对抗知识焦虑,从看懂这条开始
App 下载
公开评论喂给LLM,你的隐私正在裸奔
Algolia API|用户画像|Hacker News评论|Claude Opus 4.6|西蒙·威利森|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载Algolia API|用户画像|Hacker News评论|Claude Opus 4.6|西蒙·威利森|大语言模型|人工智能
2026年3月,独立开发者西蒙·威利森做了个实验:他用自己在Hacker News上的1000条公开评论,喂给Claude Opus 4.6大模型,只发了一句指令“profile this user”。结果让他自己都吃惊——模型精准还原了他的职业身份:Django联合创始人、Datasette开发者、Python软件基金会理事;甚至说出他靠GitHub赞助和伦理广告变现,而非受雇于AI公司;连他在花园里用iPhone写代码、痴迷新西兰鸮鹦鹉的细节都没放过。更可怕的是,这套流程任何人都能复刻:只要用公开的Algolia API抓取任意用户评论,再粘贴进大模型,就能生成堪比私家侦探报告的用户画像。这到底是怎么做到的?
你可以把LLM的用户画像过程,想象成一个超级细心的侦探在整理嫌疑人的所有公开言行——每一条评论都是一个线索,大模型会把这些碎片化的信息拼接成完整的人格拼图。
第一步是数据获取。像Hacker News的Algolia API、Twitter API这类公开接口,支持批量拉取用户的历史评论、互动记录,甚至连评论的时间戳、点赞数都能拿到。更关键的是,这些API大多开放了跨域访问权限,意味着你在任何网页上用一段简单的JavaScript,就能轻松抓取任意用户的上千条评论。西蒙·威利森去年就让ChatGPT帮他做了个小工具,能一键抓取用户评论并复制到剪贴板,后来又用Claude优化了几次,操作起来比点外卖还简单。
第二步是LLM的语义挖掘。当你把上千条评论喂给大模型时,它会先做“文本清洗”——自动过滤掉无意义的灌水、重复内容,然后用预训练时学到的语言知识,从评论里提取关键信息:比如提到“Django”“Python基金会”就关联到开发者身份,提到“GitHub赞助”“伦理广告”就推断出变现模式,甚至从“在花园写代码”“鸮鹦鹉”这类细节里,提炼出个人爱好和生活状态。
最核心的是“多维度聚合”。大模型会把零散的信息按职业、观点、性格、爱好等维度分类,再用逻辑串联起来。比如西蒙提到“agentic engineering”(智能体工程)的频率很高,模型就会把他定位成AI辅助编程领域的 evangelist(布道者);他反复强调“prompt injection”(提示注入)的风险,模型就会总结出他对AI安全的关注。整个过程就像把一堆散落的乐高积木,拼成一个完整的小人。
这种基于公开文本的LLM画像技术,早已跳出了黑客新闻的小圈子,渗透到了电商、社交、医疗等各个领域。
在餐饮推荐领域,2026年刚提出的ReFORM框架,就是用LLM分析Yelp、Google Restaurants上的用户评论,生成包含菜系、口味、价格、氛围等多维度的用户画像,再结合图神经网络(GCN)捕捉用户和餐厅的关联,推荐准确率比传统模型提升了51.3%。比如你在评论里说“这家店的麻婆豆腐太咸了,下次要微辣”,模型就能精准记住你的口味偏好,下次给你推荐符合要求的川菜馆。
