对抗知识焦虑,从看懂这条开始
App 下载
选不对主键,你的数据库慢75倍
数据库性能|UUID|自增ID|B+树索引|主键类型|计算科学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载数据库性能|UUID|自增ID|B+树索引|主键类型|计算科学|数理基础
你有没有遇过这种怪事:同样是往数据库插10万条数据,同事的代码跑0.017秒就完成,你的却花了1.29秒——慢了整整75倍。
别怀疑是服务器配置差,也别甩锅给网络延迟。问题的根儿,藏在你看不见的数据库底层:一种叫B+树的索引结构,和你随手选的那个主键类型。
你可能从没关心过主键用自增ID还是UUID,但就是这个不起眼的选择,正在悄悄拖垮你的数据库性能。这到底是怎么回事?
你可以把B+树想象成超市里的货架——每个货架(节点)能放多瓶饮料(键值对),货架之间有清晰的分类指引(子指针),所有商品都整整齐齐摆在最底层的货架(叶子节点)上,还按品类连了成排的购物车(双向链表)。
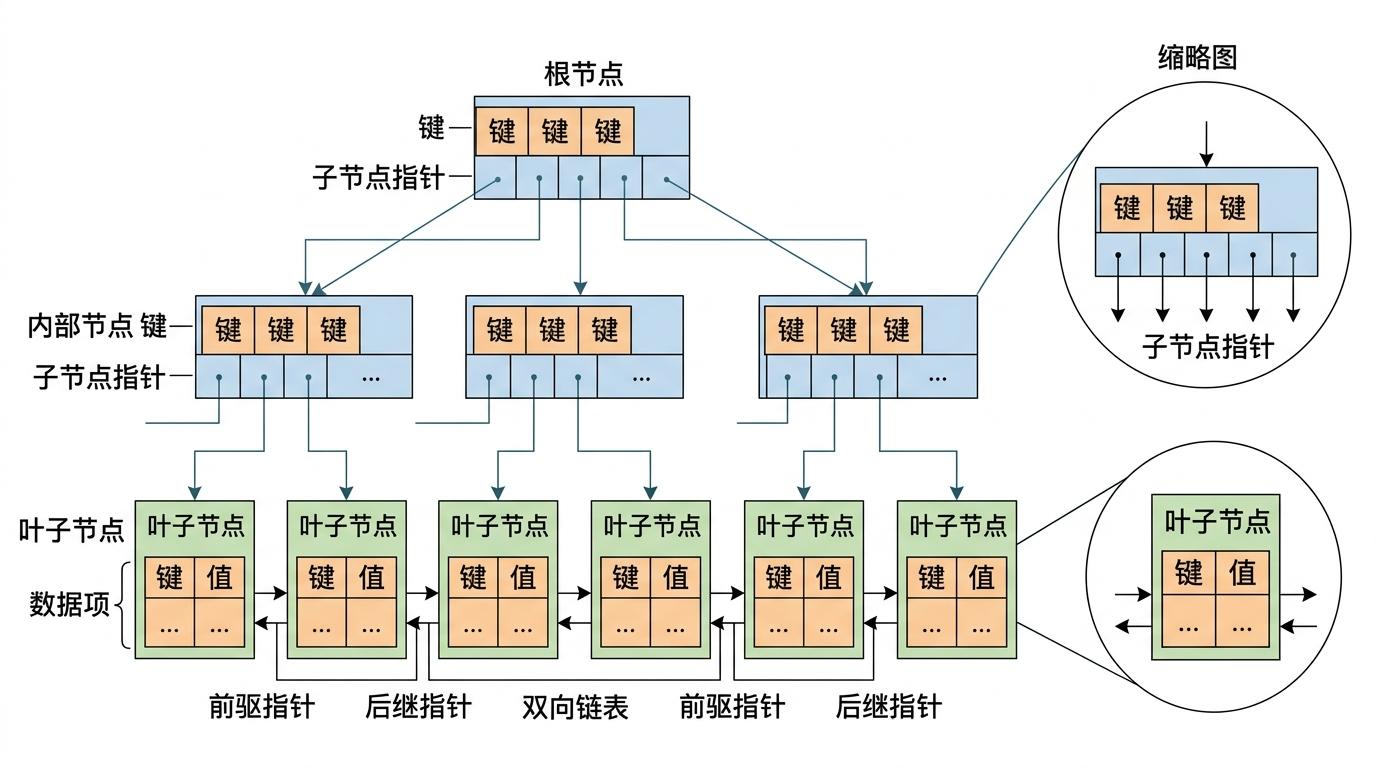
和普通货架不同,B+树是为磁盘量身定做的:每个节点大小刚好等于磁盘的一页(比如16KB),这样每次读取就能把一整个货架的信息都装进内存。它的规则很简单:内部节点只存分类指引,所有数据都在底层叶子节点;叶子节点按顺序连在一起,找东西时要么按指引精准定位,要么顺着货架一排扫过去。
更关键的是,这棵树永远是“平衡”的——不管你往里面塞多少东西,从根节点到任何一个叶子节点的路径长度都一样。这意味着不管数据量多大,查询、插入的时间复杂度都是O(log n),不会突然变慢。
主键就是B+树的“排序依据”——就像超市按饮料品牌还是价格摆货架,选不同的主键,整个B+树的结构会天差地别。
如果选自增整数当主键,就像按进货顺序摆货架:新到的饮料永远往最右边的货架上摆,摆不下了就直接加个新货架在右边。整个过程只需要碰最右边的几排货架,几乎不会打乱现有布局,也很少需要重新调整分类指引。
但要是选UUIDv4这种随机主键,情况就完全变了:你不知道新到的饮料该摆在哪,只能随机找个空位塞进去。塞不下了就得把一个货架拆成两个,还得重新调整上层的分类指引。插得越多,货架就越乱,找东西时要逛的货架也就越多。
实测数据最能说明问题:插入10万条数据,自增主键只需要访问寥寥几个节点,UUIDv4却要在几十个节点间跳来跳去,磁盘I/O直接翻了好几倍——这就是为什么你的代码会慢75倍。
你可能会说,分布式系统里自增主键不好用啊,总不能专门整个中心节点发号吧?
别着急,2024年获批的UUIDv7给出了答案。它把48位的毫秒级时间戳放在UUID的最前面,后面再跟随机数——既保证了全局唯一,又让生成的UUID能按时间顺序排列。
用UUIDv7当主键,就像按进货时间摆货架:新到的饮料还是往右边摆,偶尔有几瓶晚到的插在中间,但整体还是有序的。测试显示,它的插入速度比UUIDv4快30%-50%,索引碎片减少了20%-25%,还能直接用UUID做时间范围查询,不用额外加时间戳字段。
当然它也不是完美的:时间戳会暴露数据生成的大致时间,敏感场景得谨慎用;而且它还是比自增ID占空间——16字节的UUID,能让每个B+树节点存的键值对少一半,树的高度也会多一层。
很多时候,我们总盯着业务代码优化,却忘了数据库底层的这些“隐形规则”。B+树就像一个沉默的管家,你给它清晰的指令(自增ID),它就高效打理好一切;你给它混乱的要求(随机UUID),它也会照做,但代价就是慢、卡、资源浪费。
选对主键,就是给数据库搭对骨架。 未来的数据库会越来越复杂,但底层的逻辑永远不变:有序、紧凑、可预测,才是性能的核心。下次设计表结构时,别再随手选UUID了——多花10秒钟想想,这棵B+树该怎么长。