对抗知识焦虑,从看懂这条开始
App 下载
AI的低语与远方的哭声:揭开大型语言模型背后的“代价链”
道德风险|可持续发展|稀土供应链|锂资源|钴矿开采|环境污染|大语言模型|地球环境|人工智能
对抗知识焦虑,从看懂这条开始
App 下载道德风险|可持续发展|稀土供应链|锂资源|钴矿开采|环境污染|大语言模型|地球环境|人工智能
当你在对话框中输入一个简单的问题,大型语言模型(LLM)几乎在瞬间便能生成一段流畅、精准的回答。这看起来就像一次干净、无形的数字魔法。但在这串代码和像素的背后,一条漫长而沉重的“代价链”早已悄然运转,从地球深处延伸到世界的另一端,其背后隐藏的资源、环境与社会成本,正深刻挑战着我们对“可持续发展”与道德底线的认知。
人工智能的旅程并非始于云端,而是始于地壳深处。驱动AI服务器高速运转的芯片,离不开钴、锂、稀土等关键矿物。这些矿物之所以“关键”,不仅因为其稀缺和难以提取,更因为它们是地缘政治的博弈焦点。全球超过70%的钴产自刚果民主共和国,而中国企业控制着其中绝大多数的矿场。美国虽然在稀土开采量上居于次席,却缺乏本土加工能力,高度依赖中国的供应链。
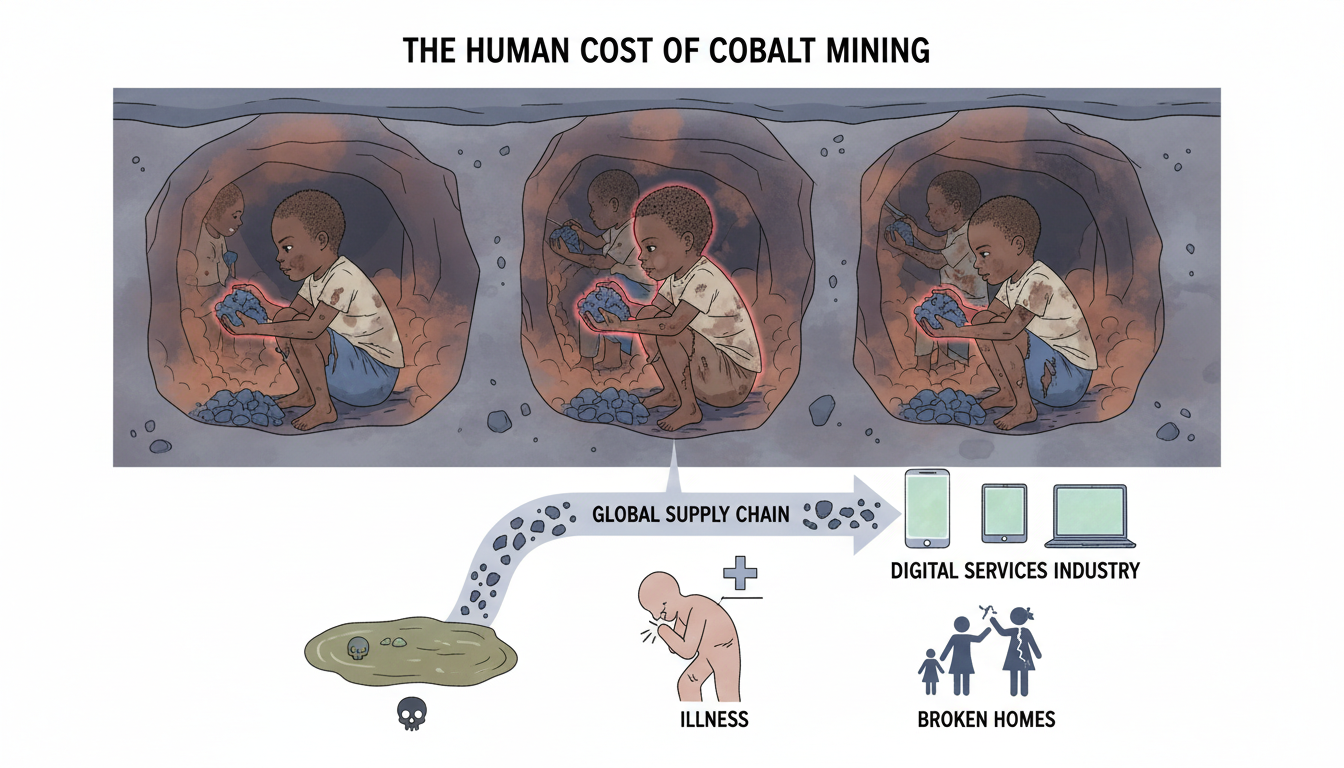
然而,地缘政治的紧张只是冰山一角。更深层的代价,由最脆弱的人群承担。在刚果的钴矿区,“手工采矿”往往是童工的委婉说法。成千上万的儿童,有些甚至不到10岁,用双手在危险的矿洞中挖掘矿石,每天收入不足2美元。他们暴露在充满有毒粉尘的环境中,没有防护,更没有医疗保障。这些沾满血汗的矿石被混入工业开采的洪流,最终进入全球供应链,变得无法追溯。它们支撑起了世界上最赚钱的数字服务产业,却给当地社区留下了被污染的水源、患病的身体和破碎的家庭。
