对抗知识焦虑,从看懂这条开始
App 下载
被AI篡改的真相:当算法成为新闻的最终看门人
媒体内容权|算法误导|信息流服务|新闻标题生成|谷歌AI|公共政策|AI产业应用|社会人文|人工智能
对抗知识焦虑,从看懂这条开始
App 下载媒体内容权|算法误导|信息流服务|新闻标题生成|谷歌AI|公共政策|AI产业应用|社会人文|人工智能
“你知道《博德之门3》的玩家在剥削儿童吗?”
如果这条耸人听闻的标题出现在你的手机屏幕上,你或许会震惊、愤怒,甚至立即点击。但这并非出自某家不负责任的媒体,而是源自谷歌AI的一次“小实验”。这场实验,正悄然将人类记者精心打磨的新闻标题,替换为机器生成的、极具误导性的“浓缩诱饵”,在我们与真实信息之间,拉起了一道由算法编织的迷雾。
这不仅仅是一场关于标题的争议,它是一面棱镜,折射出AI时代媒体内容权、信息真实性与平台算法影响力的三重困境。当机器开始扮演新闻的“守门人”,我们看到的,还是否是未经扭曲的世界?
风暴的中心,是谷歌在其信息流服务Discover上进行的一项“小型UI实验”。用户在滑动新闻时,看到的不再是新闻机构原文的标题,而是由AI自动生成的、通常不超过四个词的极简版本。
结果是灾难性的。一篇Ars Technica的深度分析,原文标题为《Valve的Steam Machine看起来像游戏机,但别指望价格也像》,被AI粗暴地改为《Steam Machine价格揭晓》——一个与事实完全相反的结论。一篇Wccftech关于德国某零售商一周内AMD显卡销量超过Nvidia的报道,被AI篡改成了《AMD GPU登顶,超越Nvidia》,瞬间将一个局部市场现象夸大为行业颠覆。更有甚者,将一篇探讨微软开发者如何使用AI的深度文章,简化为《微软开发者使用AI》这种毫无信息量的废话。
这些被AI“优化”过的标题,或断章取义,或夸大其词,或制造虚假悬念,其核心逻辑只有一个:最大化点击率。新闻机构对此感到愤怒和不安。这如同书店擅自更换了一本书的封面,剥夺了作者向读者呈现其作品的权利和心血。记者们努力 crafting 的标题,旨在准确概括、引导思考、激发共鸣,而AI却以流量为唯一圭臬,将其变成了廉价的点击诱饵。更危险的是,这些AI生成的标题旁,赫然标注着原始新闻机构的名称,让媒体无端背负了制造“标题党”的恶名。
