核代码就是车间里的流水线布局。传统框架用的是通用流水线,不管零件大小形状都按一套流程走,难免有浪费。
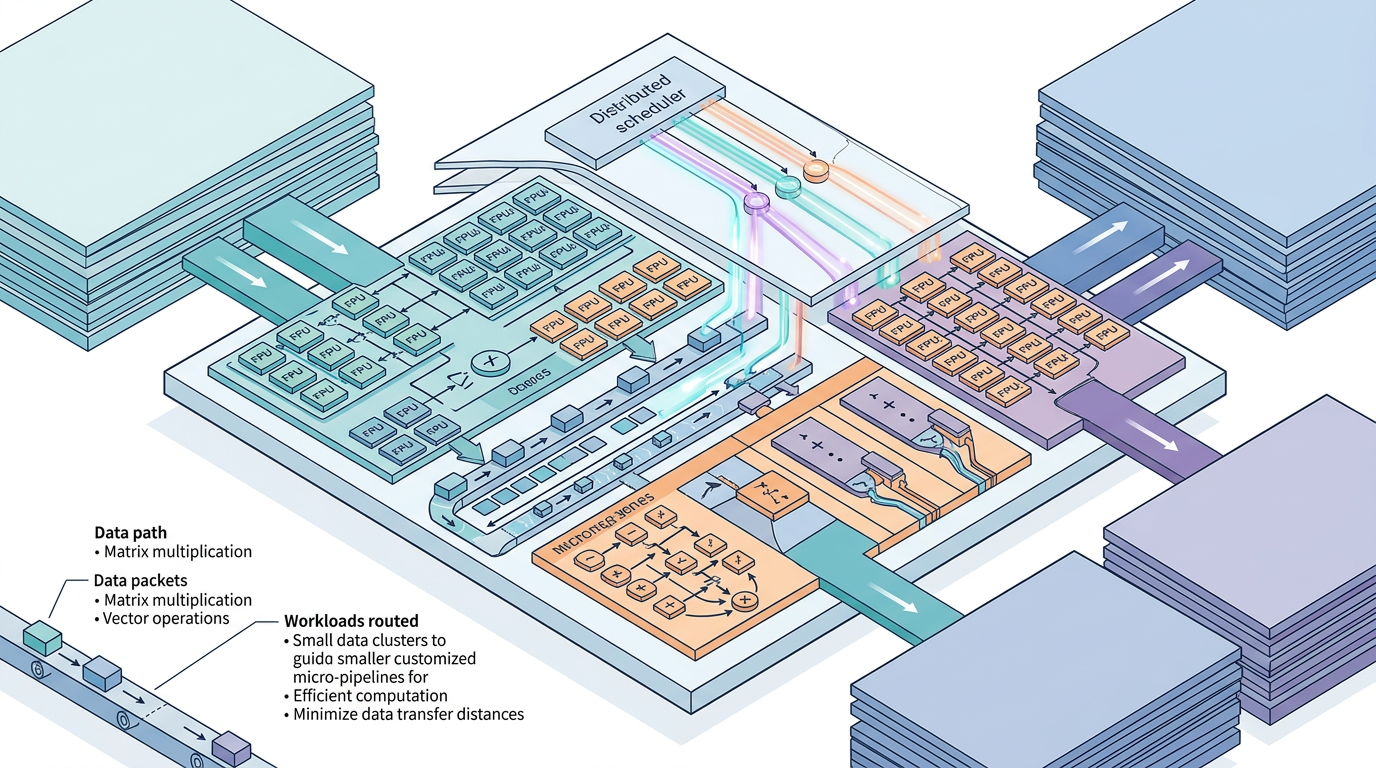
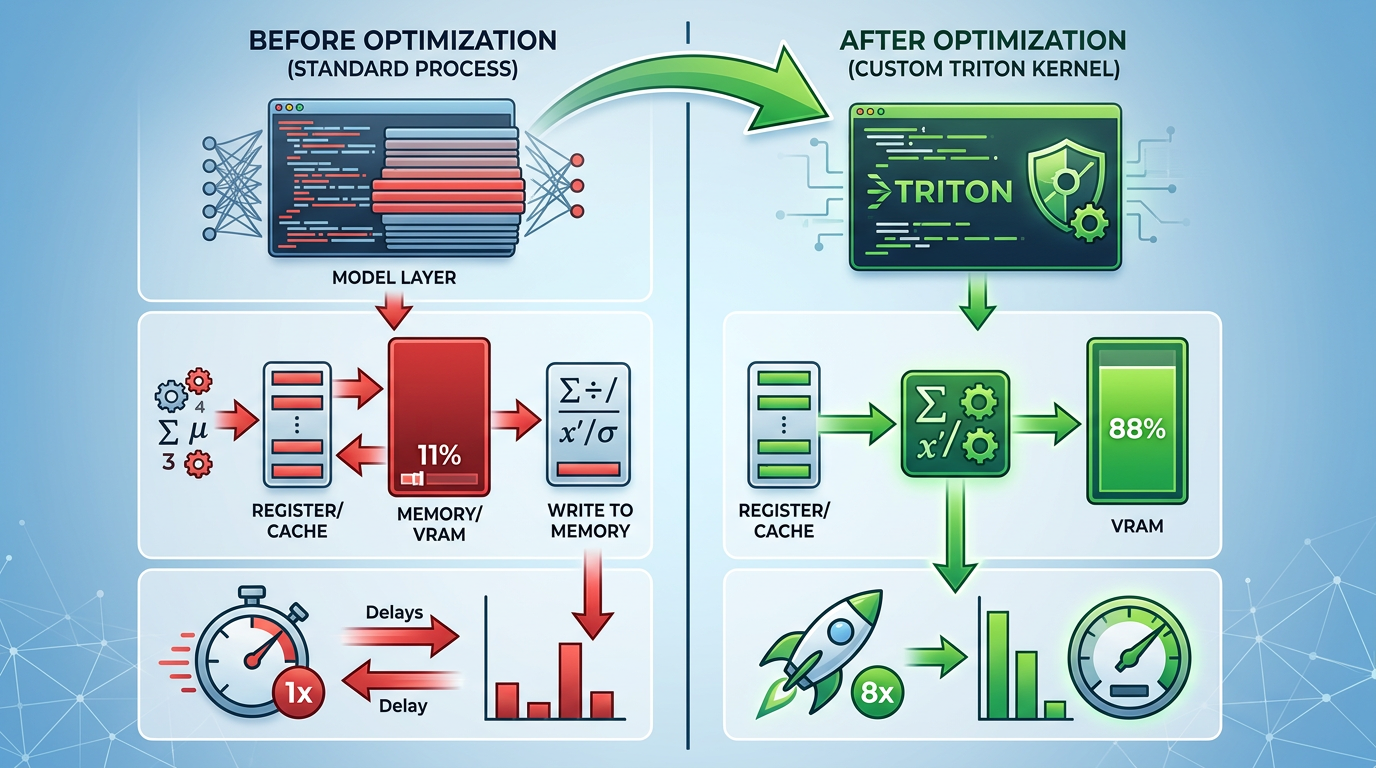
Unsloth的绝招,就是用OpenAI Triton语言手写了一套定制化流水线——也就是所谓的「Triton内核」。比如处理模型里的归一化操作,他们把原本要分三步的计算揉成了一步,让GPU不用反复读写内存,带宽利用率从11%直接飙到88%,速度翻了8倍。
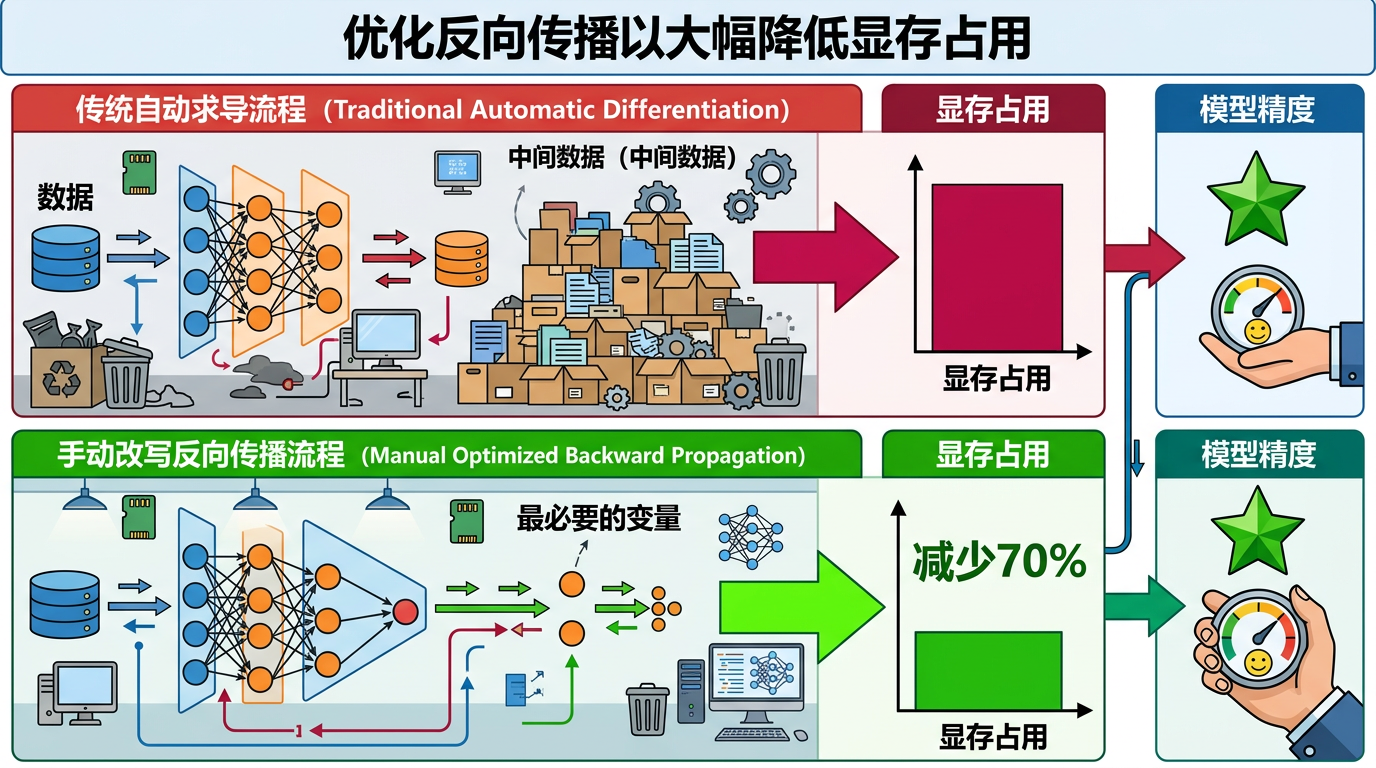
但真实的机制比这更精确:他们还手动改写了反向传播流程。传统自动求导会保存大量中间数据,像流水线里堆了一堆没用的半成品;而手动反向传播只留最必要的变量,相当于把车间里的冗余库存全清了。这一下就把显存占用砍去了70%,而且完全不损失模型精度。
举个直观的例子:用传统框架训Llama 3 8B模型,单张RTX 4090得开4-bit量化才能勉强跑;用Unsloth,直接用16-bit精度训,速度还能快2倍。