这是一种现代版的“资源诅咒”。财富从本地劳工手中被榨取,用于支撑全球科技巨头的辉煌,而当地社区却再次陷入了资源开采经济特有的“繁荣-萧条”循环,就像历史上的石油或钻石一样,留下的只有被掏空的土地和被剥削的人民。
矿物构成了AI的“骨骼”,而训练数据则是其“灵魂”。为了让大型语言模型能够理解人类语言的复杂性,并过滤掉互联网上充斥的暴力、色情和仇恨言论,它们需要经过海量“已标注”数据的训练。而这项工作,无法由机器完成,必须由人来承担。
这催生了一个庞大的、却几乎隐形的产业——数据标注。在肯尼亚、尼日利亚、印度等劳动力成本低廉的国家,成千上万的“幽灵劳工”在为AI的“净化”付出代价。他们的工作是日复一日地审阅和标记那些最令人不安的内容,从血腥暴力到儿童虐待。这份工作的时薪通常低于2美元,且几乎没有任何劳动保障和心理支持。
这些工人被称为“沉默的训练师”。他们承受着巨大的精神创伤,许多人因此患上严重的心理疾病,但他们的贡献却从未出现在光鲜亮丽的产品发布会上。一位为OpenAI进行数据标注的肯尼亚员工在接受采访时表示,这份工作“是一种折磨”,他时常会因看到的恐怖内容而产生幻觉。讽刺的是,他们正在用自己的精神健康,来确保AI产品对全球数亿用户的“心理安全”。这种建立在全球不平等之上的“情感外包”,揭示了AI光环下深刻的社会不公。