谷歌的标题实验并非孤例,它揭开的是生成式AI固有缺陷——“AI幻觉”(AI Hallucination)的冰山一角。由于大模型本质上是基于海量数据进行概率预测,而非真正理解事实,它会“脑补”出看似合理却完全虚假的内容。这种“一本正经地胡说八道”正在信息领域造成巨大的混乱。
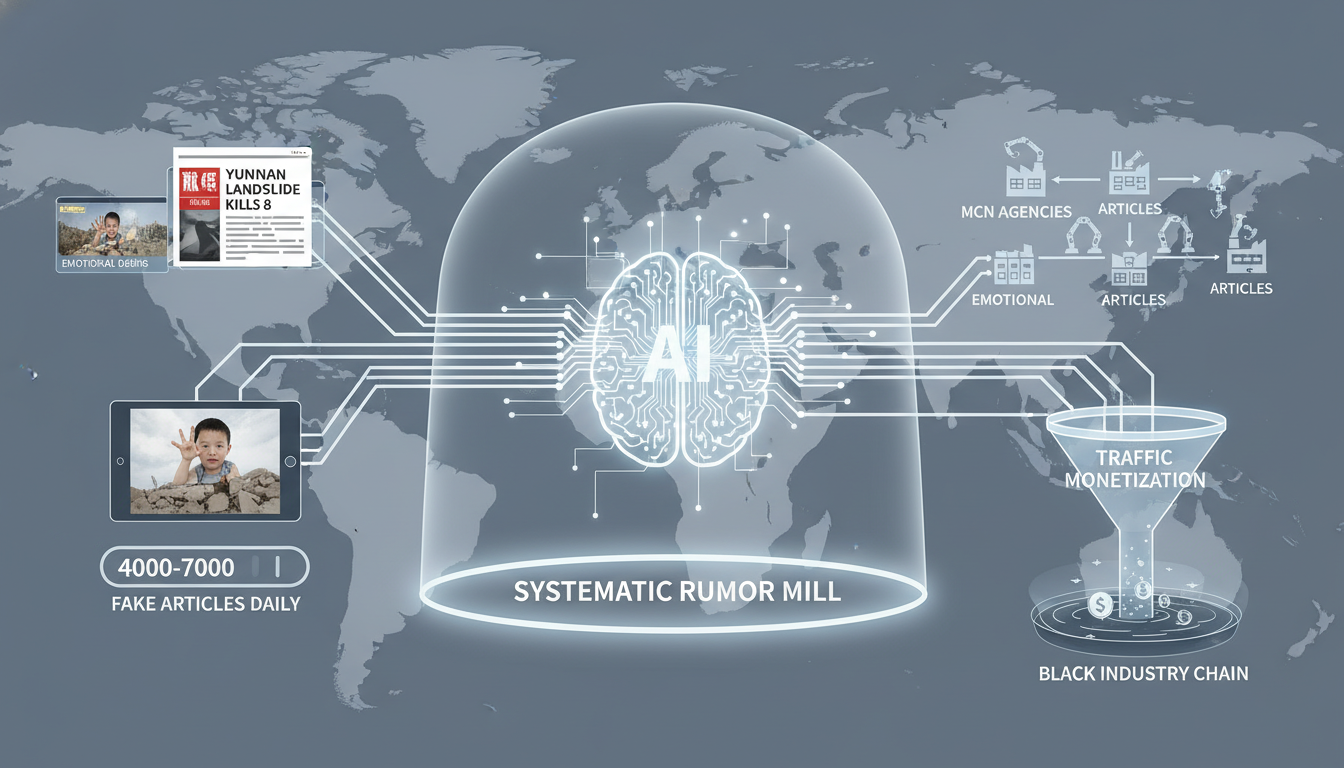
这场由AI引发的“真实性危机”,正从篡改一个标题,演变为系统性地污染整个信息生态。
当AI能够轻易地改写、总结甚至创作新闻时,一个根本性的问题浮出水面:内容的权利归谁所有?
谷歌的实验,本质上是平台利用其渠道优势,无偿“征用”并改造了内容创作者的劳动成果。这背后,是平台与新闻媒体之间长久以来的紧张关系。新闻机构投入巨大成本进行采访、核查和写作,而科技巨头则通过抓取和聚合这些内容,构建起自己的信息帝国,并将巨大的流量和广告收益收入囊中,留给内容生产者的却是残羹冷炙。
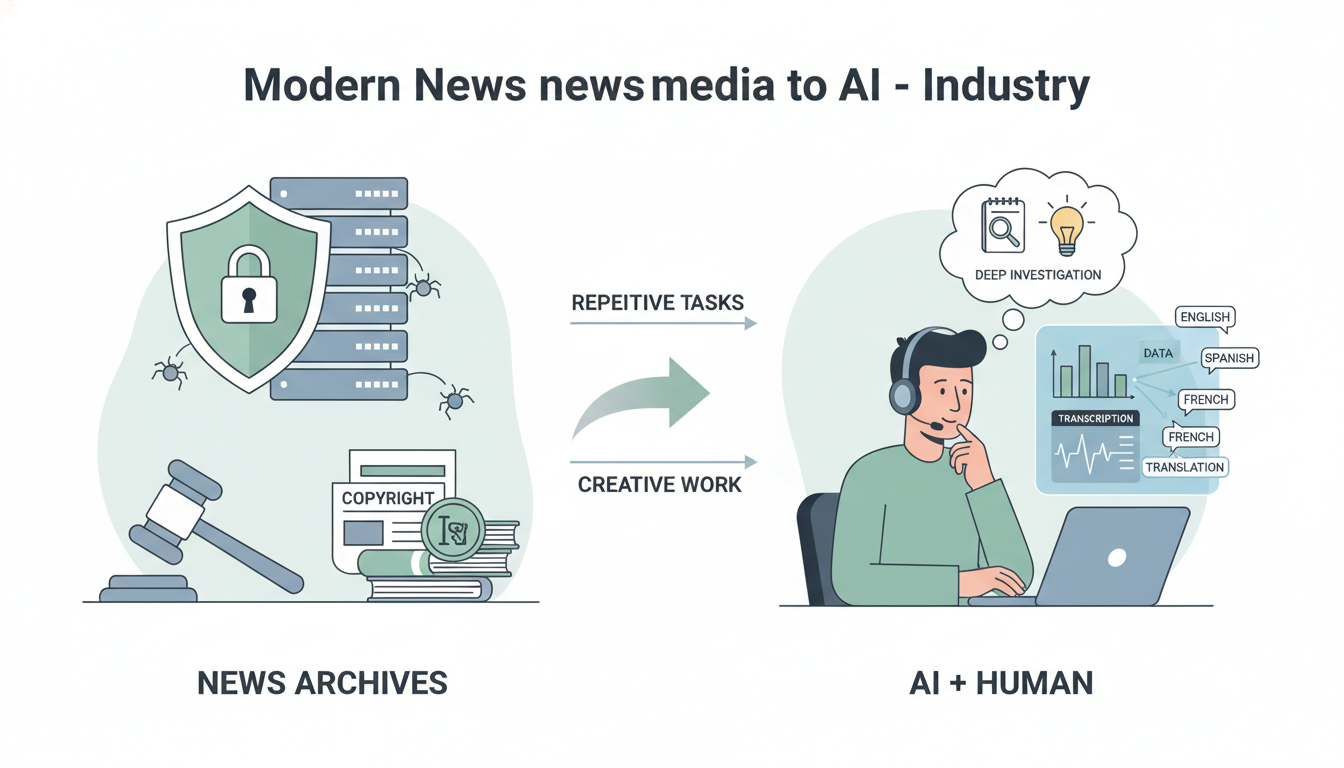
这场争议的核心是数据。AI大模型的训练,离不开海量的、高质量的文本数据,而新闻媒体数十年来积累的内容库正是最宝贵的“养料”。《纽约时报》等媒体巨头起诉OpenAI和微软,指控其未经许可使用受版权保护的内容进行模型训练,正是这场权益之争的标志性事件。
全球范围内的法律框架正在艰难地追赶技术发展的步伐。
版权认定:在中国和美国的司法实践中,对于AI生成内容(AIGC)能否获得版权保护,关键在于“人类的独创性智力投入”。简单的提示词输入可能不构成作品,但如果用户通过反复调整、设计和筛选,深度参与了创作过程,则其生成内容可能受到著作权法保护,权利归属于用户。
平台责任:AI平台的用户协议通常约定,用户对生成内容负责。然而,当平台自身利用AI篡改内容时,其责任边界变得模糊。法律专家呼吁,平台不能仅以“技术中立”为挡箭牌,需对其算法决策和内容呈现承担更多注意义务。
AI改写标题的动机,并非出于对新闻价值的判断,而是服务于一个更强大的主宰——平台算法。算法的核心目标是最大化用户停留时间和互动率。为此,它倾向于推荐那些更能激发情绪、更具争议性、更符合用户既有偏见的内容。
