对抗知识焦虑,从看懂这条开始
App 下载
酶工程告别试错:量子AI+机器人闭环提速500倍
酶突变体|机器人自动验证|AI筛选|量子物理模拟|曼彻斯特初创团队|量子科学|合成生物学|生命科学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载酶突变体|机器人自动验证|AI筛选|量子物理模拟|曼彻斯特初创团队|量子科学|合成生物学|生命科学|数理基础
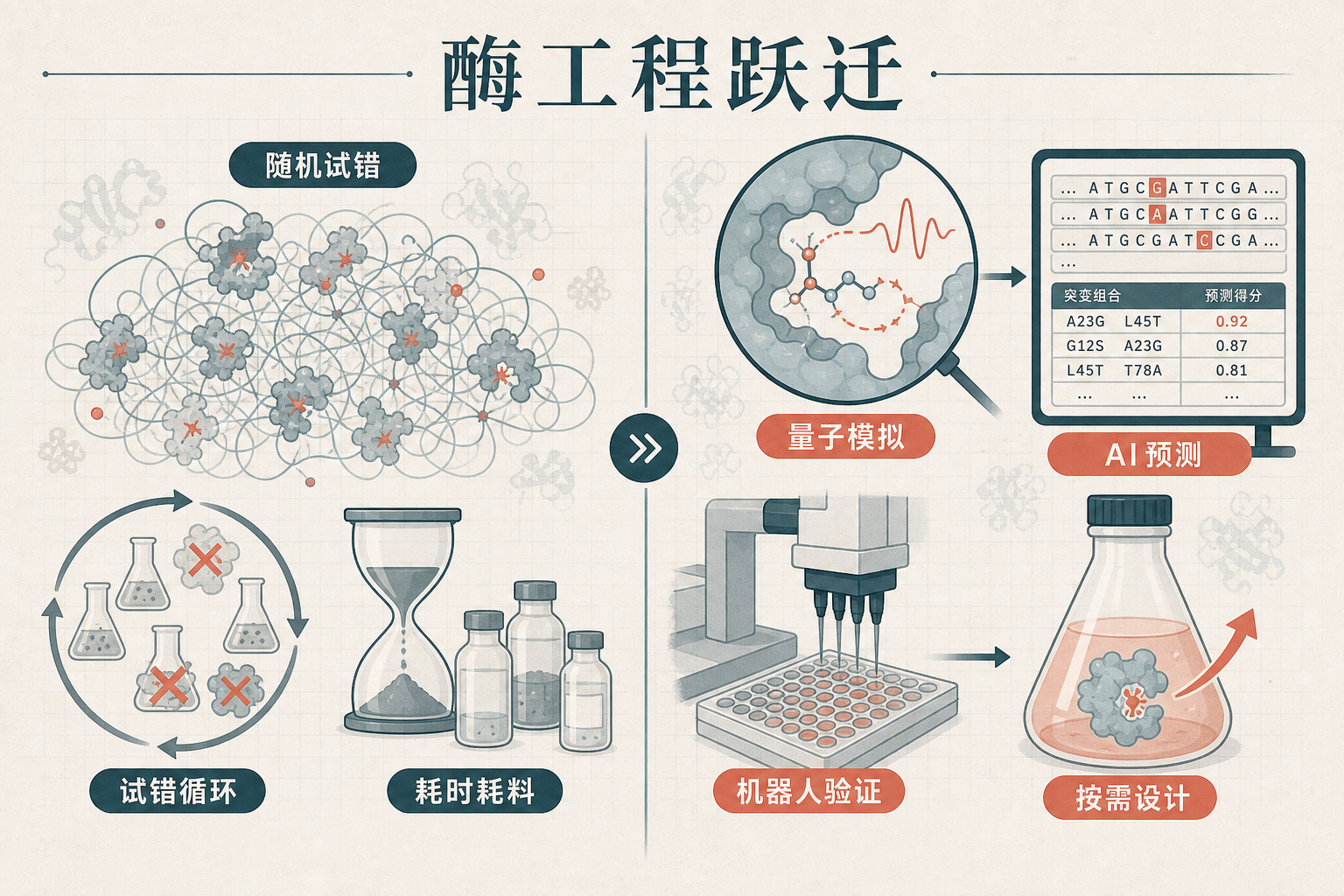
想象一下,在制药厂的实验室里,过去要花几年时间、筛选上百万个酶突变体才能找到的高效催化剂,现在只需要5轮迭代就能让活性提升500倍——这不是科幻,是英国曼彻斯特的初创团队用技术砸开的新大门。他们没有依赖试管里的随机试错,而是在电脑上用量子物理模拟出百万种酶的可能,再用AI挑出最优解,最后让机器人自动验证、把数据喂回AI继续优化。这整套闭环流程,正在把酶工程从靠运气的“盲盒游戏”,变成精准可控的工业流水线。为什么这套组合拳能让研发效率翻几百倍?背后的逻辑藏着整个生物制造行业的未来。
传统酶工程像在大海里捞针——科学家用随机突变制造出海量酶变体,再靠高通量筛选一点点碰运气,99.9%的样本都是无用的“废品”,不仅要消耗数不清的试剂和时间,还经常陷入“进化死胡同”:改来改去,酶的性能就是没法再提升。

而量子物理模拟直接把这根“针”的位置标了出来。你可以把酶想象成一个精密的分子机器,催化反应的核心是活性位点的电子转移、质子隧穿这些量子级别的变化——传统的分子力学模拟只能算出大概的结构,量子模拟却能精准捕捉这些微观细节,预测每一个氨基酸突变会怎么改变酶的活性、稳定性和底物特异性。
这个团队的量子模型能在电脑上同时模拟上百万种酶变体,相当于在虚拟实验室里完成了过去几年的筛选量。更关键的是,它不是瞎猜,而是基于物理规律的精准预测:比如某个氨基酸突变会让活性位点的电场强度改变10%,进而让催化效率提升30倍——这些数据都有量子力学的计算支撑,不是靠统计规律蒙出来的。
量子模拟给出了候选名单,但真正让这套体系跑起来的,是“设计-测试-学习”的闭环自动化。
首先,量子模拟的结果会被喂进定制的AI模型里。这个AI不是通用的蛋白质模型,而是专门针对酶工程训练的——它能从量子数据里学习到“什么样的突变组合能提升催化效率”,然后进一步优化候选变体,把百万级的名单压缩到几十甚至几个最有潜力的目标。
