对抗知识焦虑,从看懂这条开始
App 下载
智能眼镜不用手,靠眼神和手势就能控
实时翻译|手势识别|眼动追踪|多模态交互|AI智能眼镜|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载实时翻译|手势识别|眼动追踪|多模态交互|AI智能眼镜|多模态视觉|人工智能
你站在异国街头,盯着路牌上的陌生文字,镜片上立刻跳出一行母语翻译;抬手虚捏一下,刚识别的咖啡馆地址就叠在了视野里——这不是科幻电影的镜头,而是2026年多模态AI智能眼镜的日常。它能听懂你压低的语音指令,看懂你指尖的细微动作,甚至能顺着你的视线判断你想关注什么。但这些看似自然的交互,背后是一套精密到像人类感官系统的技术逻辑。
多模态AI交互的核心,是让设备像人一样“多感官协同”。它不像传统智能设备只认单一指令,而是同时抓取视觉、语音、手势、眼动等多种信号,再用AI模型把这些信息拧成一股——就像你同时用眼睛看、耳朵听、手指指,大脑会自动把这些线索拼出完整意图。比如你盯着货架上的罐头说“找低糖的”,它不会只搜“低糖”这个词,还会结合你视线锁定的区域、手指的指向,精准定位你要的那款,而不是跳出全超市的低糖食品。

要实现这种协同,硬件和算法得踩准同一个节拍。高分辨率摄像头和深度传感器负责“看”,捕捉环境细节和你的手势动作;多麦克风阵列用波束形成算法聚焦你的声音,过滤掉街头的噪音;眼动追踪摄像头盯着你的瞳孔,判断你的注意力落点。这些数据会被实时传到AI模型里,用特征级融合技术把不同模态的信息捏合在一起——不是简单相加,而是让视觉数据里的“罐头轮廓”和语音数据里的“低糖”语义自动关联,最终输出准确的响应。
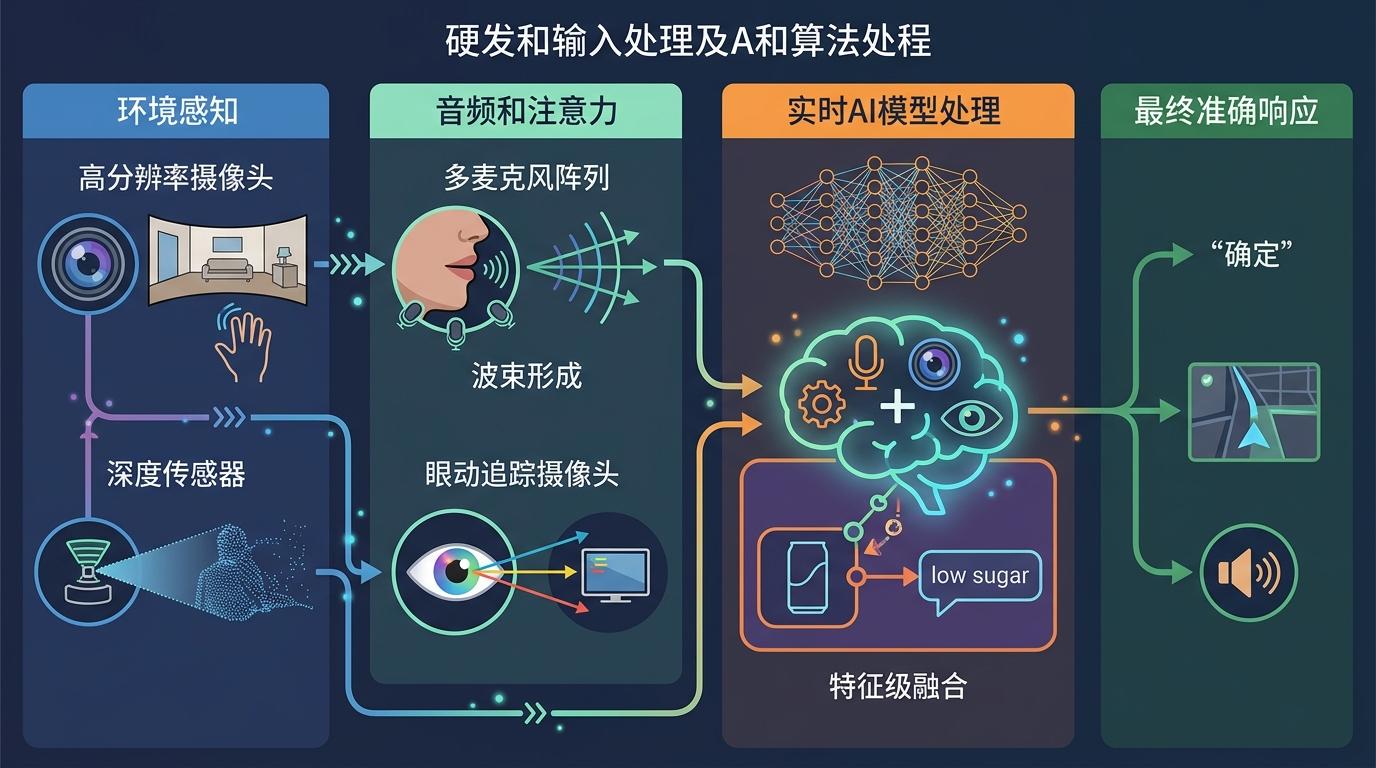
但这套系统离真正的“自然”还有距离。目前的多模态AI还做不到像人类一样理解复杂语境,比如你在嘈杂的餐厅里含糊说“那个”,它可能搞不清你指的是桌上的水杯还是服务员手里的菜单;强光下的手势识别准确率会骤降,眼动追踪也会因为你眨眼频繁而失焦。更关键的是隐私问题——它时刻在“看”在“听”,如何保证这些数据只用来服务你,而不会被泄露或滥用,是比技术难题更棘手的挑战。
未来的智能眼镜,会更像一个“隐形助手”:它不会用闪烁的灯光或繁琐的指令打扰你,只会在你需要时,悄悄把信息推到你视线里。但要走到这一步,不仅要让AI更懂人类的意图,还要在便捷和隐私之间找到精准的平衡——毕竟,没人希望自己的日常视线,变成被记录的数据。
科技的终极目标,是让工具隐于生活。