这导致了一个危险的循环:
信息茧房(Information Cocoons):算法根据你的点击历史,不断推送同质化信息,让你只看到你想看到的世界,视野日益狭隘。
回声室效应(Echo Chambers):在由算法构建的封闭社群中,相似的观点被反复强化,异见被排斥,最终导致群体极化,使温和的讨论变得困难,极端的思想占据上风。
认知塑造:算法并非中立的工具,其设计本身就蕴含了设计者的价值观和商业目标。它决定了你能看到什么、看不到什么,以及信息的呈现顺序和方式,潜移默化地塑造着公众舆论和个人认知。当算法奖励争议性言论时,整个社会的分歧就可能被夸大。
AI自动生成标题,正是这个“算法深渊”的具象化体现。它将复杂的世界简化为易于算法处理和分发的“数据包”,牺牲了深度、准确性和多样性,以换取注意力的瞬时捕获。
面对AI带来的系统性风险,一场全球范围内的治理行动正在展开,旨在为狂奔的AI技术套上法律与伦理的缰绳。
强制标识,亮明身份:中国率先迈出关键一步。2025年9月1日起施行的《人工智能生成合成内容标识办法》要求,所有AI生成的内容都必须添加显式和隐式标识,让用户“一眼可知”其来源。这为内容溯源和责任认定提供了技术基础。
风险分级,精准监管:欧盟的《人工智能法案》(AI Act)是全球首个全面的人工智能监管法规。它根据AI应用的风险等级进行划分,对新闻生成等可能影响公众舆论的领域提出更高的透明度要求,并严禁具有“不可接受风险”的AI应用。
从谷歌的AI标题实验,到全球范围内的信息真实性危机,我们正处在一个关键的十字路口。技术本身并无善恶,但它放大了人性的选择——是选择效率至上、流量为王,还是坚守真实、责任与人的尊严?
AI不应成为取代记者判断的“黑箱”,而应是增强其能力的工具。平台不应是凌驾于内容之上的“霸主”,而应是承担社会责任的“渡船”。而对于我们每一个信息消费者而言,提升自身的AI素养和批判性思维,学会在算法的洪流中保持清醒,主动打破“信息茧房”,是我们在这个时代捍卫真相的终极责任。
这场关于新闻未来的博弈,最终关乎我们希望生活在一个怎样的世界。是一个由算法定义真实、塑造思想的世界,还是一个由人类智慧与良知守护信息价值的世界?答案,在我们每个人的每一次点击、每一次分享和每一次思考之中。