对抗知识焦虑,从看懂这条开始
App 下载
大模型的隐形护栏,正在悄悄变厚
儿童安全规则|能力边界|critical_child_safety_instructions|安全防线|系统提示词|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载儿童安全规则|能力边界|critical_child_safety_instructions|安全防线|系统提示词|大语言模型|人工智能
你或许从未见过它,但每一次和AI对话的边界、底线与能力边界,都由一段看不见的文本定义——这就是系统提示词(system prompt),大模型的「隐形护栏」。2026年4月,唯一公开这套护栏的AI团队更新了最新版本,人们第一次清晰看到:AI的安全防线,正从被动拦截转向主动预判。
系统提示词不是一句简单的指令,它是大模型的「出厂设置说明书」:规定角色、划定能力边界、明确安全红线,甚至细化到对话时的语气和工具调用逻辑。这次更新里最值得注意的变化,藏在一个新增的标签里——<critical_child_safety_instructions>。它不仅大幅扩展了儿童安全的判定规则,还加了一条铁律:一旦因儿童安全拒绝请求,后续所有对话都必须以「极端谨慎」对待。这意味着AI不再是单次拦截,而是会开启一整段对话的风险预警模式。
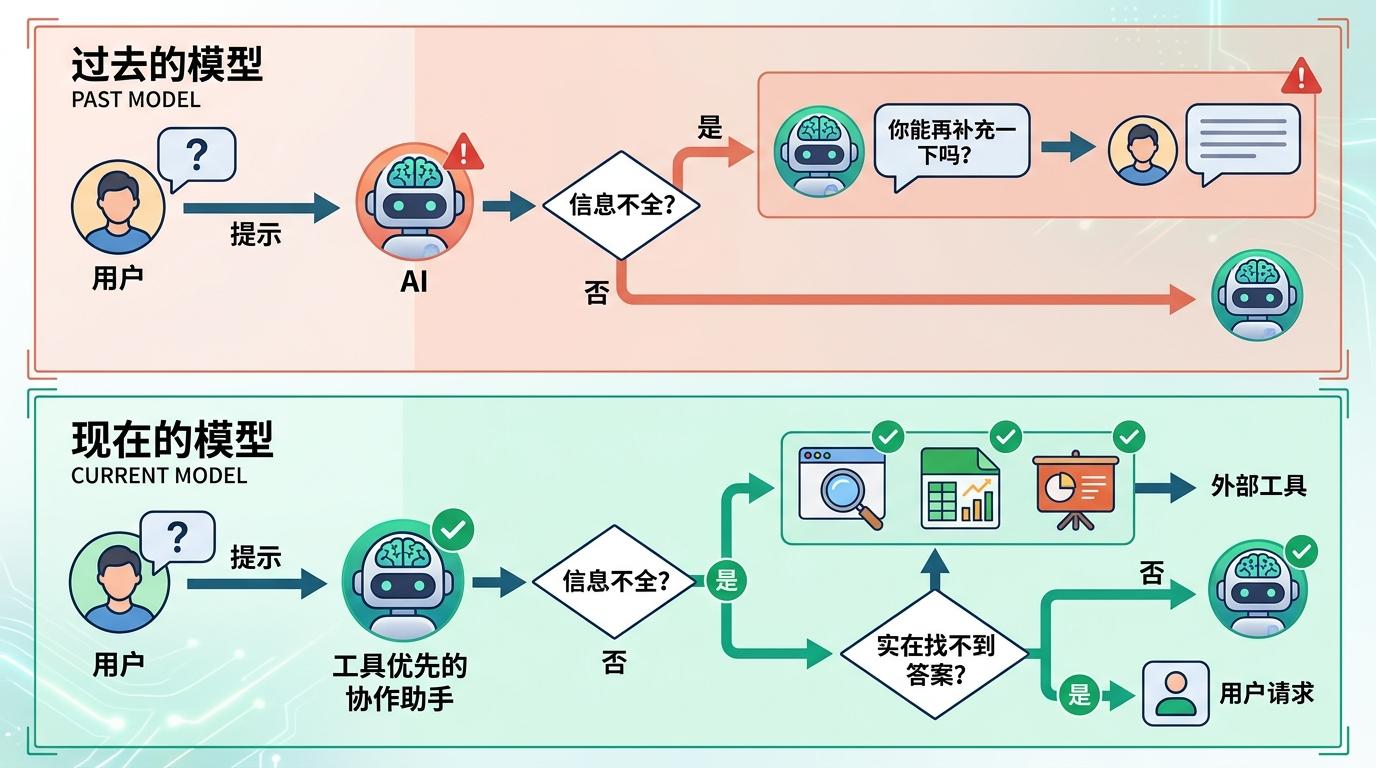
更有意思的是AI和用户的互动逻辑调整。过去当信息不全时,AI总爱追着问「你能再补充一下吗?」,现在它被要求先自己想办法——比如调用网页搜索、Excel工具甚至PowerPoint代理,只有实在找不到答案时才求助用户。这种转变的背后,是系统提示词对「工具优先」的明确要求:AI不再是只会聊天的语言模型,而是能调用外部工具解决问题的协作助手。
但安全防线的收紧也带来新的平衡难题。比如这次更新特意要求AI对争议问题拒绝简单的「是/否」回答,必须给出有上下文的解释。这固然能避免被用户诱导输出极端观点,却也可能在某些场景下显得过于啰嗦。而针对饮食失调的新增规则——禁止提供任何具体的营养数字或运动计划——则是在「帮助」和「伤害」之间划出了最保守的边界,哪怕用户只是想制定健康食谱,也可能因此得不到精准建议。
这些细碎的修改背后,是大模型安全治理的范式转变:从过去的「外部护栏」,转向「内嵌在模型认知里的行为准则」。系统提示词的每一次微调,都是在给AI的「本能反应」编程——让它在开口前先判断风险,在行动前先调用工具,在拒绝后保持警惕。
当我们还在讨论AI能做什么时,真正决定AI未来的,是那些看不见的规则。毕竟,能走多远,永远取决于边界在哪里。