
9 天前
9 天前
当你还在为租H100显卡的账单头疼,或是对着硬盘里的TB级训练数据犯愁时,一群开发者已经在MacBook上搞定了多模态大模型的微调——而且是文本、图像、音频全模态覆盖。你不用再把敏感的医疗录音、客户合同上传云端,也不用花几万块买专业GPU工作站,一台搭载M系列芯片的Mac就能完成从数据加载到模型导出的全流程。这不是实验室里的玩具,而是已经能生成符合新闻规范的体育报道、识别工业制造缺陷的实用工具。问题是,这一切怎么做到的?
你可以把预训练大模型想象成一本写满通用知识的百科全书——如果要让它变成一本专注体育报道的专业手册,你不需要重写整本书,只需要在空白处贴满体育相关的便签。LoRA(低秩适配)技术做的就是这件事:冻结大模型的99%以上原始权重,只在注意力层插入几个极小的「低秩矩阵」作为「便签本」,训练时只更新这部分参数。
但真实的机制比这更精确:在Gemma模型的注意力投影矩阵中,LoRA会额外加入两个小矩阵A和B,A负责把高维特征压缩到低维空间,B再把低维特征映射回原空间。整个微调过程,只需要更新这两个小矩阵的参数——对于310亿参数的Gemma 4来说,LoRA只需要训练约1600万个参数,不到总参数的0.05%。
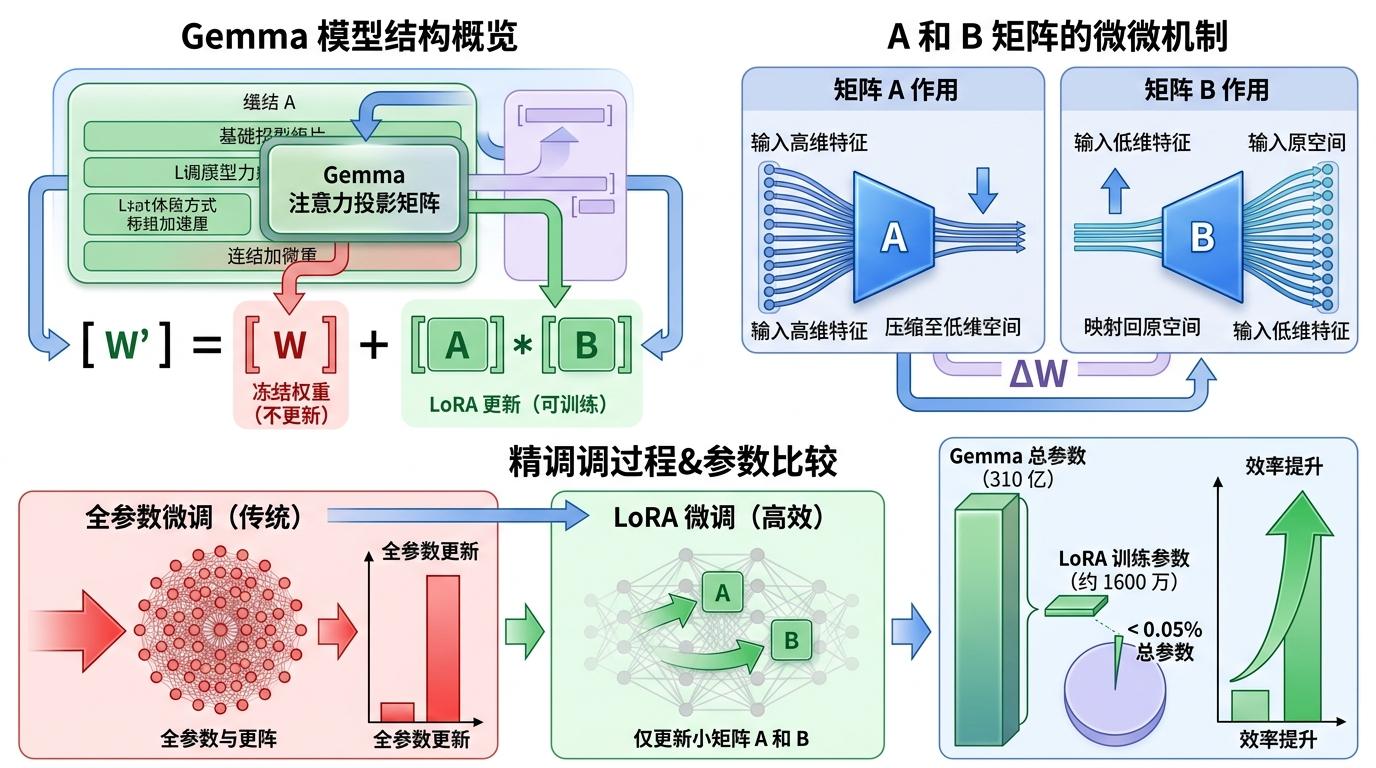
这直接带来了三个改变:一是训练所需的显存从数百GB降到了70多GB,M3 Max就能扛住;二是训练时间从几天压缩到2.5小时;三是不会破坏大模型原本的通用能力,微调后的模型既能写体育报道,也能回答日常问题。
当训练数据达到TB级时,就算是Mac的2TB SSD也装不下——但你其实不需要把所有数据都拷到本地。这个工具的核心巧思之一,是支持从Google Cloud Storage或BigQuery流式加载数据:训练时只拉取当前批次需要的数据块,用完就释放,全程不占用本地存储。
数据流转的路径清晰得像一条流水线:不管是本地CSV里的图像路径、云端存储的医疗录音,还是BigQuery里的客户对话,都会先被转换成统一的多模态聊天模板——文本是直接的token,图像会被切成16×16的patch转换成视觉token,音频会被转成mel谱图再编码成音频token。这些混合token会被喂给模型,训练时只有LoRA的小矩阵在更新,原始模型权重始终躺在统一内存里,不用来回拷贝。