当模型训练完成,真正的资源消耗才刚刚开始。每一次AI查询、每一次图像生成,都需要在巨大的数据中心内调动数千台服务器进行运算。这些数据中心是名副其实的“电老虎”和“水鬼”。

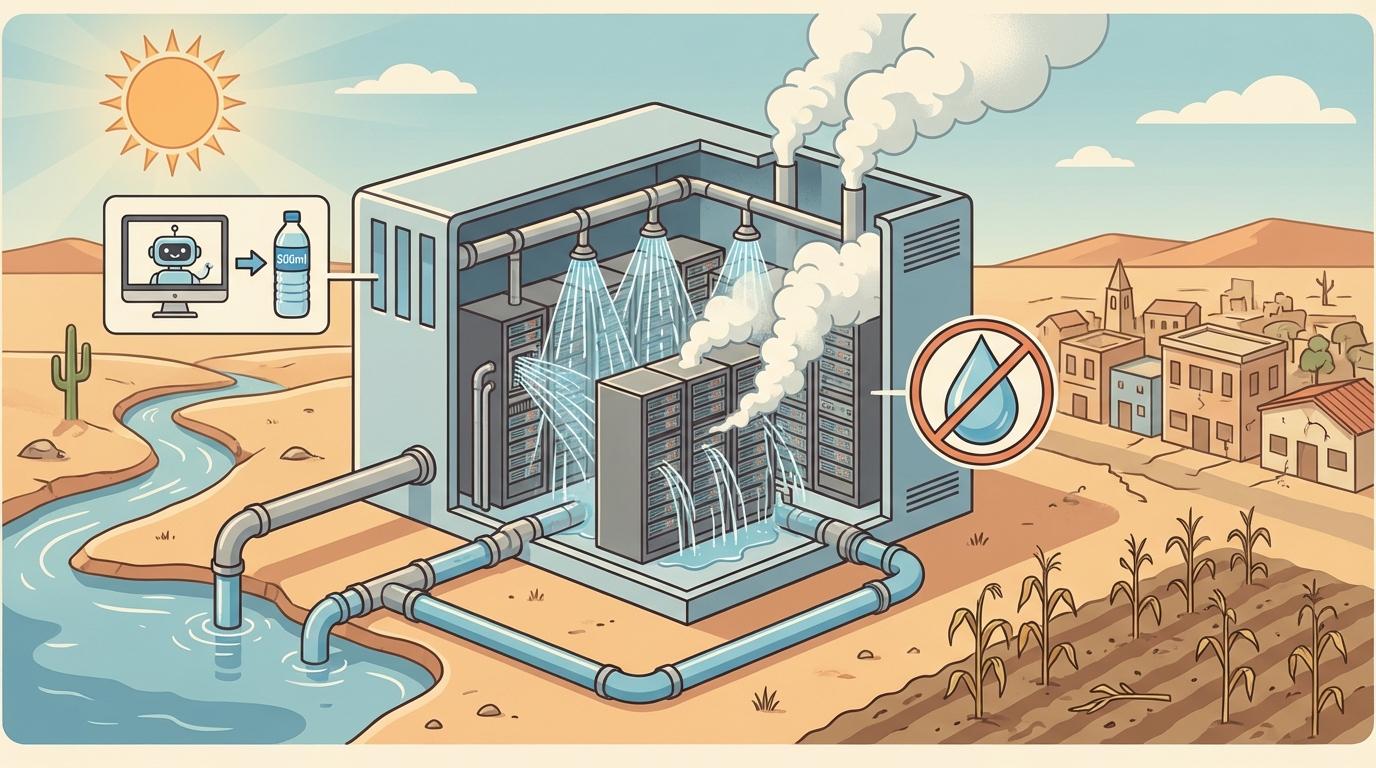
这种对能源和水的无尽渴求,让AI的碳足迹和水足迹变得触目惊心。尽管科技公司纷纷承诺使用清洁能源和实现“水资源正效益”,但通过购买碳信用额度等方式进行的“漂绿”行为也备受诟病。AI需求的爆炸式增长,正在给全球的电网和水资源系统带来前所未有的压力。
大型语言模型的崛起无疑是技术上的巨大飞跃,它在提升效率、加速创新方面展现出巨大潜力。然而,当我们深入其背后那条横跨全球的“代价链”,一个尖锐的伦理问题浮出水面:我们是否愿意为了数字世界的便捷,而默许一个建立在现实世界苦难之上的未来?
从刚果矿洞里儿童沾满尘土的双手,到内罗毕办公室里数据标注员疲惫的双眼,再到亚利桑那州沙漠中被蒸发的水汽,AI的每一个“智能”瞬间,都与这些遥远的场景紧密相连。这不仅仅是技术问题,更是一个关乎公平、正义和人类共同命运的社会议题。
如今,欧盟的《AI法案》开始要求高风险AI系统披露其能源消耗,联合国教科文组织也在倡导更高效、更精简的模型架构。这些努力是迈向负责任AI的第一步,但还远远不够。它需要科技公司承担起超越利润的社会责任,需要政策制定者建立更完善的全球监管框架,更需要我们每一个用户进行反思:
当我们下一次与AI互动时,或许应该意识到,那看似轻巧的点击,其背后承载的重量远超想象。重新审视并定义“可持续的智能”,确保技术进步不会以牺牲地球环境和人类尊严为代价,是我们这个时代必须紧急回答的问题。