对抗知识焦虑,从看懂这条开始
App 下载
开源项目拒绝AI代码,背后赌的是人
并行语义分析|开源贡献规则|LLVM后端|Bun团队|Zig社区|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载并行语义分析|开源贡献规则|LLVM后端|Bun团队|Zig社区|AI安全治理|人工智能
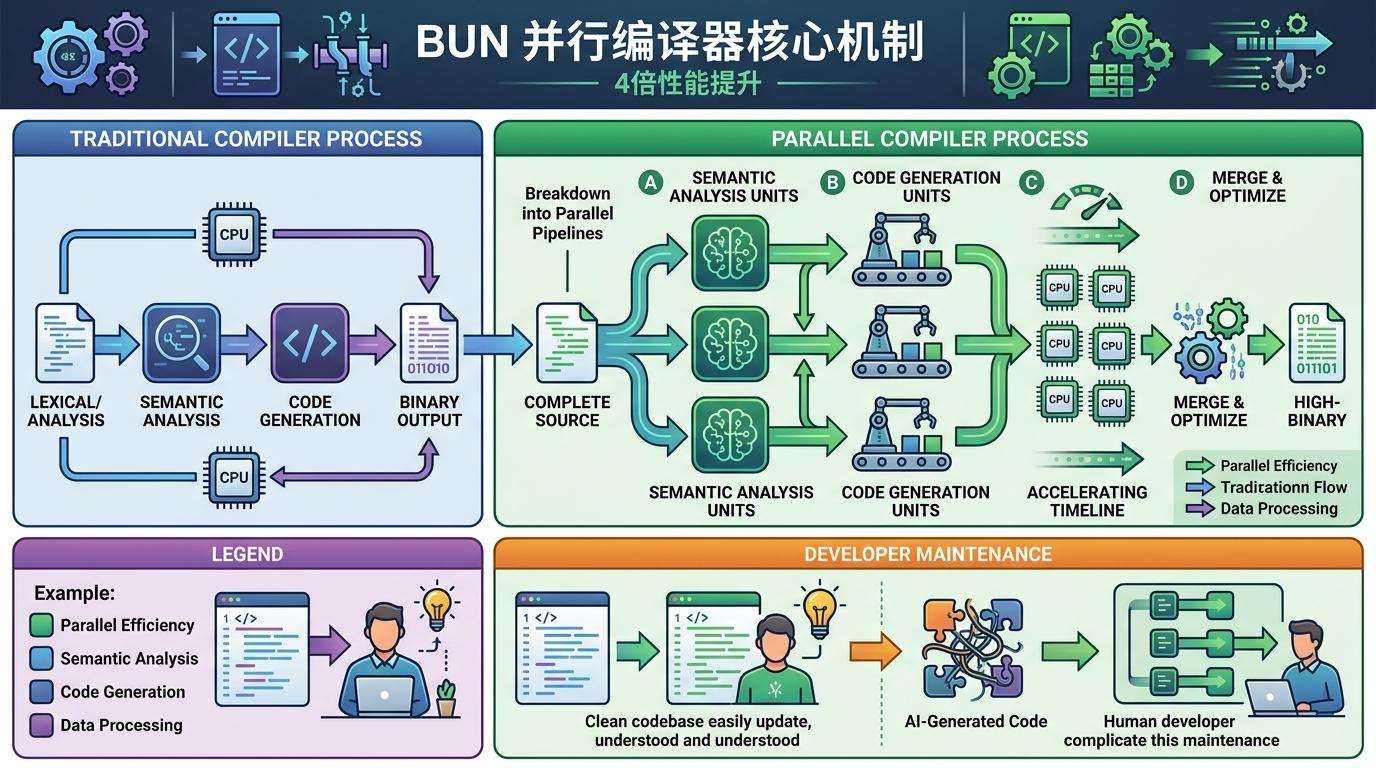
当Bun团队把Zig编译器的编译速度提升了4倍——靠的是给LLVM后端加上并行语义分析和多代码生成单元,让代码像流水线一样同时拆解、分析、生成——他们却宣布不会把这部分代码合并回Zig的主线项目。原因简单得让人意外:Zig社区有一条铁律,禁止任何大语言模型(LLM)辅助的代码贡献,哪怕是能带来4倍性能提升的代码也不行。这不是技术洁癖,而是一场关于开源社区本质的赌注。为什么一个开源项目会拒绝送上门的技术升级?答案藏在他们对「人」的定义里。
你可以把开源项目的PR审核看成一场特殊的扑克局——不是看手里的牌(提交的代码)有多好,而是看出牌的人(贡献者)值不值得投资。Zig社区副总裁Loris Cro把这叫「贡献者扑克」:核心团队的时间不是用来筛选完美代码的,而是用来培养能持续贡献的人。
对于成熟的开源项目,维护者的时间是最稀缺的资源。当PR数量超过审核能力时,大多数项目会优先挑最有用的代码合并,但Zig反其道而行之:他们宁愿花几个小时帮一个新手把满是bug的PR改对,也不愿快速合并一个AI生成的完美PR。因为前者能培养出一个未来会帮着维护项目的核心成员,后者只是给代码库加了一段没人能兜底的代码。
