对抗知识焦虑,从看懂这条开始
App 下载
本地云端无缝联动,OpenDuck重构云数据库体验
本地云端联动|混合执行架构|云原生数据库|MotherDuck|OpenDuck|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载本地云端联动|混合执行架构|云原生数据库|MotherDuck|OpenDuck|AI产业应用|人工智能
当你在笔记本上敲下一行SQL,要把本地的用户表和云端的交易表做关联查询时,你会先把数据全部下载到本地?还是把本地数据上传到云端?过去你总得二选一——要么耗光本地内存,要么等半天网络传输。但现在,有个工具能让同一条查询拆成两半:小表在你电脑上跑,大表在云端服务器算,只传中间结果,全程像操作本地数据一样自然。这就是OpenDuck,一个把MotherDuck的核心思路彻底开源的云原生数据库方案,它正在打破本地和云端的数据库边界。
你可以把混合执行架构想象成一个聪明的快递分拣员:收到一个跨本地和云端的查询请求后,它会先拆开看——哪些数据在本地电脑里,哪些在云端对象存储里,哪些计算适合用本地CPU,哪些得靠云端的大内存。比如统计用户消费习惯,它会让本地电脑扫描小体量的用户表,同时让云端服务器处理千万级的交易表,最后只把两边筛选后的结果传回来做关联。
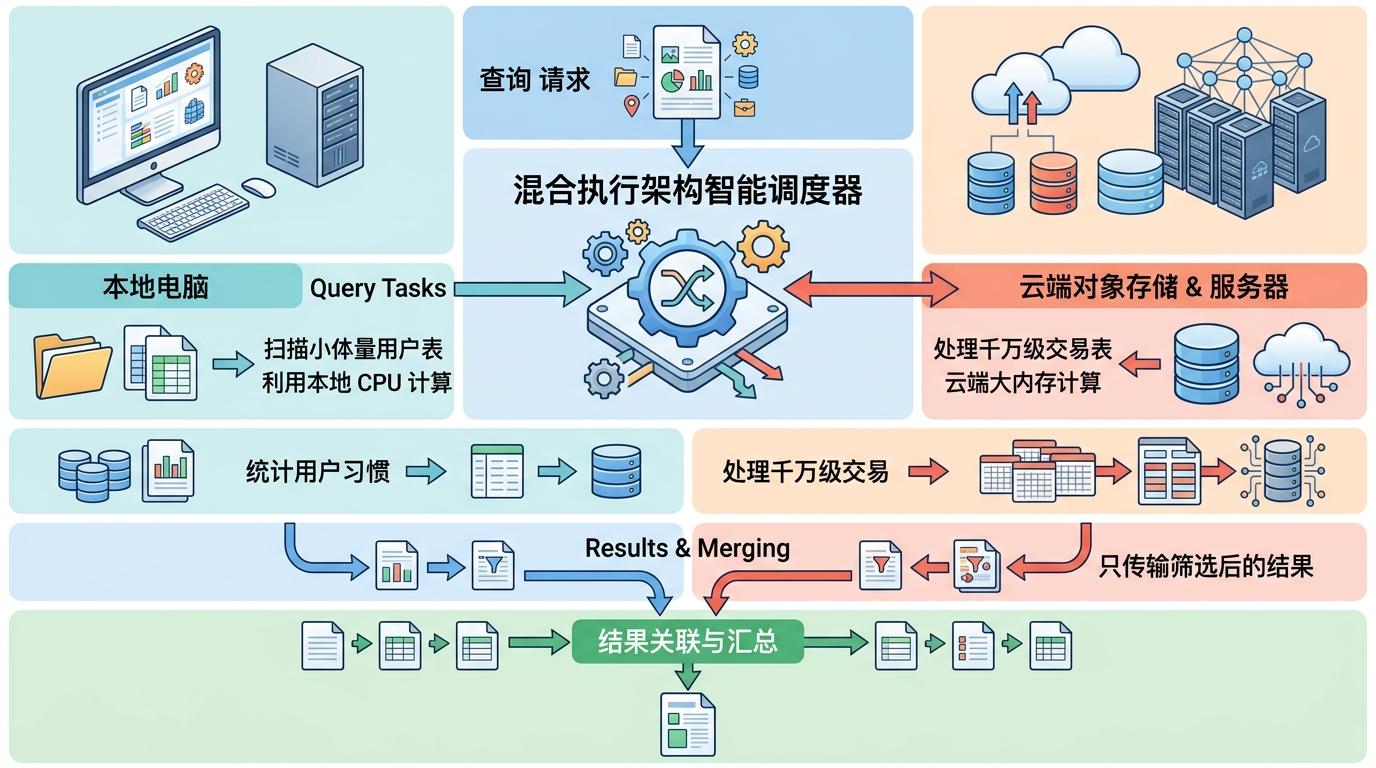
具体到技术上,OpenDuck的Rust网关会先把查询计划拆成一个个小算子,给每个算子打上「本地」或「远程」的标签,再在中间插入桥接算子负责数据传输。整个过程对用户完全透明,你敲的SQL和操作本地数据库没有任何区别,但背后已经完成了一次跨设备的协同计算。
这种设计最直接的好处是省成本——不用把几十GB的数据来回传输,网络带宽和云端算力都能省出一大截。有公司试过,把原来8小时的财务数据处理管道压缩到了8分钟,效率翻了60倍。