接下来是机器人登场。自动化实验室里的液体处理机器人会自动完成基因合成、蛋白表达、酶活性检测全流程,全程不需要人工干预,一天就能完成上百个样本的验证。更重要的是,实验数据会直接反馈回AI模型:某个变体的活性比预测低了20%?AI会立刻调整自己的算法,修正预测偏差,下一轮设计就会更精准。
这个闭环是关键。过去的AI模型经常“纸上谈兵”,预测的性能和实际实验结果差得远,但在这里,AI每一轮都在接受真实实验的“考核”,就像一个不断刷题的学生,准确率会越来越高。有数据显示,经过3轮闭环迭代后,AI的预测准确率能从最初的60%提升到90%以上。
当然,这套体系也不是完美的。量子模拟的计算成本依然很高,目前还只能模拟中小型酶;机器人自动化实验室的初期投入也不菲,不是所有小团队都能负担;而且对于一些极端环境下的酶(比如高温、强酸碱),量子模拟的预测精度还有待提升。
酶是生物制造的“核心引擎”——从制药里的药物合成,到食品里的淀粉糖化,再到生物燃料里的生物质降解,几乎所有绿色工业流程都离不开它。酶的效率提升一点点,整个产业链的成本和能耗就能降一大截。
比如在制药行业,用高效酶替代传统化学催化剂,能把反应步骤从10步缩减到3步,减少90%的有机溶剂使用,同时把产率从30%提升到95%——这不仅能降低药物的生产成本,还能大幅减少污染。在生物燃料领域,更高效的糖化酶能让玉米秸秆的转化率提升20%,直接降低生物乙醇的价格,让它能和化石燃料竞争。
现在,这个赛道已经挤满了玩家:有的专注AI生成酶序列,有的主打自动化筛选,而曼彻斯特的这个团队靠量子模拟+闭环自动化打出了差异化。但不管路线如何,它们的目标都是同一个:把酶工程从“靠天吃饭”的手艺活,变成标准化、可复制的工业技术。
当量子物理的微观计算、AI的智能预测和机器人的精准执行拧成一股绳,酶工程终于跳出了“试错循环”的怪圈。这不仅仅是研发效率的提升,更是整个生物制造行业的逻辑转变——从“自然给什么用什么”,到“我们需要什么就设计什么”。
未来,也许我们能为每一种工业场景定制专属的酶:能在零下20度工作的低温酶,能降解塑料的环保酶,能精准催化罕见病药物的特种酶。而这一切的起点,就是把实验室的试错权,交给了计算和数据。
用计算精准设计,让生物制造可控。