训练完成后,你可以选择把LoRA适配器和原始模型合并成一个完整文件,也可以单独导出适配器——一个只有几十MB的小文件,就能让任何同版本的Gemma模型拥有你定制的能力。当然,这个方案也有局限:目前图像和文本的微调还只支持本地CSV,云端流式加载暂时只适配音频数据。
能在Mac上跑通这一切,Apple Silicon的统一内存架构功不可没——CPU、GPU、神经引擎共享同一块物理内存,数据不用在不同组件之间来回拷贝,直接砍掉了传统PC架构里最大的性能损耗。M3 Max的96GB统一内存,能让模型权重、训练数据、中间结果都待在同一个「房间」里,不用频繁「搬家」。
但这并不意味着苹果芯片是完美的AI训练平台。M系列GPU对内存使用有默认的75%限制,128GB的机器里只有96GB能给GPU用,超出这个限制可能会导致系统不稳定。开发者们的补丁是量化技术:用QLoRA把模型权重量化成4位精度,再结合梯度检查点、混合精度训练,进一步压缩内存占用。比如4位量化后的Gemma 4 31B,推理速度能提升2.6倍,单篇体育报道的生成时间从130秒降到80秒。
还有个容易被忽略的细节:苹果自带的Python版本是3.9,而这个工具需要3.10以上——你得自己装Homebrew的Python,还得用arm64原生版本,不能是Rosetta转译的x86版本,否则MPS加速会完全失效。
当你用Mac完成一次Gemma模型的多模态微调时,你其实正在参与一场悄悄发生的变革:AI的重心正在从云端的超级计算机,转移到每个人手边的设备。这不仅仅是成本的降低,更是数据主权的回归——医疗数据不用再传到第三方服务器,企业的客户对话不用再暴露给云端API,你的AI模型只属于你。
本地AI的未来,从来不是要取代云端,而是要形成一种平衡:复杂的通用计算交给云端,敏感的定制任务留在本地。算力向下走,数据不搬家,这可能是AI真正走进日常的开始。毕竟,最好的AI,应该是那种能在你需要时出现,又能在你不需要时保持沉默的存在——就像你手边的Mac一样。
点击充电,成为大圆镜下一个视频选题!