LLM恰恰打碎了这个逻辑。AI能帮新手写出看似专业的代码,但维护者无法从这段代码里判断,这个新手到底是真的理解了项目架构,还是只是AI的「提词器」。如果维护者花时间去审核这段AI代码,本质上是在和AI对话,而不是在培养能和团队并肩的人——等代码合并完,这个新手可能还是看不懂自己提交的代码,更别说未来参与维护了。
让Bun性能暴涨4倍的「并行语义分析和多代码生成单元」,本质上是把编译器的工作拆成了多个并行的流水线——就像把一条单人包饺子的生产线,改成多人同时擀皮、包馅、捏褶。但如果这段代码是AI生成的,维护者要面对的就不只是代码本身:
首先是「验证债务」。AI生成的代码往往能通过基础测试,但藏着只有在复杂场景才会暴露的bug——比如并行任务的资源竞争、语义分析的边界漏洞。维护者要花数倍于审核人类代码的时间,去排查这些AI「脑补」出来的逻辑漏洞。康奈尔大学的研究显示,三分之一的AI生成代码含有安全漏洞,而且修复这些漏洞时,42%的情况会引入新问题。
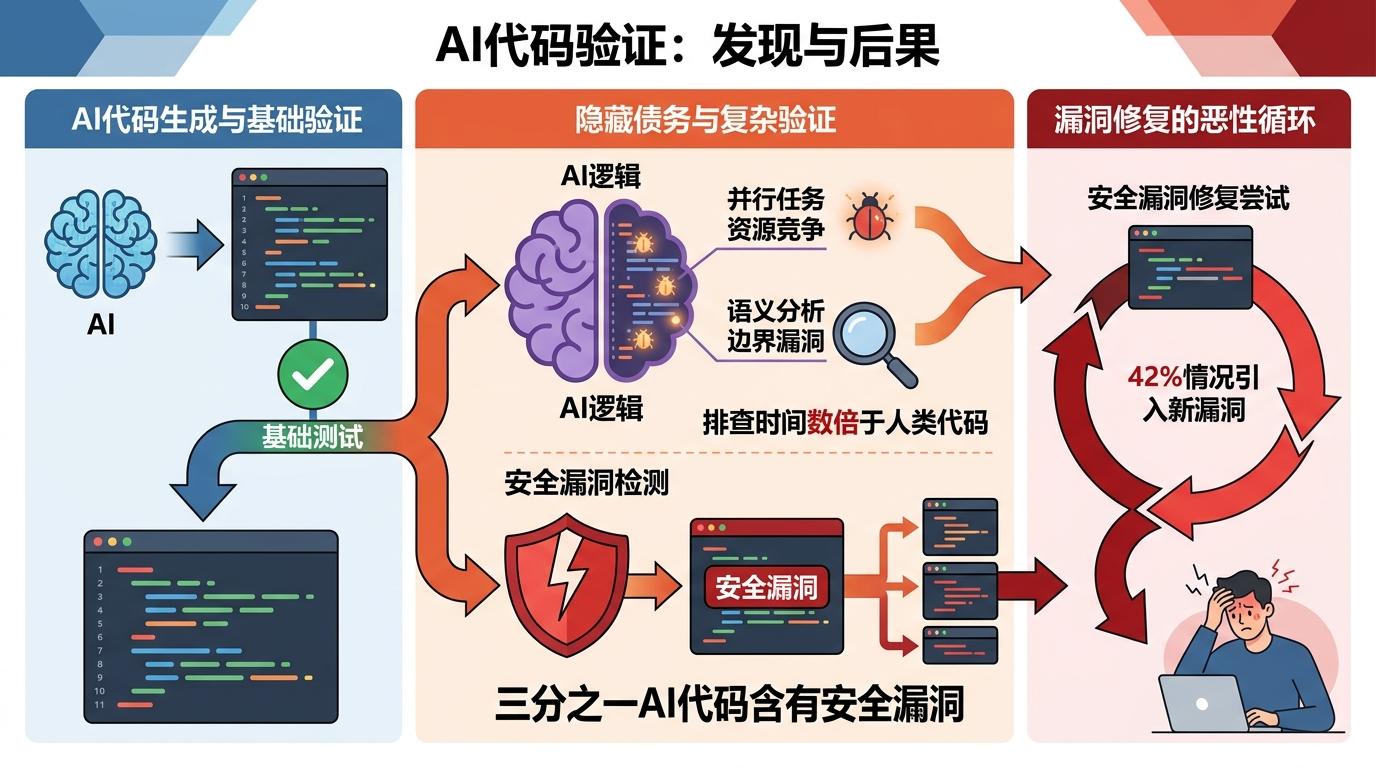
更关键的是「责任真空」。当AI代码在生产环境出问题时,没人能说清是谁的责任:是写提示词的贡献者?是训练AI的公司?还是维护代码的社区?开源社区的信任建立在「人对代码负责」的基础上,而AI把这个责任链拆成了碎片。
还有「技能退化」的隐忧。新手依赖AI生成代码,会跳过最基础的学习过程——比如理解为什么要这么写,而不是只知道要这么写。就像依赖导航的司机记不住路,依赖AI的开发者很难成长为能独立解决复杂问题的核心成员。