过去我们默认AI训练就得靠云端——毕竟大模型太吃资源,个人电脑扛不住。但这背后藏着两个没人说的痛点:一是贵,训个中等模型得花几百上千块;二是怕,敏感数据上传云端,相当于把公司机密或个人隐私递到别人手里。
Unsloth直接把这个逻辑拧过来了:既然云端贵又不安全,那就让训练全在本地跑。他们做的不只是优化速度,更是一套「本地优先」的生态:支持GGUF和Safetensors两种主流本地模型格式,训好的模型能直接导出给Ollama、LM Studio用;甚至能在手机上实时看训练进度,不用守在电脑前。
我认为这才是最被低估的突破——它不是让你「用得起」AI训练,而是让你「握得住」AI训练的控制权。之前你训模型,得看云服务商的脸色,遵守他们的数据规则;现在模型在你自己的硬盘里,想怎么调就怎么调,哪怕断网也能接着训。
当然它也有局限:目前只支持NVIDIA GPU,Mac用户暂时只能用来跑推理,多GPU训练的稳定性还在优化。但比起它撕开的口子,这些问题更像是成长中的小磕绊。
做开源项目最头疼的就是怎么活下去:要么靠捐款,要么得接受企业赞助,但都容易失去独立性。Unsloth用了个聪明的办法——双许可策略:核心代码用Apache 2.0许可,允许任何人免费商用甚至闭源;而UI部分用AGPL-3.0许可,只要你改了UI代码,就必须开源出来。