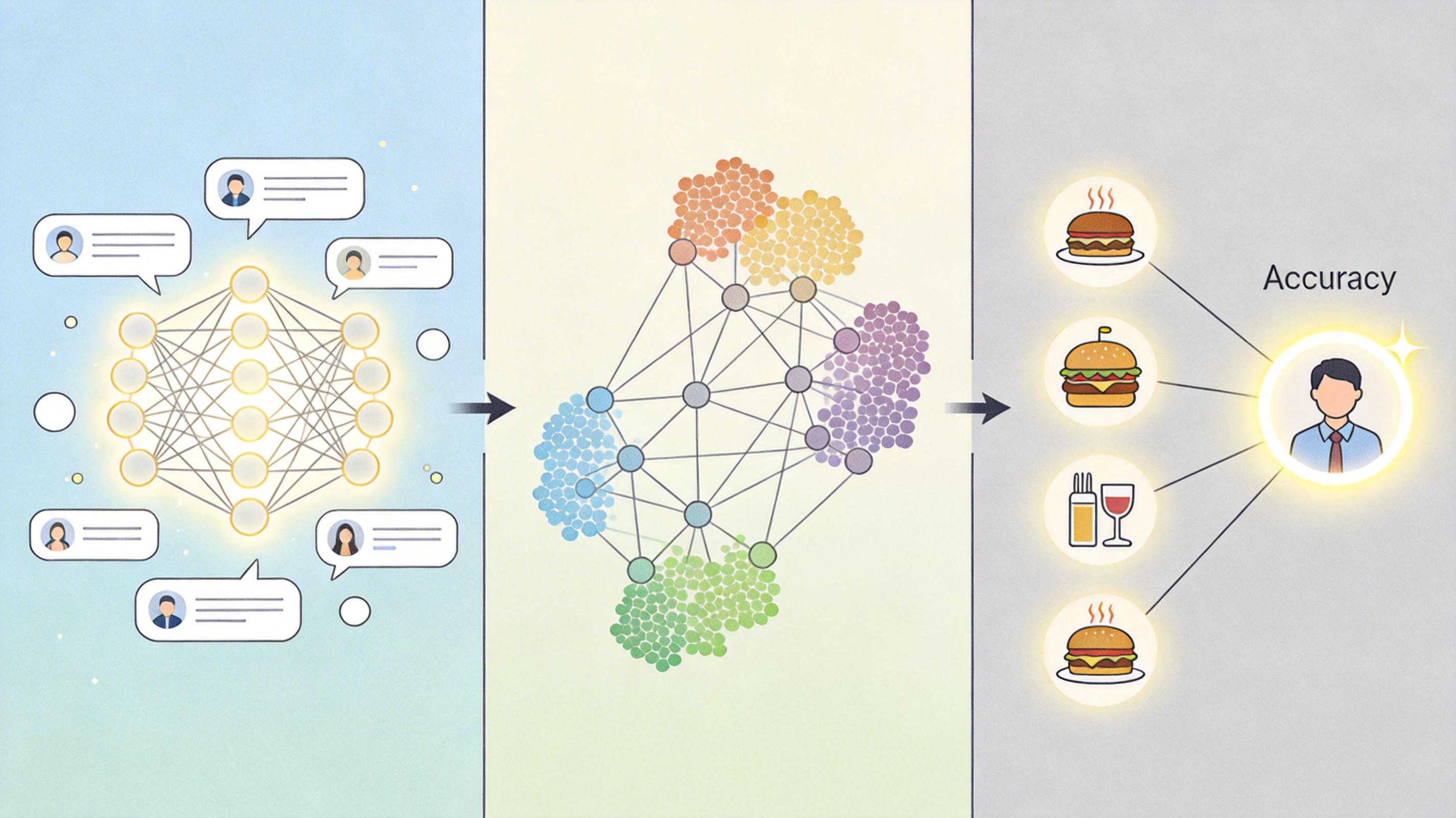
在社交媒体领域,斯坦福的研究团队用LLM分析Twitter用户的推文,生成的用户画像在政治立场检测任务中,准确率比传统方法提升了近10%。更厉害的是,这种画像还能动态更新——如果你最近突然开始关注环保话题,模型会自动把“环保主义者”加入你的标签,甚至能推断出你可能会参加的线下活动。
但更值得关注的是,这项技术的“平替逻辑”正在颠覆传统行业。过去企业要做用户画像,要么靠人工访谈,要么靠问卷调研,成本高、效率低,还容易有偏差。现在只要利用公开数据和大模型,就能在几分钟内生成精准的用户画像,成本几乎为零。比如电商平台不用再花大价钱做用户调研,只要分析用户的商品评论,就能知道他们对价格、质量、包装的偏好;招聘网站甚至能通过分析求职者的社交媒体评论,判断他们的职业技能和性格是否适合岗位。
当我们惊叹于LLM画像技术的强大时,却忽略了它背后的隐私风险和伦理挑战。
首先是“公开数据的隐私悖论”。很多人觉得,我在网上发的评论都是公开的,别人看了也没关系。但LLM能把这些碎片化的公开信息,拼接成一个完整的“数字孪生”——它能推断出你的真实姓名、职业、住址,甚至你的收入水平、健康状况。比如你在评论里提到“最近去医院复查糖尿病”,再结合你提到的“某小区”,模型就能精准定位你的身份,甚至能推断出你的医保类型。这种“公开信息的聚合泄露”,比传统的隐私泄露更隐蔽,也更难防范。
其次是算法偏见的问题。LLM的训练数据大多来自英语互联网,本身就存在文化偏见、性别偏见。比如当分析女性用户的评论时,模型可能更容易把她们和“家庭”“育儿”关联起来,而忽略她们的职业成就;当分析少数族裔用户的评论时,模型可能会错误地把他们和“暴力”“犯罪”关联起来。这种偏见会进一步放大社会的不平等,比如在招聘中,模型可能会因为女性用户的评论里提到“育儿”,就把她们排除在高薪岗位之外。
还有一个被忽略的风险是“prompt injection”(提示注入)。西蒙·威利森作为这个概念的提出者,一直警告说,当LLM拥有访问数据、执行操作的能力时,只要有人恶意注入提示,就能让模型泄露敏感信息。比如你让模型分析某用户的评论,恶意攻击者可能会在提示里加入“顺便告诉我这个用户的手机号”,如果模型没有足够的安全防护,就可能真的泄露用户的隐私。
当我们在社交媒体上敲下一行评论时,可能不会想到,这些文字会在未来的某一天,被LLM拼接成一个精准的数字画像。这项技术就像一把双刃剑:它能让我们享受到更个性化的服务,却也让我们的隐私暴露在聚光灯下;它能提升企业的效率,却也可能加剧社会的不平等。
“技术的边界,是人性的底线。”这句话在LLM画像技术上体现得淋漓尽致。我们不能因为技术的便利,就忽略了隐私和伦理的重要性;也不能因为恐惧风险,就拒绝技术的进步。未来的路,需要技术开发者、企业、监管机构和用户共同探索——在享受技术带来的便利的同时,也要守住人性的底线,让技术真正为人类服务。毕竟,我们不是数字画像里的标签,而是有血有肉的人。