AI正在把开发者社区撕成两半。一边是资深开发者,他们把AI生成的低质量PR看成「数字垃圾」——Reddit的r/programming社区甚至一度封禁了所有LLM相关话题,因为这些话题淹没了真正有深度的技术讨论。他们担心AI会把社区变成一个「代码加工厂」,而不是一个「开发者成长营」。
另一边是新手开发者,他们把AI当成入门的敲门砖。没有AI的帮助,他们可能连第一个PR都提交不出去——毕竟写代码的门槛对新手来说太高了。但当社区禁止AI辅助,他们又会觉得被排斥,转而流向那些对AI更宽容但质量更低的平台,形成新的「信息真空」。
这种分裂本质上是两种价值观的冲突:是优先让更多人参与进来,还是优先保护社区的长期质量?LLVM的「人类在环」政策试图找一个中间地带:允许使用AI,但要求贡献者必须完全理解AI生成的代码,能回答维护者的所有问题。但这又带来了新的问题:怎么判断贡献者是不是真的理解代码?维护者的时间本来就不够,还要额外承担「AI侦探」的工作。
当我们讨论开源社区要不要接受AI代码时,其实是在问一个更本质的问题:开源的核心是代码,还是人?
Zig的选择给出了一个答案:开源的生命力从来不是代码的数量,而是人的连接。那些被维护者花时间培养出来的开发者,会变成项目的「活文档」,他们不仅能写出好代码,还能理解代码背后的逻辑,能在未来解决维护者都没遇到过的问题。而AI生成的代码,只是一段没有记忆的字符串。
代码会过时,但人会成长。 这或许是开源社区在AI时代最珍贵的坚守——在追求效率的洪流里,依然愿意把时间花在「人」身上,而不是那些看起来完美却没有温度的代码。毕竟,能让开源项目走得更远的,从来不是最快的代码,而是最靠谱的人。