这相当于给项目搭了两层防护:核心代码的开放性吸引开发者和企业用它,保证生态的活跃度;UI的Copyleft条款又能留住社区贡献,防止有人拿了UI改改就变成自己的闭源产品。
这种平衡不是拍脑袋想出来的。之前很多开源项目要么因为许可太松被大企业白嫖,要么因为许可太严没人敢用。Unsloth的双许可既给了商业用户灵活度,又守住了开源社区的底线——毕竟要让项目长期活下去,不能只靠情怀,得有可持续的规则。
当我们还在讨论大模型参数谁能突破万亿的时候,Unsloth把目光投向了另一个方向:让普通人也能玩得起AI训练。这就像当年个人电脑取代大型机,不是因为性能更强,而是因为它把计算的权力还给了用户。
「AI的普惠,从来不是让所有人用同一个大模型,而是让所有人能训自己的模型。」未来的AI世界,不该只有几个云端巨头的通用模型,更该有数百万个藏在个人电脑里的小模型——可能是医生训的专属病例分析模型,可能是设计师训的风格生成模型,可能是你自己训的专属聊天机器人。
Unsloth不是第一个做本地训练平台的,但它是第一个把门槛降到这么低的。它让我们看到,AI的未来,不在云端的超级计算机里,而在每一台普通人的电脑上。
点击充电,成为大圆镜下一个视频选题!