如果说混合执行是OpenDuck的「大脑」,那差分存储就是它的「仓库」。传统数据库改数据是直接原地修改,就像在一本书里涂涂改改,想找回昨天的版本得费劲翻备份。但OpenDuck的差分存储是「只加不改」:每次写入数据都像堆一块新的乐高积木,删除数据只是插个「已删除」的标记,永远不会动之前的积木。
这些「乐高积木」就是存在对象存储里的不可变密封层,配合PostgreSQL风格的元数据管理,DuckDB客户端看起来就是一个普通文件,但背后已经实现了快照功能。你要恢复到昨天的数据状态,不用复制任何实际数据,只是切换一下元数据的指针,一秒就能完成。
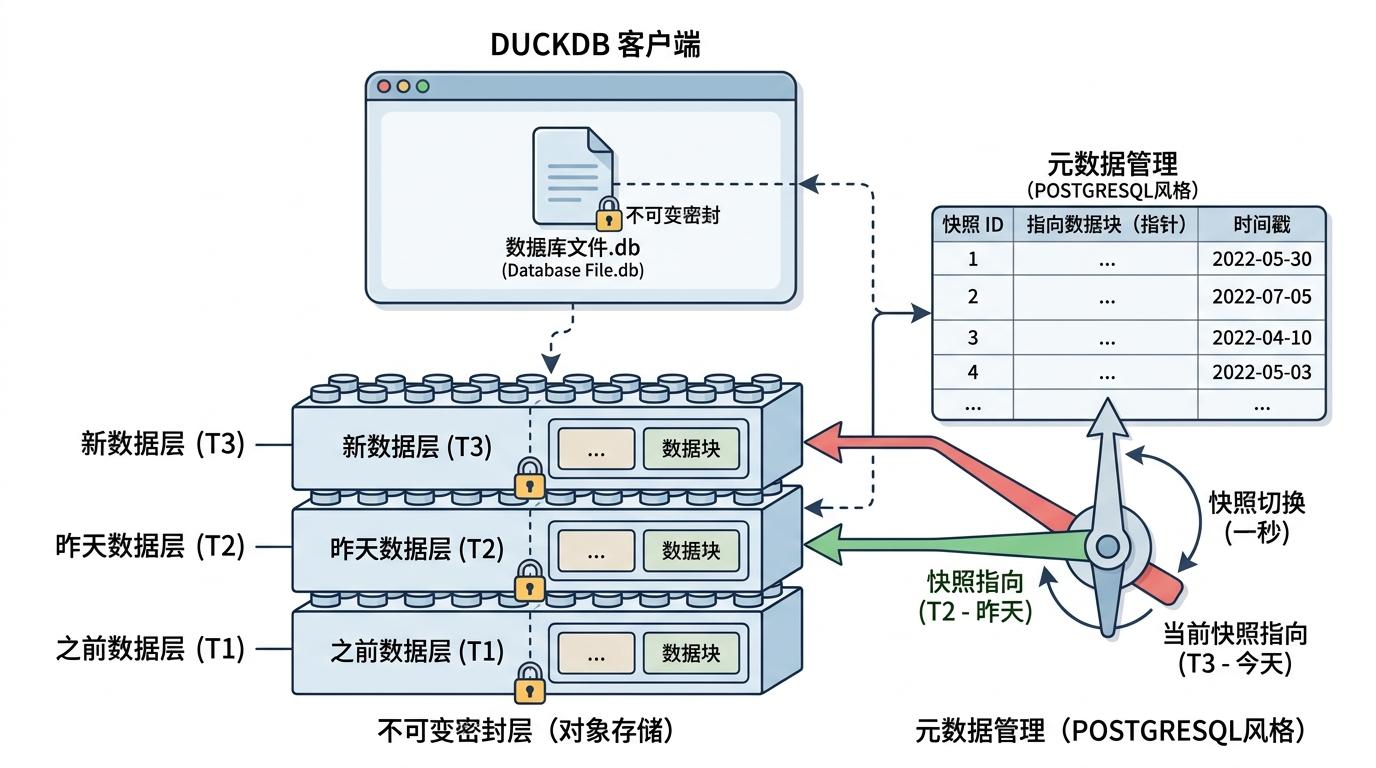
这种设计天然适合多并发读取——几百个人同时查数据,各自拿自己的快照,互相不会干扰。而且因为数据只追加不修改,不会产生碎片,存储效率也比传统数据库高得多。
当然,OpenDuck也不是能解决所有问题的万能药。它天生是为分析型查询(OLAP)设计的,比如统计报表、用户行为分析这种需要扫描大量数据的场景,但如果是高并发的交易型业务(OLTP)——比如电商平台的实时下单,它的表现就不如传统的PostgreSQL或MySQL。
它的分布式能力也有局限:虽然能跨本地和云端协同,但本质还是基于单节点DuckDB的扩展,面对PB级别的超大规模数据,或者需要跨地域分布式计算的场景,还是得靠Snowflake、ClickHouse这类专门的分布式数据仓库。
还有一点需要注意,目前它的事务支持还不够完善,复杂的多表写入操作可能会有一致性风险,适合以读为主、写操作相对简单的场景。
过去十年,云数据库的发展一直在往「大而全」走:更大的集群、更复杂的分布式协议、更昂贵的算力套餐。但OpenDuck反其道而行之,它把注意力拉回了开发者本身——能不能让云数据库像本地数据库一样好用?能不能用最少的成本完成复杂的分析?
它不是要取代那些成熟的分布式数据仓库,而是给了市场一个新的选项:一种轻量、灵活、开放的云原生数据库形态,让开发者不用再在本地和云端之间做艰难的取舍。
本地与云端的边界,本就不该存在。